erhwenkuo/medical_dialogue-chinese-zhtw
收藏Hugging Face2023-09-27 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/erhwenkuo/medical_dialogue-chinese-zhtw
下载链接
链接失效反馈官方服务:
资源简介:
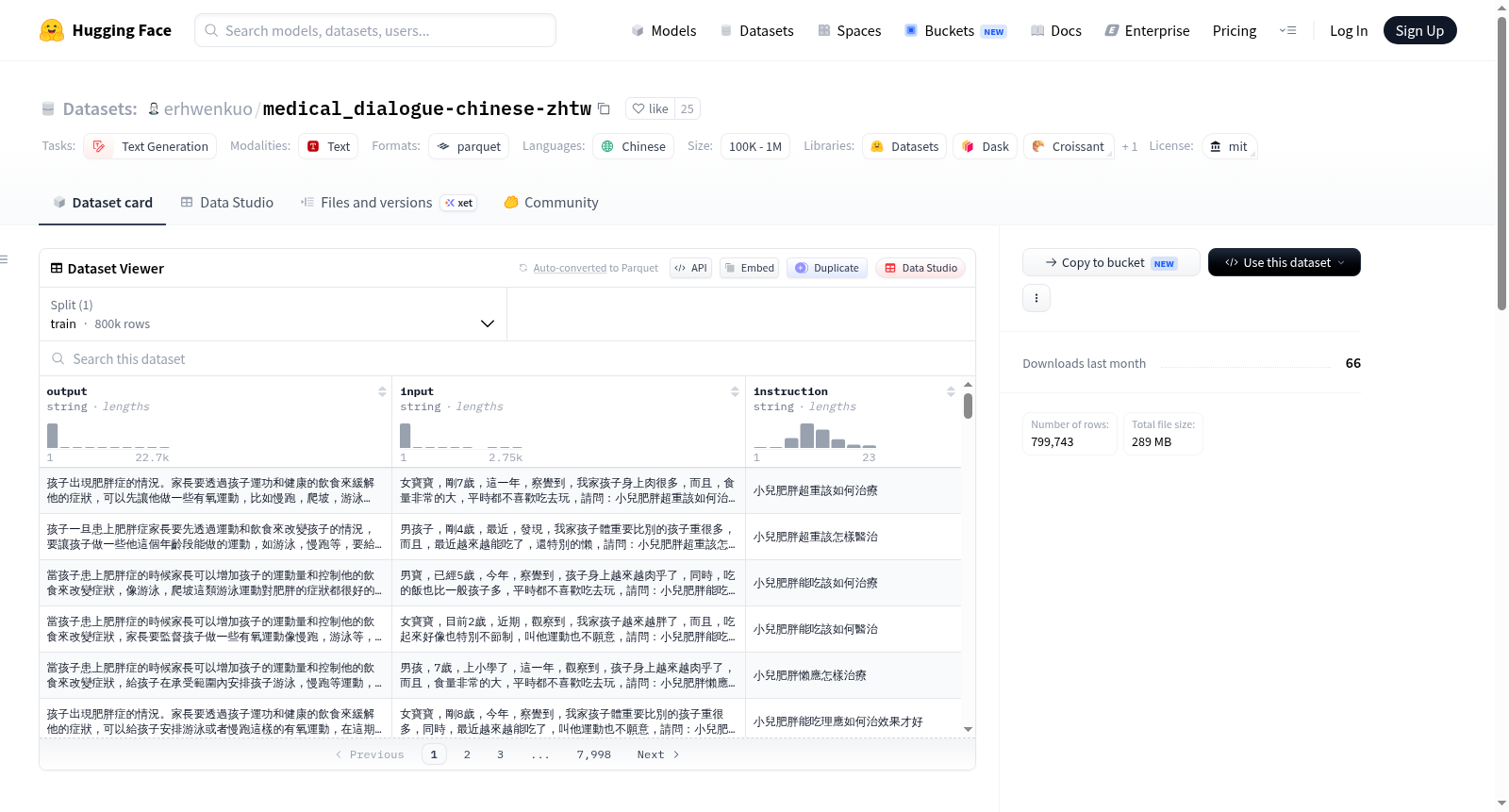
本数据集是一个中文医疗问答数据集,包含男科、内科、妇产科、肿瘤科、儿科和外科等多个科室的问答对,总计792,099条数据。每个数据条目包含三个字段:instruction(指令)、input(输入)和output(输出)。数据集适用于文本生成任务,特别是用于研究大型语言模型。数据集来源于[Toyhom/Chinese-medical-dialogue-data](https://github.com/Toyhom/Chinese-medical-dialogue-data)的GitHub仓库。
提供机构:
erhwenkuo
原始信息汇总
数据集概述
基本信息
- 语言: 中文
- 许可证: MIT
- 大小: 100K<n<1M
- 任务类别: 文本生成
数据集结构
特征
- output: 字符串类型
- input: 字符串类型
- instruction: 字符串类型
数据分割
- 训练集:
- 字节数: 553726613
- 示例数: 799743
下载与数据集大小
- 下载大小: 288686981
- 数据集大小: 553726613
数据内容
- 总数据量: 792,099 条
- 各科别数据量:
- 男科: 94,596 个问答对
- 内科: 220,606 个问答对
- 妇产科: 183,751 个问答对
- 肿瘤科: 75,553 个问答对
- 儿科: 101,602 个问答对
- 外科: 115,991 个问答对
数据示例
json { "instruction": "現在你是個神經腦外科醫生,請根據病人的問題給予建議:", "input": "癲癇病能吃德巴金嗎,錯覺,有時候感覺看到的和聽到的不太一樣。", "output": "巴金是廣譜抗病藥物,主要作用於中樞神經系統,對動物的藥理研究發現德巴金對各種癲癇的實驗模型(全身性和局部性)均有抗驚厥作用,對人的各種類型癲癇發作有抑製作用,作用機理可能與增加γ-氨基丁酸的濃度有關。主要是治癲癇藥物。建議在醫生的知道下,用藥,祝您身體早日康復。" }
使用限制
- 本数据集仅用于研究大型语言模型的目的,不得用于可能对社会带来危害的用途。
- 使用本数据集所带来的一切损害、纠纷,本项目不承担任何责任。
搜集汇总
数据集介绍
构建方式
在智能医疗与自然语言处理交叉融合的前沿领域,高质量的医疗对话数据集对推动中文医疗大语言模型的发展至关重要。该数据集源自Toyhom在GitHub上开源的Chinese-medical-dialogue-data仓库,经过系统性转换与结构化处理而成。构建过程涵盖了男科、内科、妇产科、肿瘤科、儿科及外科六大核心科室,共计792,099条医患问答对,每条数据均包含指令、输入与输出三个字段,形成清晰的三元组结构,为模型训练提供了规范化的监督信号。
特点
该数据集展现了卓越的领域覆盖广度与数据规模优势,其科室分布均衡,内科与妇产科数据量尤为丰富,分别达到22万与18万余条,有效支撑了多专科医疗对话的建模需求。数据以JSON格式存储,每条样本均包含明确的指令前缀、患者输入及医生输出,模拟了真实诊疗场景中的交互逻辑。此外,数据集采用MIT开源协议,允许研究用途的灵活使用,同时明确标注了使用限制,强调仅用于学术研究并规避社会危害。
使用方法
该数据集在HuggingFace上以标准格式发布,用户可通过datasets库直接加载,指定配置名'default'并调用train分割即可获取全部数据。每条样本包含instruction、input与output三个字段,适用于文本生成任务中的指令微调与对话系统开发。研究者可将其用于训练医疗领域的大语言模型,通过构建输入-输出映射关系提升模型在临床咨询、症状分析及用药建议等方面的生成能力。使用时需注意遵循MIT许可协议,避免用于任何可能对人类社会造成危害的场景。
背景与挑战
背景概述
在自然语言处理与医疗健康深度融合的背景下,构建高质量的中文医疗对话数据集对于推动智能问诊系统的发展至关重要。由研究者erhwenkuo于近期创建的medical_dialogue-chinese-zhtw数据集,源自Toyhom维护的Chinese-medical-dialogue-data仓库,旨在为中文医疗领域的文本生成任务提供大规模、多科室的问答对资源。该数据集覆盖男科、内科、妇产科、肿瘤科、儿科及外科六大核心科室,总计约79.2万条问答实例,每条数据包含指令、输入与输出三字段,结构清晰。其发布不仅弥补了中文医疗对话语料的稀缺性,也为大语言模型在临床辅助诊断、患者咨询等场景中的微调与评估奠定了坚实基础,在学术界和工业界引发了广泛关注。
当前挑战
该数据集面临的核心挑战体现在两个层面。在领域问题层面,医疗对话生成需应对诊断推理的复杂性与安全性,模型易产生不准确或误导性建议,且不同科室间的知识差异与症状表述多样性加剧了生成结果的可靠性难题。在构建过程中,数据源自公开的互联网医疗问答,存在噪声、重复及非标准化表述,需进行繁重的清洗与对齐工作;同时,指令字段的模板化设计可能限制模型对真实对话动态的泛化能力。此外,科室间数据量分布不均(如肿瘤科仅7.5万对,而内科超22万对)可能导致模型产生偏倚,影响跨科室迁移效果,对后续的平衡采样与领域自适应策略提出了更高要求。
常用场景
经典使用场景
该数据集汇集了来自中文医疗领域的近80万条医患对话,覆盖男科、内科、妇产科、肿瘤科、儿科及外科六大核心科室,为构建和微调面向中文医疗场景的大规模语言模型提供了高质量的训练资源。研究者常利用其指令-输入-输出的结构化格式,训练模型理解患者主诉并生成专业、安全的医疗建议,从而提升模型在医疗对话生成任务中的表现。
解决学术问题
在学术研究中,该数据集有效缓解了中文医疗领域高质量标注对话数据匮乏的困境,推动了低资源场景下的医疗大语言模型预训练与微调研究。它支持探索指令微调、知识增强生成及多轮对话建模等前沿课题,为评估模型在医学知识问答、症状鉴别诊断及用药建议生成等任务中的准确性提供了基准,促进了医疗AI在中文环境下的可信度与鲁棒性提升。
衍生相关工作
该数据集衍生了一系列经典工作,包括基于其构建的中文医疗对话生成基线模型、融合医学知识图谱的增强型问答系统,以及针对医疗领域幻觉问题设计的验证框架。此外,研究者还以此为基础开发了跨科室的医疗对话摘要模型,并探索了通过对抗训练提升模型对敏感医疗信息的隐私保护能力,推动了中文医疗NLP从数据构建到模型部署的全链条创新。
以上内容由遇见数据集搜集并总结生成


