Helsinki-NLP/euconst
收藏Hugging Face2024-02-27 更新2024-04-20 收录
下载链接:
https://hf-mirror.com/datasets/Helsinki-NLP/euconst
下载链接
链接失效反馈官方服务:
资源简介:
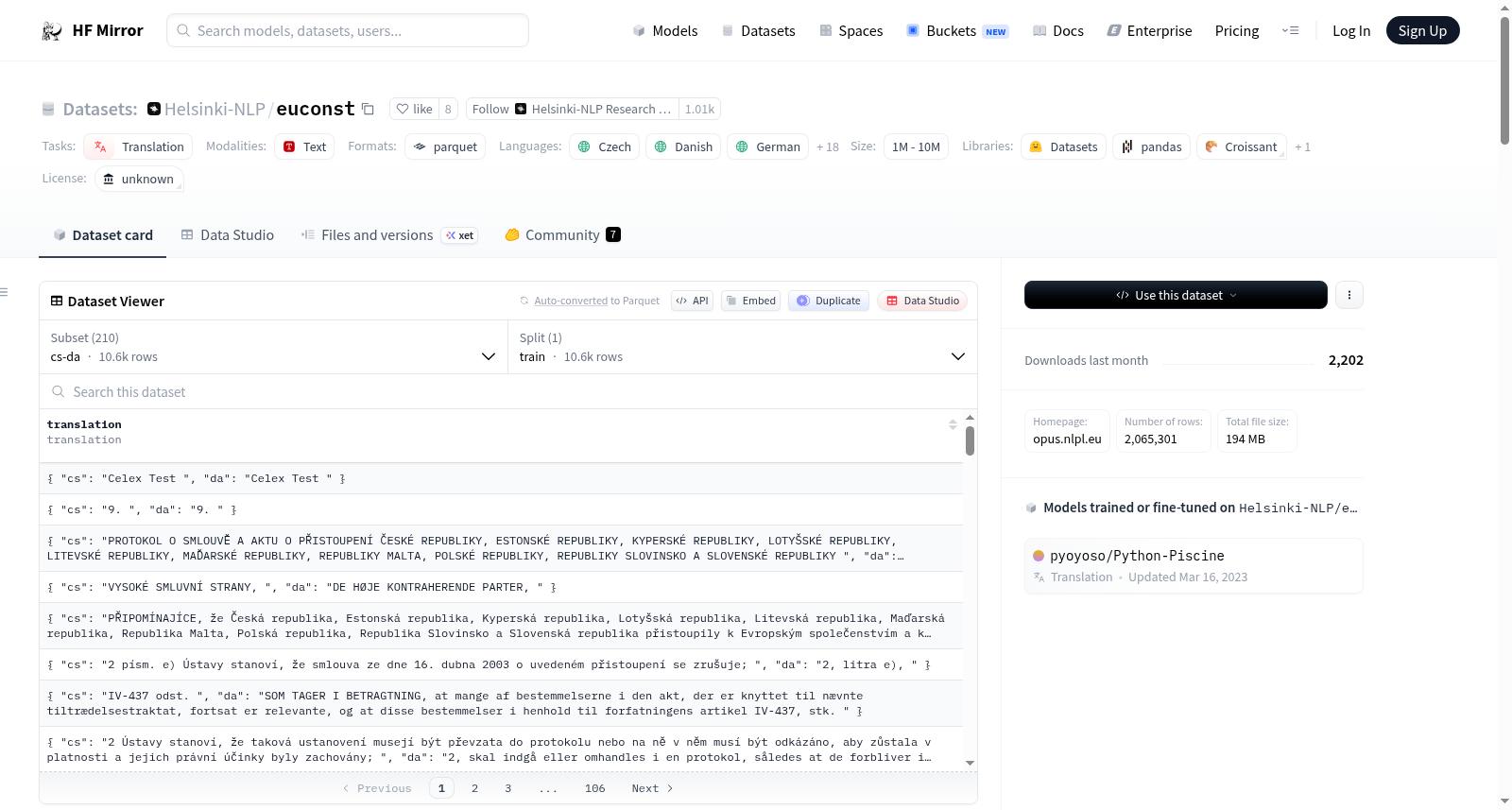
OPUS EUconst数据集是一个多语言翻译数据集,包含多种语言对的翻译任务,如cs-da、cs-de、cs-el等。每个配置详细说明了涉及的语言、字节数、示例数和下载大小。数据集被归类为多语言,且规模在10K到100K示例之间。
提供机构:
Helsinki-NLP
原始信息汇总
数据集概述
基本信息
- 名称: OPUS EUconst
- 语言: 多语言,包括cs, da, de, el, en, es, et, fi, fr, ga, hu, it, lt, lv, mt, nl, pl, pt, sk, sl, sv
- 许可证: 未知
- 多语言性: 多语言
- 大小类别: 10K<n<100K
- 源数据集: 原始
- 任务类别: 翻译
详细配置
- 配置名称: 多种语言对,如cs-da, cs-de, cs-el等
- 特征: 每个配置包含一个名为"translation"的特征,该特征包含两种语言
- 分割: 每个配置包含一个名为"train"的分割,详细信息如下:
- 训练集大小: 每个语言对的训练集大小不同,范围从8586到10970个例子
- 训练集字节数: 每个语言对的训练集字节数不同,范围从1679327到2908134字节
- 下载大小: 每个语言对的下载大小不同,范围从801282到1194894字节
- 数据集大小: 每个语言对的数据集大小不同,范围从1679327到2908134字节
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集是一个从欧洲宪法收集的平行语料库,专门用于机器翻译任务。它包含21种欧洲语言,形成210个双语文本对,总数据量约2百万行,覆盖多种语言组合,支持跨语言研究和模型训练。
以上内容由遇见数据集搜集并总结生成


