OpenAssistant/oasst1
收藏Hugging Face2023-05-02 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/OpenAssistant/oasst1
下载链接
链接失效反馈资源简介:
OpenAssistant Conversations数据集(OASST1)是一个由人类生成和标注的助手风格对话语料库,包含161,443条消息,涉及35种不同语言,并包含461,292条质量评分,形成了超过10,000个完全标注的对话树。该数据集是全球超过13,500名志愿者通过众包方式生成的。数据集的主要结构是消息树,每条消息树以一个初始提示消息为根节点,可以有多个子消息作为回复,这些子消息也可以有多个回复。每条消息都有一个角色属性,可以是“assistant”或“prompter”。数据集还提供了JSON格式的消息和对话树示例,并详细说明了如何使用Huggingface Datasets加载数据集。
The OpenAssistant Conversations Dataset (OASST1) is a human-generated and human-annotated assistant-style conversational corpus, containing 161,443 messages across 35 distinct languages, alongside 461,292 quality ratings, forming more than 10,000 fully annotated conversation trees. This dataset was crowdsourced by over 13,500 volunteers worldwide. The primary structure of the dataset is message trees, where each tree takes an initial prompt message as its root node and may have multiple child messages as replies, which can in turn have their own multiple replies. Each message has a role attribute, which can be either "assistant" or "prompter". The dataset also provides JSON-formatted examples of messages and conversation trees, along with detailed instructions on how to load the dataset using Hugging Face Datasets.
提供机构:
OpenAssistant
原始信息汇总
数据集概述
数据集名称: OpenAssistant Conversations (OASST1)
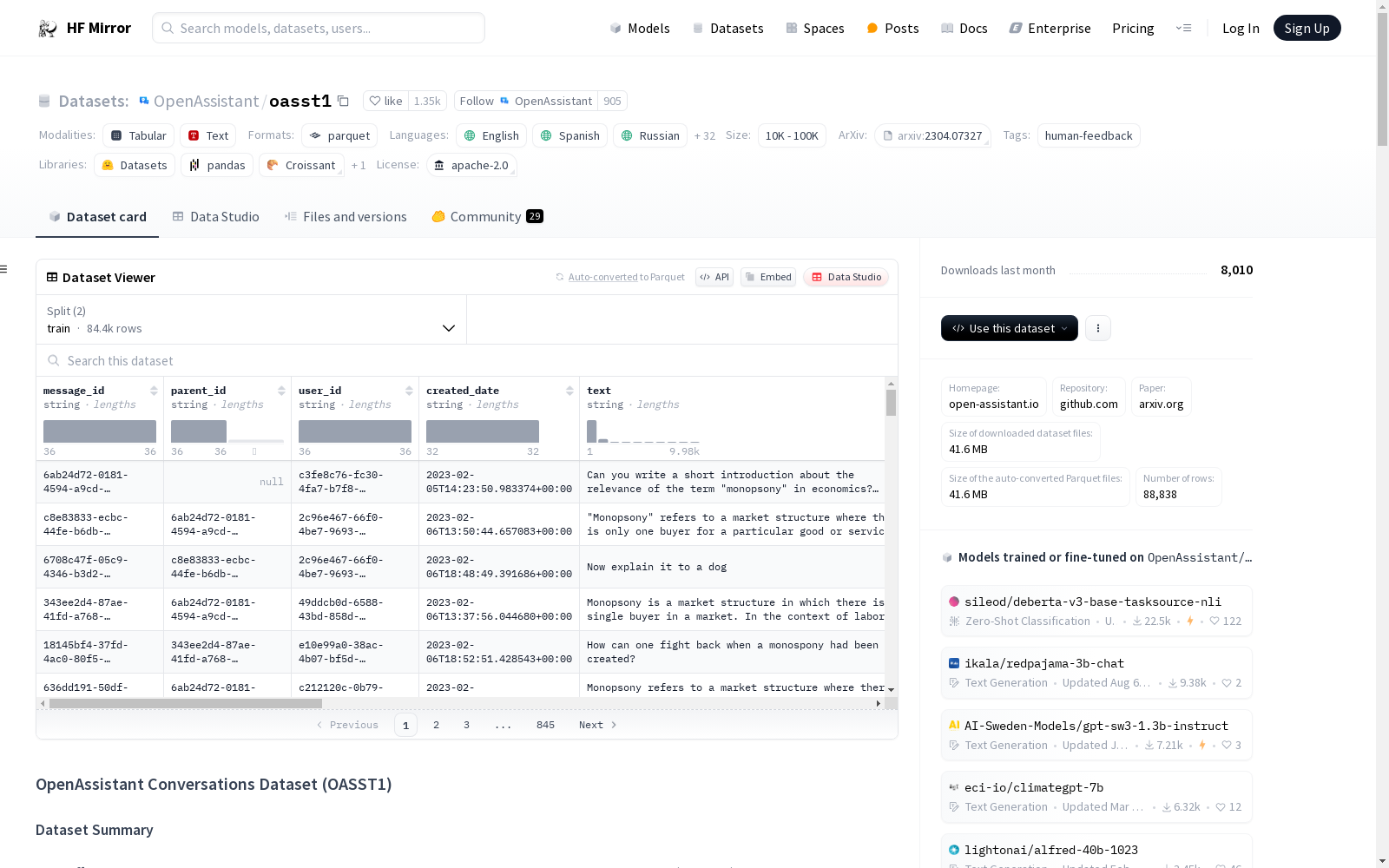
数据集内容: 包含161,443条消息,涉及35种语言,共有461,292个质量评分,形成超过10,000个完全注释的对话树。
数据集结构: 数据集包含消息树,每个消息树以初始提示消息为根节点,可以有多条回复消息作为子节点,子节点也可以有多个回复。
消息属性:
- message_id: 字符串
- parent_id: 字符串
- user_id: 字符串
- created_date: 字符串
- text: 字符串
- role: 字符串("assistant" 或 "prompter")
- lang: 字符串
- review_count: int32
- review_result: bool
- deleted: bool
- rank: int32
- synthetic: bool
- model_name: 字符串
- detoxify: 结构体,包含多种毒性评估指标
- message_tree_id: 字符串
- tree_state: 字符串
- emojis: 序列,包含名称和计数
- labels: 序列,包含名称、值和计数
数据集分割:
- 训练集(train): 84,437条消息,占用100,367,999字节
- 验证集(validation): 4,401条消息,占用5,243,405字节
数据集大小:
- 下载大小: 41,596,430字节
- 数据集大小: 105,611,404字节
支持语言: 包括但不限于英语、西班牙语、俄语、德语、波兰语、泰语等35种语言。
数据集文件:
- 准备导出的树: 10,364棵树,包含88,838条消息
- 所有树: 66,497棵树,包含161,443条消息
- 补充导出:垃圾邮件与提示: 包含被删除或评价结果为负的消息
使用Huggingface数据集: 数据集支持通过Huggingface Datasets加载,适用于训练和验证集的加载。
数据集使用
数据集可通过Huggingface Datasets加载,支持训练和验证集的直接加载。数据集中的消息以深度优先顺序排列,可通过parent_id和message_id重建对话树结构。
搜集汇总
数据集介绍
构建方式
OpenAssistant/oasst1数据集是一个由全球超过13,500名志愿者参与构建的对话语料库,包含35种语言的161,443条由人类生成并注释的对话信息。该数据集通过众包的方式收集,每个对话树以一个初始提示信息为根节点,下面可以有多个回复信息作为子节点,这些子节点又可以有多个回复,形成一个多层次的对话结构。数据集中的每条信息都被标注了角色(提问者或助手),并附有包括语言、创建日期、是否为垃圾信息、毒性评分等多种属性,以及质量评价标签。
特点
该数据集的特点在于其多语言覆盖广,包含35种语言,且对话树结构丰富,每个对话树的初始提示和回复交替进行,形成了完整的对话场景。此外,数据集还提供了详细的评价标签和毒性评分,有助于对对话质量进行深入分析。数据集分为训练集和验证集,方便不同阶段的模型训练和评估。
使用方法
使用该数据集时,可以通过Huggingface的Datasets库直接加载训练集和验证集。若需使用完整的对话树结构,可以通过解析消息中的parent_id和message_id属性来重建对话树。此外,数据集还提供了方便的JSON格式文件,可以通过Python代码进行读取和写入操作,用户可以根据具体需求选择不同的数据文件进行研究和开发。
背景与挑战
背景概述
OpenAssistant Conversations(OASST1)数据集是由LAION-AI组织于2023年发布的一个大规模的人类生成、人类注释的对话语料库。该数据集包含35种语言的161,443条消息,经过461,292次质量评分,形成了超过10,000个完整的对话树。这个语料库是全球范围内超过13,500名志愿者共同努力的成果,旨在推动大规模对齐研究的发展,并促进相关技术的民主化。
当前挑战
该数据集在构建过程中遇到的挑战主要包括如何确保对话的质量和多样性,以及如何有效地处理和整合来自不同语言和文化背景的数据。此外,在研究领域中,如何利用该数据集进行有效的对话系统训练和评估,以及如何处理对话中的敏感内容和毒性问题,也是当前面临的挑战。
常用场景
经典使用场景
OpenAssistant/oasst1数据集作为一个人工智能助手风格的对话语料库,其经典使用场景在于自然语言处理领域,尤其是对话系统的构建与优化。研究人员可以利用该数据集进行对话生成模型的训练,以提高模型对多轮对话的理解与响应能力,进而提升用户交互体验。
实际应用
在实际应用中,OpenAssistant/oasst1数据集可以被用于开发智能客服系统、聊天机器人以及语音助手等,以提升这些系统的自然语言理解和交互能力,从而提高服务效率和用户满意度。
衍生相关工作
基于OpenAssistant/oasst1数据集,衍生出了多项相关工作,包括对话系统的性能评估、多语言对话模型的构建、对话生成策略的研究等,这些工作进一步推动了自然语言处理领域的发展,并促进了人工智能技术的应用普及。
以上内容由遇见数据集搜集并总结生成


