【我遇到的问题】 • 现象:该数据集的下载链接已失效 【相关信息】 • 可考虑访问这个链接获取类似文件~https://www.selectdataset.com/dataset/3688356173feccbcf1f1e490ddc6bc72
ShengbinYue/DISC-Law-SFT
收藏Hugging Face2025-05-22 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/ShengbinYue/DISC-Law-SFT
下载链接
链接失效反馈官方服务:
资源简介:
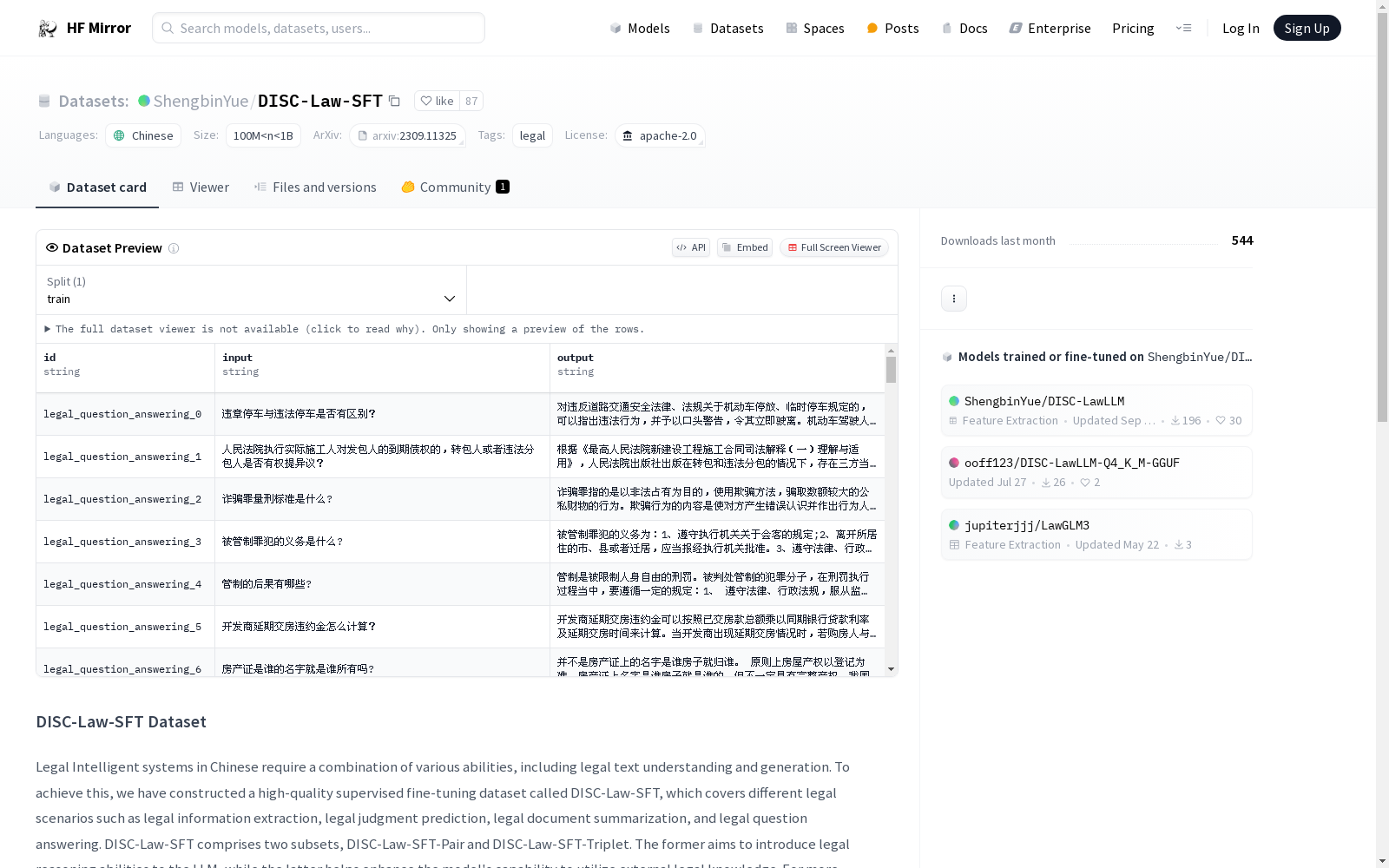
DISC-Law-SFT数据集是一个高质量的中文法律监督微调数据集,旨在提升法律智能系统的能力,包括法律文本的理解和生成。该数据集包含两个子集:DISC-Law-SFT-Pair和DISC-Law-SFT-Triplet,分别用于引入法律推理能力和增强模型利用外部法律知识的能力。数据集涵盖了多种法律场景,如法律信息提取、法律判决预测、法律文档摘要和法律问答等。具体任务包括法律信息提取、法律事件检测、法律案件分类、法律判决预测、法律案件匹配、法律文本摘要、司法舆情摘要、法律问答、法律阅读理解和司法考试等。数据集总规模为403K,适用于法律专业助理、法律咨询服务和司法考试助理等场景。
The DISC-Law-SFT dataset is a high-quality Chinese legal supervised fine-tuning dataset designed to enhance the capabilities of legal intelligent systems, including legal text understanding and generation. The dataset comprises two subsets: DISC-Law-SFT-Pair and DISC-Law-SFT-Triplet, which are respectively used to equip models with legal reasoning capabilities and improve their ability to leverage external legal knowledge. The dataset covers a variety of legal scenarios, such as legal information extraction, legal judgment prediction, legal document summarization, legal question answering and more. Its specific tasks include legal information extraction, legal event detection, legal case classification, legal judgment prediction, legal case matching, legal text summarization, judicial public opinion summarization, legal question answering, legal reading comprehension and judicial examination. The total size of the dataset is 403K, and it is suitable for scenarios including legal professional assistants, legal consultation services, judicial examination assistants and other related application scenarios.
提供机构:
ShengbinYue
原始信息汇总
DISC-Law-SFT Dataset 概述
数据集基本信息
- 名称: DISC-Law-SFT Dataset
- 语言: 中文
- 标签: 法律
- 大小: 100M<n<1B
- 许可证: Apache-2.0
数据集内容
DISC-Law-SFT 数据集包含两个主要子集:
1. DISC-Law-SFT-Pair
- 目的: 引入法律推理能力
- 任务与大小:
- 法律信息提取: 32K
- 法律事件检测: 27K
- 法律案例分类: 20K
- 法律判决预测: 11K
- 法律案例匹配: 8K
- 法律文本摘要: 9K
- 司法舆论摘要: 6K
- 法律问答: 93K
- 法律阅读理解: 38K
- 司法考试: 12K
2. DISC-Law-SFT-Triplet
- 目的: 增强模型利用外部法律知识的能力
- 任务与大小:
- 法律判决预测: 16K
- 法律问答: 23K
通用部分
- 任务与大小:
- Alpaca-GPT4: 48K
- Firefly: 60K
数据集总大小
- 总计: 403K
数据集开放情况
- 状态: 大部分已开源
搜集汇总
数据集介绍
构建方式
在构建DISC-Law-SFT数据集时,研究团队精心设计了两个子集:DISC-Law-SFT-Pair和DISC-Law-SFT-Triplet。前者旨在提升大语言模型(LLM)的法律推理能力,后者则侧重于增强模型利用外部法律知识的能力。数据集涵盖了多种法律场景,包括法律信息提取、法律事件检测、法律案例分类、法律判决预测、法律案例匹配、法律文本摘要、司法舆情摘要、法律问答、法律阅读理解和司法考试等。通过这些多样化的任务,数据集全面覆盖了法律智能系统所需的各种能力。
使用方法
DISC-Law-SFT数据集适用于多种法律智能系统的开发和优化。研究者和开发者可以利用该数据集进行监督微调,以提升模型在法律文本理解、生成和推理方面的能力。具体使用时,可以根据不同的任务需求选择相应的子集进行训练和评估。此外,数据集的开源特性也使得其广泛适用于学术研究和实际应用中,为法律智能领域的发展提供了坚实的基础。
背景与挑战
背景概述
随着法律智能系统的快速发展,中文法律文本的理解与生成能力成为关键。为应对这一需求,DISC-Law-SFT数据集应运而生,由Shengbin Yue及其团队于近期构建。该数据集旨在通过高质量的监督微调,提升法律文本处理能力,涵盖法律信息提取、法律判决预测、法律文书摘要生成及法律问答等多个法律场景。DISC-Law-SFT数据集分为DISC-Law-SFT-Pair和DISC-Law-SFT-Triplet两个子集,分别侧重于法律推理能力的引入和外部法律知识的利用。这一数据集的构建不仅填补了中文法律智能领域的数据空白,也为相关研究提供了坚实的基础。
当前挑战
DISC-Law-SFT数据集在构建过程中面临多重挑战。首先,法律文本的复杂性和专业性要求数据集具备高度的准确性和专业性,这对数据标注和处理提出了极高的要求。其次,法律场景的多样性使得数据集需要覆盖广泛的法律任务,如法律信息提取、法律判决预测等,这增加了数据集的构建难度。此外,如何有效整合外部法律知识以提升模型的推理能力,也是该数据集面临的重要挑战。最后,数据集的规模和多样性要求在确保质量的同时,还需兼顾数据的平衡性和代表性,以支持不同法律任务的训练需求。
常用场景
经典使用场景
在法律智能系统中,DISC-Law-SFT数据集的经典使用场景主要集中在法律文本理解和生成能力的提升。该数据集通过涵盖法律信息提取、法律判决预测、法律文档摘要和法律问答等多种任务,为法律专业助理和司法考试助理提供了丰富的训练资源。例如,在法律信息提取任务中,模型能够从复杂的法律文书中提取关键信息,从而辅助法律从业者进行案件分析和判决预测。
解决学术问题
DISC-Law-SFT数据集解决了法律领域中多个重要的学术研究问题。首先,它通过提供高质量的法律文本数据,促进了法律文本理解和生成技术的研究。其次,数据集中的法律判决预测任务有助于研究法律推理和预测模型的构建,这对于提高司法决策的准确性和效率具有重要意义。此外,法律问答和阅读理解任务的引入,为法律知识图谱和自然语言处理技术的结合提供了新的研究方向。
实际应用
在实际应用中,DISC-Law-SFT数据集被广泛用于构建智能法律咨询服务和司法辅助系统。例如,在法律咨询服务中,通过法律问答任务的训练,模型能够快速准确地回答用户的法律问题,提供专业的法律建议。在司法考试辅助系统中,法律阅读理解和司法考试任务的训练,使得模型能够帮助考生进行法律知识的复习和模拟考试,提高考试通过率。
数据集最近研究
最新研究方向
在法律智能系统领域,DISC-Law-SFT数据集的最新研究方向主要集中在提升法律文本理解和生成的能力上。该数据集通过构建高质量的监督微调数据,涵盖了法律信息提取、法律判决预测、法律文档摘要和法律问答等多种法律场景,旨在增强大型语言模型(LLM)在法律领域的应用能力。特别是,DISC-Law-SFT-Pair子集专注于引入法律推理能力,而DISC-Law-SFT-Triplet子集则致力于提升模型利用外部法律知识的能力。这些研究不仅推动了法律智能系统的发展,也为法律专业助理和法律咨询服务提供了新的技术支持。
以上内容由遇见数据集搜集并总结生成


