WildChat-curated
收藏Hugging Face2025-06-23 更新2025-06-24 收录
下载链接:
https://huggingface.co/datasets/TianyiQ/WildChat-curated
下载链接
链接失效反馈官方服务:
资源简介:
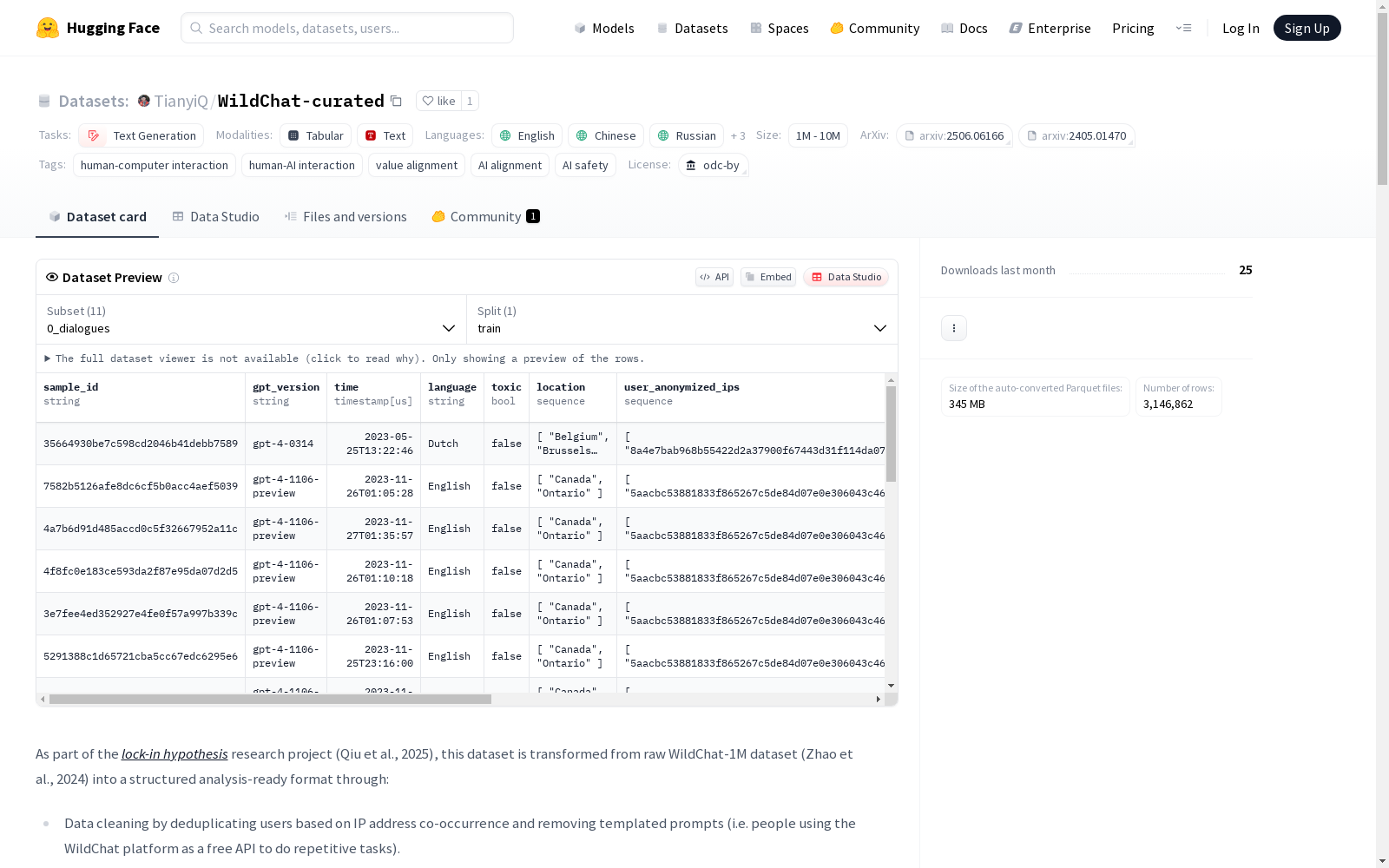
该数据集是从原始的WildChat-1M数据集中转换而来的,经过数据清洗、概念提取和分类等步骤,形成了一个结构化的、可分析的数据集。数据集包括对话数据、价值概念层次结构、与对话关联的价值概念、按时间段和用户统计的价值概念数据等。数据集旨在研究人机交互、人机对话、价值对齐、人工智能对齐和人工智能安全等课题。
创建时间:
2025-06-22
搜集汇总
数据集介绍
构建方式
WildChat-curated数据集源于WildChat-1M原始数据,通过系统化处理流程转化为结构化分析格式。研究团队基于IP地址共现进行用户去重,并剔除模板化提示以净化数据。采用Llama-3.1-8B-Instruct大语言模型提取对话核心概念,通过WordNet进行语言学简化,并运用层次聚类构建话题分类体系。特别识别价值负载概念子集,构建用户级面板和时序面板数据集,包含衡量用户与助手概念使用多样性的指标。最终形成包含74万条对话的精选语料,覆盖16.7万独立用户。
特点
该数据集突出体现多维度分析价值,包含原始对话、价值负载概念和全概念三个层次的结构化数据。价值负载概念体系包含15.7万个节点,全概念体系达544万节点,形成树状层级结构。时序统计模块以3天为间隔单位,完整记录2023年4月至2024年4月的概念演变趋势。创新性地引入谱系多样性指标,量化概念空间分布特征,为研究人机交互中的价值对齐问题提供细粒度测量工具。多语言覆盖和地理位置标记进一步拓展了跨文化比较研究的可能性。
使用方法
研究者可通过HuggingFace平台获取数据集七个核心子集,包括对话文本、概念体系及三类统计面板(时段/用户/概念)。分析流程建议从可视化概念树入手,把握话题层级结构;继而结合时序面板追踪概念流行度演变;最终通过用户级面板探究个体交互模式。价值负载概念子集特别适用于AI安全与价值对齐研究,而全概念体系适合广义的人机交互分析。数据集提供GPT-3.5与GPT-4版本对比维度,支持大模型迭代影响研究。配套的统计指标可直接用于多样性分析和概念扩散建模。
背景与挑战
背景概述
WildChat-curated数据集源于2025年Qiu等人提出的“锁定假说”研究项目,旨在探究人机交互中的价值对齐与AI安全问题。该数据集基于AllenAI发布的WildChat-1M原始数据,经过深度清洗与结构化处理,形成了涵盖多语言、多维度对话分析的研究资源。核心研究聚焦于对话中价值负载概念的提取与层次化聚类,通过构建用户级面板和时序面板,量化了概念使用的多样性特征。其创新性体现在将语言学降维技术与大规模语言模型相结合,为理解AI与人类价值观交互的动态演变提供了实证基础。
当前挑战
该数据集面临双重挑战:在领域问题层面,如何准确识别对话中隐含的价值负载概念仍存在语义模糊性,且跨语言文化背景下的价值观差异增加了对齐难度;在构建过程中,数据清洗面临用户去重与模板化提示剔除的平衡问题,而概念层次聚类算法对超参数敏感,可能影响最终分类体系的鲁棒性。此外,多样性指标的时空稳定性验证也需考虑模型迭代带来的对话模式变迁。
常用场景
经典使用场景
WildChat-curated数据集在人机交互与AI对齐研究中具有重要价值。该数据集通过结构化处理WildChat-1M原始数据,构建了包含多语言对话、价值负载概念层级和多样性指标的分析框架。研究者可基于该数据集开展对话系统行为分析、用户偏好演化追踪以及AI价值对齐等核心研究,尤其适合探究大语言模型在开放域对话中表现出的概念分布特征与时间演化规律。
衍生相关工作
基于该数据集衍生的经典工作包括锁闭假说验证研究(Qiu et al., 2025)和对话系统价值对齐框架。后续研究扩展了概念多样性度量方法,开发了动态概念图谱构建技术。在AI安全领域,该数据集启发了多智能体价值校准算法的设计,并为建立对话系统伦理评估标准提供了数据支撑。
数据集最近研究
最新研究方向
在人工智能对齐与安全领域,WildChat-curated数据集因其多语言对话记录和结构化概念分析框架,成为研究人机交互动态的重要资源。近期研究聚焦于价值负载概念在对话中的演化模式,通过谱系多样性指标量化模型与用户间的概念使用差异,揭示了算法锁闭现象对对话多样性的潜在影响。该数据集支持跨时段、跨用户群的分析,为探究大语言模型在文化价值观传播中的角色提供了实证基础,相关发现已应用于改进对话系统的价值观对齐机制。
以上内容由遇见数据集搜集并总结生成


