Academ-AI
收藏arXiv2024-11-21 更新2024-11-27 收录
下载链接:
https://www.academ-ai.info/
下载链接
链接失效反馈官方服务:
资源简介:
Academ-AI数据集由路易斯维尔大学科恩豪泽健康科学图书馆创建,旨在收集和分析学术文献中疑似未声明使用人工智能的实例。该数据集包含500个示例,主要通过查询Google Scholar和Retraction Watch列表收集,涵盖了2022年后的学术期刊文章和会议论文。数据集的创建过程包括手动检查和筛选,确保数据的质量和准确性。该数据集主要用于研究学术出版物中未声明使用AI的现象,旨在提高学术出版的透明度和诚信度。
The Academ-AI Dataset was created by the Kornhauser Health Sciences Library at the University of Louisville, aiming to collect and analyze instances of suspected undeclared artificial intelligence use in academic literature. This dataset contains 500 samples, which are mainly collected by querying Google Scholar and the Retraction Watch list, covering academic journal articles and conference proceedings published after 2022. The creation process of the dataset includes manual inspection and screening to ensure the quality and accuracy of the data. This dataset is primarily used to study the phenomenon of undeclared AI use in academic publications, with the goal of improving the transparency and integrity of academic publishing.
提供机构:
路易斯维尔大学科恩豪泽健康科学图书馆
创建时间:
2024-11-21
搜集汇总
数据集介绍
构建方式
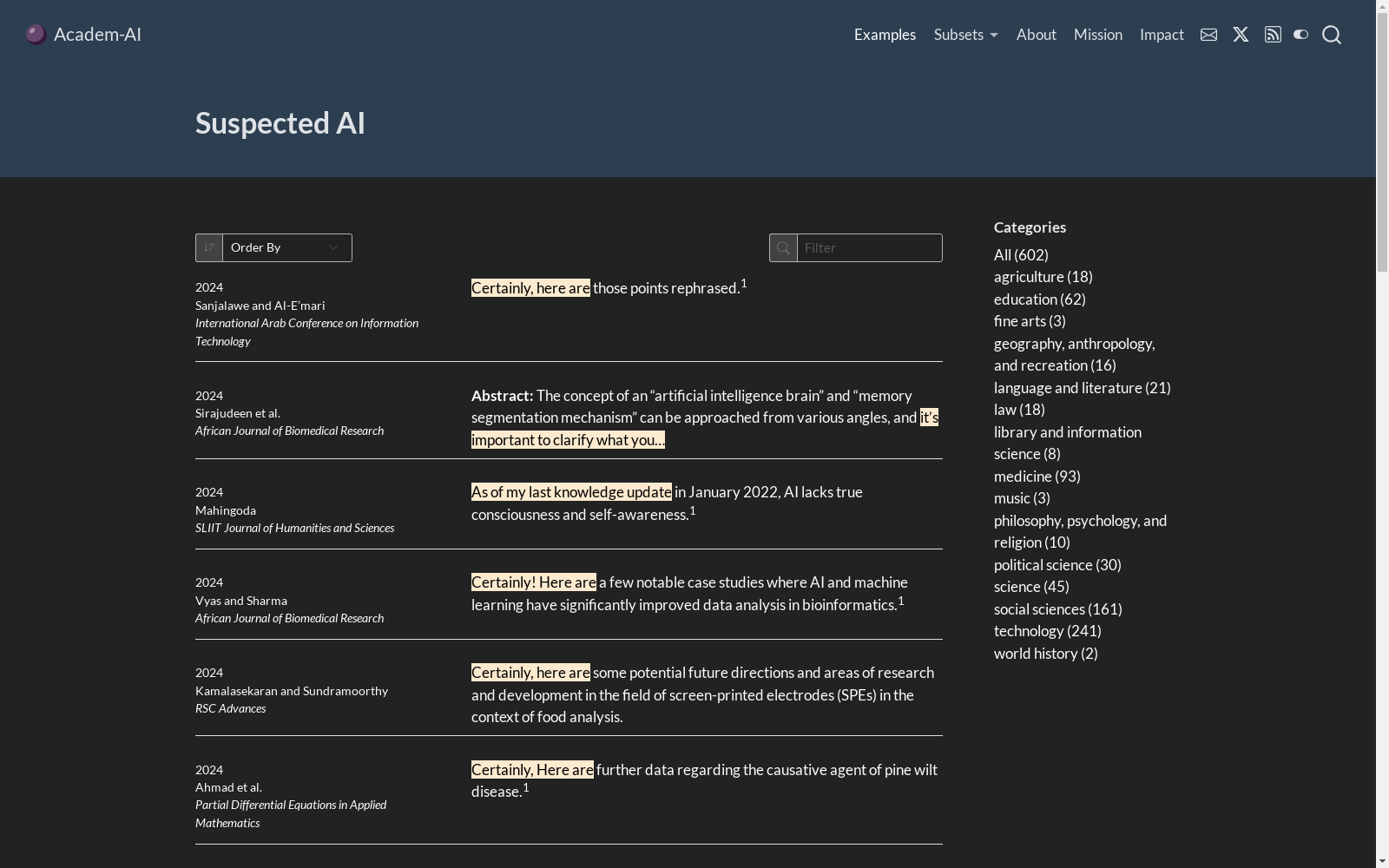
Academ-AI数据集的构建基于对学术文献中疑似未声明使用人工智能(AI)的实例进行系统性收集和分析。研究者通过使用特定于AI生成的文本特征的短语,如“as an AI language model”和“certainly, here are”,在Google Scholar上进行查询,并结合Retraction Watch列表中的证据补充搜索结果。每个结果都经过手动检查,根据包含AI生成文本特征或作者声明未声明使用AI的出版物进行筛选和纳入。数据提取过程中,包含可疑短语的文本段落被提取并存储在Markdown文件中,同时使用Zotero收集引用和手动补充元数据。
特点
Academ-AI数据集的显著特点在于其专注于揭示学术出版物中未声明的AI使用情况,特别是通过识别大型语言模型(LLM)生成的文本特征。该数据集包含了500个实例,涵盖了449篇期刊文章和51篇会议论文,揭示了这一问题的普遍性和严重性。数据集中的实例主要通过特定的AI生成文本特征进行识别,如第一人称单数的使用、模型更新声明、以及AI自我识别等。此外,数据集还包含了关于文章处理费用(APCs)和引用指标的信息,揭示了未声明AI使用与高APC和高引用率之间的关联。
使用方法
Academ-AI数据集可用于研究AI在学术写作中的未声明使用情况,以及评估其对学术出版物质量和透明度的影响。研究者可以通过分析数据集中的文本特征,开发和验证AI生成文本的检测算法。此外,数据集还可用于探讨学术出版物中AI使用的伦理和政策问题,帮助出版商和编辑制定更严格的AI使用声明政策。通过对比不同出版商和期刊的APC和引用指标,研究者还可以分析未声明AI使用与出版成本和学术影响力的关系,从而为学术出版的透明化和规范化提供依据。
背景与挑战
背景概述
Academ-AI数据集由Alex Glynn在2024年创建,旨在揭示学术文献中疑似未声明的人工智能使用情况。该数据集的核心研究问题集中在检测和分析学术出版物中由大型语言模型(LLM)生成的文本,这些文本通常因具有特定特征的措辞而被识别。自OpenAI的ChatGPT于2022年公开发布后,研究人员开始在其工作流程中使用此类工具,引发了学术出版界的广泛争议。学术出版组织如Committee on Publication Ethics (COPE)、Council of Science Editors (CSE)等均明确指出,AI系统不能被列为作者,且使用AI的作者必须在发表的文章中声明其使用情况。Academ-AI数据集的创建不仅揭示了这一问题的普遍性,还强调了出版商在执行相关政策方面的重要性。
当前挑战
Academ-AI数据集面临的挑战主要集中在两个方面。首先,识别和验证学术文献中未声明的AI使用是一个复杂的过程,需要依赖于特定特征的措辞和上下文分析。其次,构建过程中遇到的挑战包括数据收集的准确性和全面性,以及如何处理可能存在的数据伪造问题。此外,尽管学术出版界已达成共识,要求作者声明AI的使用,但实际执行中仍存在许多漏洞,导致大量未声明的AI生成内容进入学术文献。这不仅影响了学术研究的透明度和可信度,也对出版商的政策执行提出了严峻考验。
常用场景
经典使用场景
Academ-AI数据集的经典使用场景在于识别和分析学术文献中未声明的人工智能生成内容。通过收集和分析包含特定语言特征的文献,研究人员可以揭示这些内容的存在及其对学术出版质量的影响。这种分析有助于出版商和编辑识别潜在的违规行为,从而加强学术出版的透明度和诚信。
实际应用
在实际应用中,Academ-AI数据集被广泛用于学术出版的质量控制和政策制定。出版商和编辑可以利用该数据集来开发和优化检测工具,以识别和处理未声明的人工智能生成内容。此外,该数据集还为学术机构和研究者提供了评估和改进其出版实践的依据。
衍生相关工作
基于Academ-AI数据集,许多相关研究工作得以开展。例如,研究人员开发了新的自然语言处理技术来检测人工智能生成内容,并提出了改进的出版政策和指南。此外,该数据集还激发了对人工智能生成内容伦理和法律问题的深入探讨,推动了学术界在这一领域的持续研究和讨论。
以上内容由遇见数据集搜集并总结生成


