TreeBench
收藏Hugging Face2025-07-15 更新2025-07-16 收录
下载链接:
https://huggingface.co/datasets/HaochenWang/TreeBench
下载链接
链接失效反馈官方服务:
资源简介:
TreeBench是一个针对视觉定位推理能力的诊断基准数据集,它由405个具有挑战性的视觉问答对组成,专为评估模型在复杂场景中的细微目标视觉感知、跟踪证据的边界框评估以及对象交互和空间层次推理的能力。
TreeBench is a diagnostic benchmark dataset targeting visual localization and reasoning capabilities. It consists of 405 challenging visual question-answer pairs, which are specifically designed to evaluate a model's abilities in subtle target visual perception in complex scenarios, bounding box evaluation for tracking evidence, object interaction, and spatial hierarchy reasoning.
创建时间:
2025-07-01
原始信息汇总
TreeBench数据集概述
数据集基本信息
- 许可证: Apache-2.0
- 任务类别: 图像文本到文本
- 标签: 视觉基础、VQA、基准测试、推理
数据集简介
TreeBench是一个用于视觉基础推理的诊断基准测试数据集,首次在论文《Traceable Evidence Enhanced Visual Grounded Reasoning: Evaluation and Methodology》中提出。该数据集专注于评估"通过图像思考"的能力,并提供可追踪的视觉证据。
数据集特点
- 视觉感知: 专注于复杂场景中的细微目标。
- 可追踪证据: 通过边界框评估实现。
- 二阶推理: 测试对象交互和空间层次结构,超越简单对象定位。
数据集构成
- 图像来源: 从SA-1B中采样1,000张高质量图像。
- 标注过程: 由八位LMM专家手动标注问题、候选选项和答案。
- 最终规模: 包含405个具有挑战性的视觉问答对。
性能表现
- 最先进模型在该数据集上的准确率均未超过60%。
- 例如,OpenAI-o3的准确率仅为54.87%。
相关资源
- 模型:
- 训练数据集:
引用
如需在研究中引用该数据集,请使用提供的BibTeX格式。
搜集汇总
数据集介绍
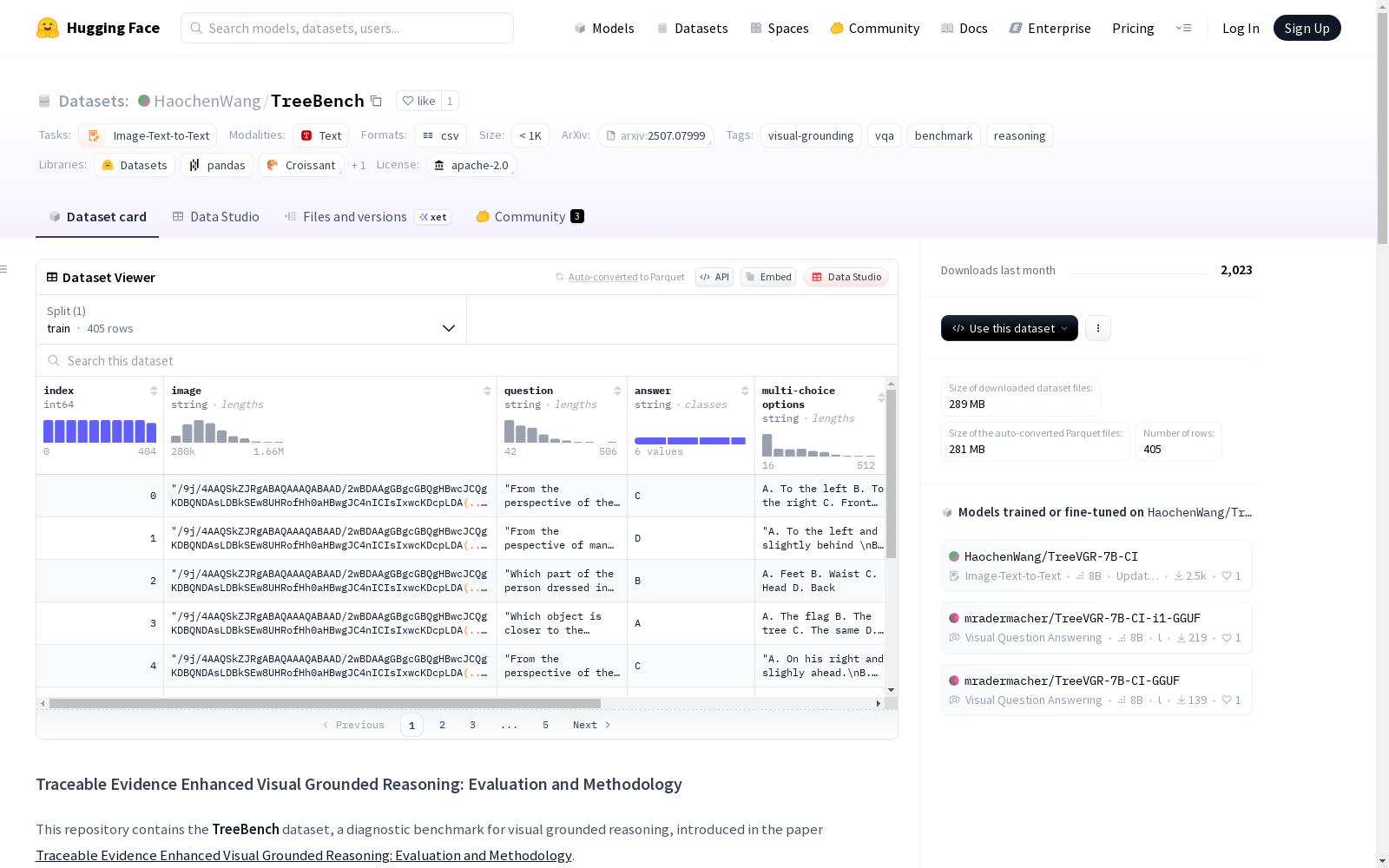
构建方式
在视觉推理领域,TreeBench的构建遵循严谨的三项原则:聚焦复杂场景中细微目标的感知能力、通过边界框评估实现证据可追溯性,以及测试物体交互与空间层次的高阶推理。研究团队从SA-1B数据集中精选1000张高密度物体图像,邀请八位大型多模态模型专家进行人工标注,经过三轮质量控制,最终形成405个具有挑战性的视觉问答对,每个样本均包含问题、候选选项和答案的精细标注。
特点
该数据集的核心特征体现在其诊断性评估框架中:通过可追溯的视觉证据要求模型在推理过程中明确标注参考区域,从而突破传统视觉问答仅关注答案准确性的局限。数据集涵盖感知与推理两大维度,细分出属性识别、空间包容、视角转换等十个子类别,即使最先进的模型也难以达到60%的准确率,如OpenAI-o3仅获得54.87分,充分验证了其在检验多模态模型深层推理能力方面的权威性。
使用方法
研究人员可通过GitHub仓库获取TreeBench评估工具,运行inference_treebench.py脚本即可生成标准化测试报告。输出结果包含各子类别的准确率与平均交并比指标,例如感知类任务中OCR准确率达61.76%,而推理类任务中视角转换仅22.35%,这种细粒度性能分析有助于精准定位模型弱点,为开发可解释的视觉推理系统提供关键基准。
背景与挑战
背景概述
视觉推理领域近年来在人工智能研究中占据重要地位,TreeBench数据集由研究团队于2025年创建,旨在填补动态视觉推理能力评估的空白。该数据集基于SA-1B图像库精心筛选1000张高复杂度图像,通过八位专家级标注者进行多轮质量控制,最终形成405个具有挑战性的视觉问答对。其核心研究问题聚焦于模型对图像中细微目标的感知能力与可追溯推理路径的建立,为视觉 grounded reasoning 领域提供了首个具有可验证证据的诊断基准。
当前挑战
该数据集主要解决视觉 grounded reasoning 中二阶推理的挑战,包括复杂场景下的目标交互分析、空间层次关系理解和视角转换等高阶认知任务。构建过程中面临三大挑战:一是需要确保标注问题涵盖感知属性识别、物理状态判断等多元维度;二是必须实现 bounding box 级别的视觉证据追溯,要求标注精度达到像素级;三是需要维持问题难度与真实世界复杂性的平衡,即使最先进模型在此基准上的准确率也难以突破60%。
常用场景
经典使用场景
在视觉推理研究领域,TreeBench数据集通过精心设计的视觉问答任务,为评估多模态模型的细粒度感知与推理能力提供了标准测试平台。该数据集要求模型在复杂场景中定位关键视觉元素,并基于空间关系和对象属性进行多层次推理,典型应用于验证模型在目标检索、属性识别、空间层次理解等任务上的性能表现。
衍生相关工作
基于TreeBench的创新设计,研究社区衍生出TreeVGR等一系列突破性工作,通过强化学习联合优化定位与推理过程,显著提升了多模态模型的性能。这些工作不仅建立了视觉 grounded reasoning 的新范式,还催生了TreeVGR-RL-37K等高质量训练数据集,推动了整个领域向可解释性强、证据可追溯的方向发展。
数据集最近研究
最新研究方向
在视觉 grounded reasoning 领域,TreeBench 数据集的推出标志着可追溯视觉证据评估的重要突破。该数据集通过构建包含复杂场景中细微目标感知、边界框可追溯性验证以及二阶推理任务的诊断基准,为多模态模型提供了严格的评估框架。当前研究热点集中于结合强化学习的联合定位与推理训练范式,如 TreeVGR 模型所示范的,其在多项基准测试中显著提升性能,证实了可追溯性对于推动视觉 grounded reasoning 发展的关键作用。这一进展不仅促进了模型透明度和可解释性的提升,还为自动驾驶、医疗影像分析等实际应用提供了更可靠的视觉推理解决方案。
以上内容由遇见数据集搜集并总结生成


