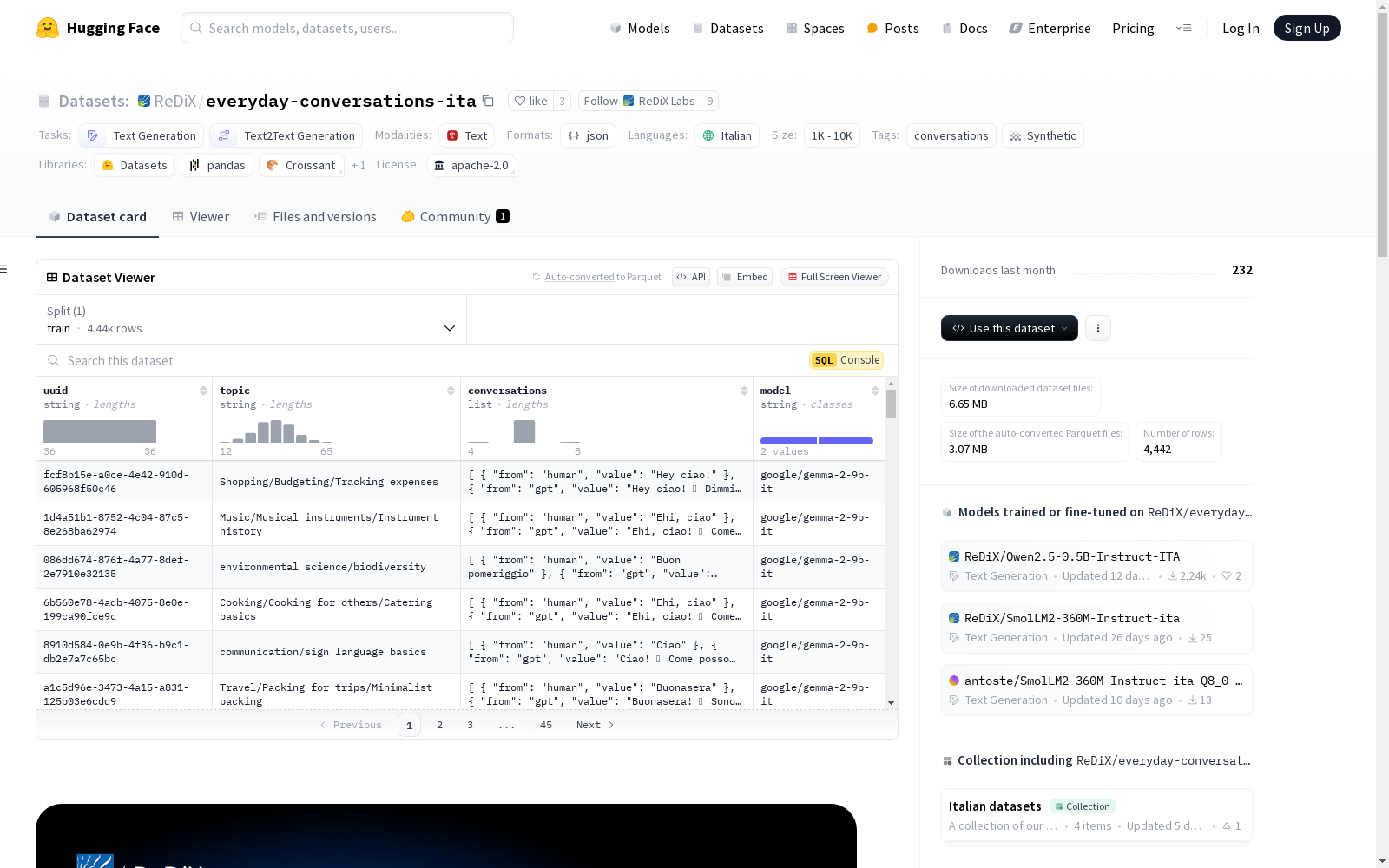
everyday-conversations-ita
收藏Everyday Italian Conversations
概述
- 许可证: Apache 2.0
- 任务类别:
- 文本生成
- 文本到文本生成
- 语言: 意大利语
- 标签:
- 对话
- 合成数据
- 名称: Everyday Italian Conversations
- 数据量: 1K<n<10K
生成过程
-
生成提示:
生成一个非常简单的多轮意大利语对话,涉及{TOPIC_VARIABLE}和儿童发展。对话应以“Ciao!”或“Buongiorno”等基本问候语开始,并保持简单直接。包含5-6个简短的交流。AI应给出简短、清晰的回答。用户应提出简单的问题。对话必须以意大利语进行,用户对话以随机的非正式问候语开始。格式化响应为JSON对象,如下所示: { "conv": [ { "role": "user", "content": "..."}, { "role": "assistant", "content": "..."}, ... { "role": "assistant", "content": "..."} ] }
-
生成模型:
- Qwen/Qwen2.5-7B-Instruct
- google/gemma-2-9b-it
数据集个性化
- 聊天模板: sharegpt
- 系统提示: 未添加,但可以通过指定聊天机器人的名称并修改前两次交互来个性化聊天机器人的交互。
示例
json "messages": [ { "role": "system", "content": "Sei un assistente AI intelligente di nome "{NAME}"" }, { "role": "user", "content": "Ciao!" //oppure "Ciao, chi sei?" }, { "role": "assistant", "content": "Ciao il mio nome è {NAME}! Come posso aiutarti oggi?" }, { "role": "user", "content": "Ho bisogno di tenere traccia delle mie spese" }, { "role": "assistant", "content": "Per tenere traccia delle tue spese, puoi usare un block-notes o un foglio di calcolo per registrare ogni spesa." }, { "role": "user", "content": "Come faccio a stabilire un budget?" }, { "role": "assistant", "content": "Per stabilire un budget, elenca tutte le tue entrate e uscite mensili, poi assegna limiti alle tue spese dividendole per categoria." } ]