Kvasir-VQA
收藏Kvasir-VQA 数据集概述
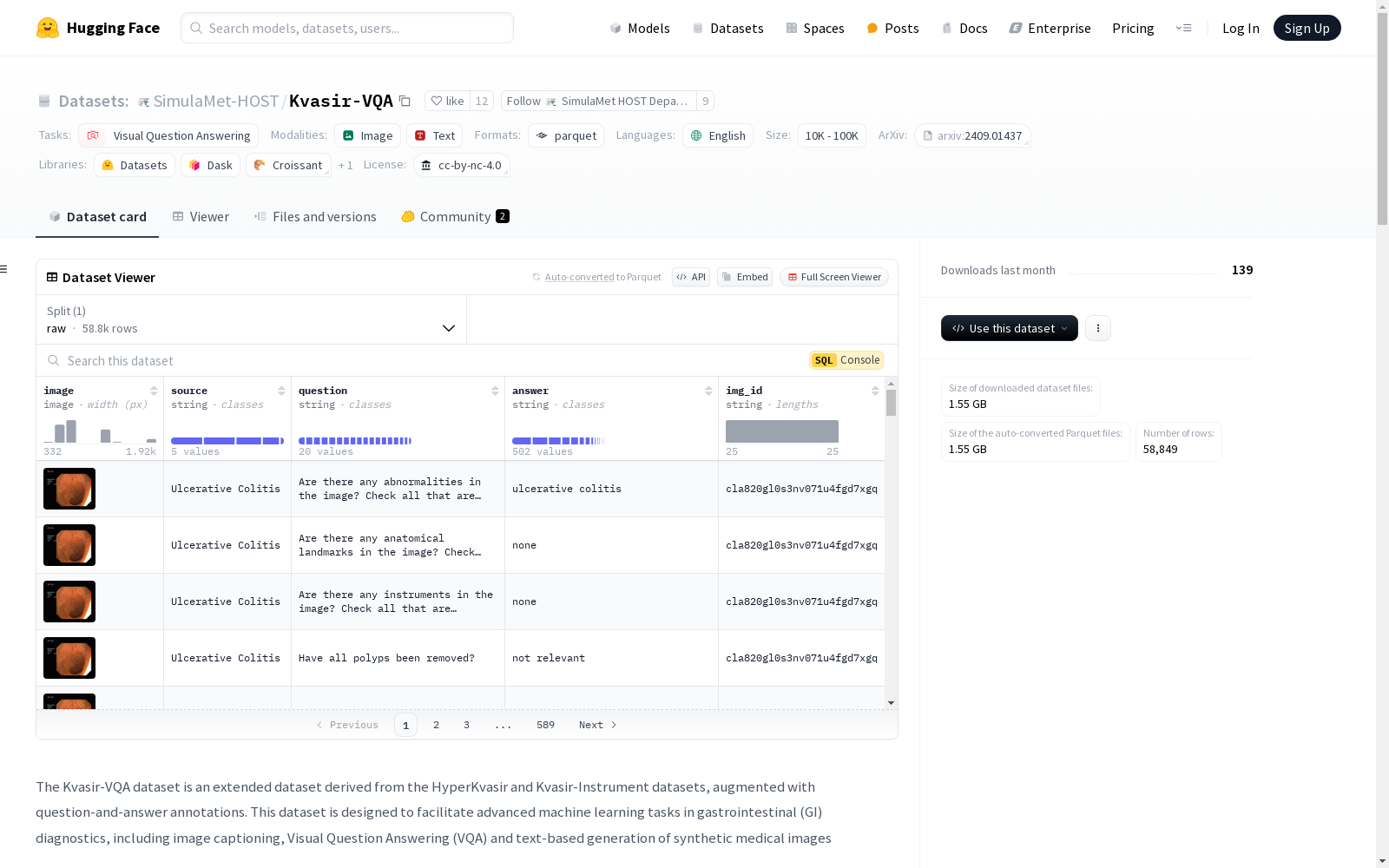
数据集信息
特征
- image: 图像数据
- source: 字符串,数据来源
- question: 字符串,问题
- answer: 字符串,答案
- img_id: 字符串,图像ID
分割
- raw: 原始数据分割,包含58849个样本,大小为15176464880.875字节
大小
- 下载大小: 1547864596字节
- 数据集大小: 15176464880.875字节
配置
- default: 默认配置,数据文件路径为
data/*.parquet
许可
- cc-by-nc-4.0: 非商业性使用许可
任务类别
- visual-question-answering: 视觉问答
语言
- en: 英语
数据集描述
概述
Kvasir-VQA 数据集是从 HyperKvasir 和 Kvasir-Instrument 数据集扩展而来的,增加了问题和答案的标注。该数据集旨在促进胃肠道(GI)诊断中的高级机器学习任务,包括图像描述、视觉问答(VQA)和基于文本的合成医学图像生成。
关键特性
- 总图像数: 6500张标注图像
- 标注: 包含每个图像的问题和答案对
- 问题类型: 是/否、单选、多选、颜色相关、位置相关、数量统计
- 应用: 图像描述、VQA、合成医学图像生成、目标检测等
图像类别
| 图像类别 | 样本数量 | 来源数据集 |
|---|---|---|
| 正常 | 2500 | HyperKvasir |
| 息肉 | 1000 | HyperKvasir |
| 食管炎 | 1000 | HyperKvasir |
| 溃疡性结肠炎 | 1000 | HyperKvasir |
| 器械 | 1000 | Kvasir-Instrument |
| 总计 | 6500 |
标注过程
标注由医学专业人员参与,包含六种类型的问题:
- 是/否问题
- 单选问题
- 多选问题
- 颜色相关问题
- 位置相关问题
- 数量统计问题
标注涵盖了胃肠道方面的各种发现、异常、解剖标志和医疗仪器。
使用条款
使用 Kvasir-VQA 数据集时,应包含以下信息以确保遵守数据集的使用条款,特别是在引用数据集的文档或论文中:
@article{Gautam2024Sep, author = {Gautam, Sushant and Stor{aa}s, Andrea and Midoglu, Cise and Hicks, Steven A. and Thambawita, Vajira and Halvorsen, P{aa}l and Riegler, Michael A.}, title = {{Kvasir-VQA: A Text-Image Pair GI Tract Dataset}}, journal = {arXiv}, year = {2024}, month = sep, eprint = {2409.01437}, doi = {10.48550/arXiv.2409.01437} }
@inproceedings{gautam2024kvasirvqa, title={Kvasir-VQA: A Text-Image Pair GI Tract Dataset}, author={Gautam, Sushant and Storås, Andrea and Midoglu, Cise and Hicks, Steven A. and Thambawita, Vajira and Halvorsen, Pål and Riegler, Michael A.}, booktitle={Proceedings of the First International Workshop on Vision-Language Models for Biomedical Applications (VLM4Bio 24)}, year={2024}, location={Melbourne, VIC, Australia}, pages={10 pages}, publisher={ACM}, doi={10.1145/3689096.3689458} }
联系方式
如有任何问题,请联系 michael@simula.no, vajira@simula.no, steven@simula.no 或 paalh@simula.no。