bigSunOCR-hand
收藏Hugging Face2025-06-18 更新2025-06-19 收录
下载链接:
https://huggingface.co/datasets/deepcopy/bigSunOCR-hand
下载链接
链接失效反馈官方服务:
资源简介:
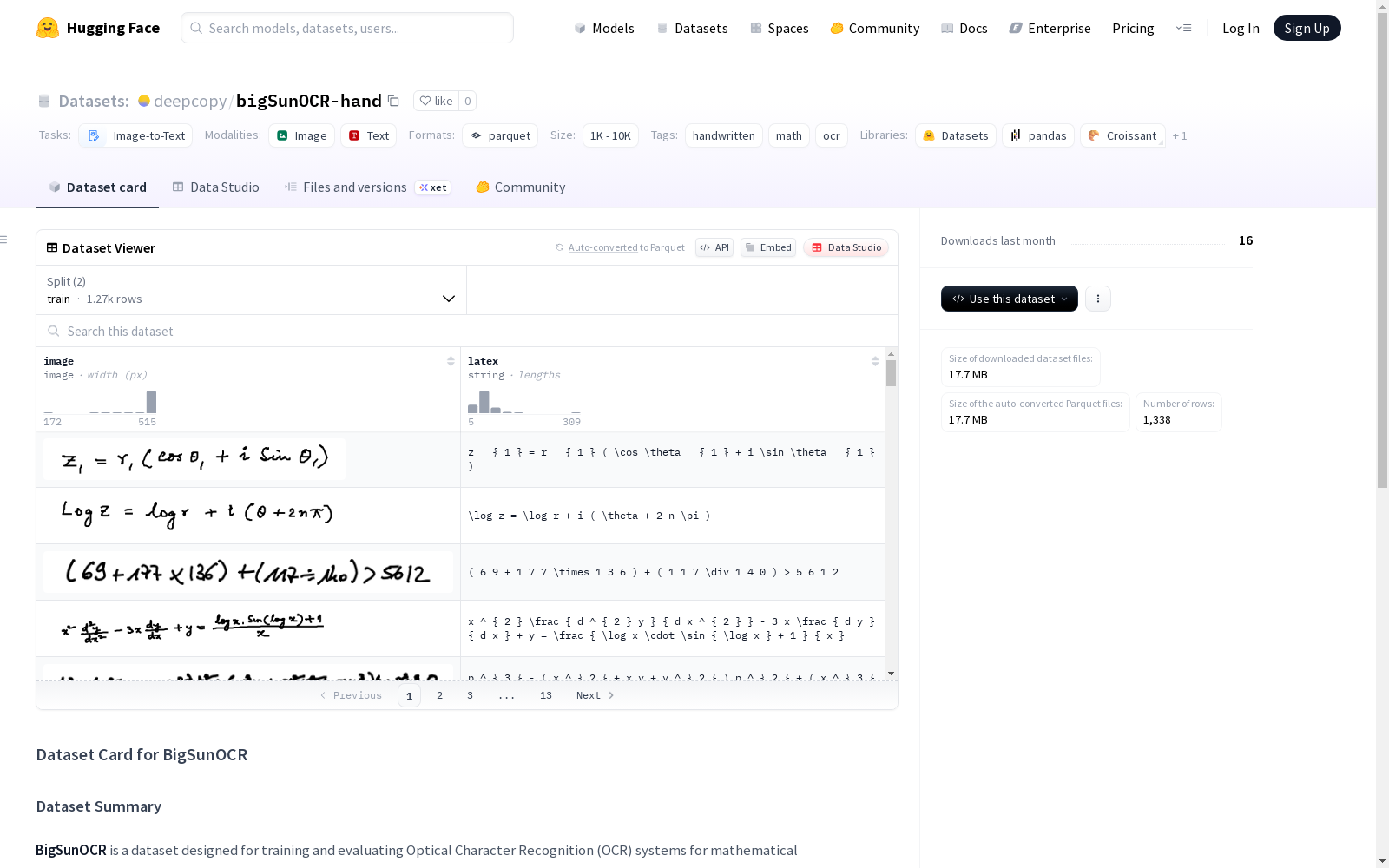
BigSunOCR是一个用于训练和评估光学字符识别(OCR)系统对数学公式识别的数据集,包括手写、打印以及复杂表达式的数学公式。该数据集由WLHEX INC.公司开发,旨在提供成本效益高的训练和推理支持,适用于教育和研究环境中对LaTeX公式识别精确性的需求。数据集包括手写和打印的公式图像以及相应的LaTeX标签。
创建时间:
2025-06-17
原始信息汇总
BigSunOCR数据集概述
数据集基本信息
- 任务类别: 图像到文本(image-to-text)
- 标签: 手写(handwritten)、数学(math)、OCR
- 规模分类: 1K<n<10K
数据特征
- 特征字段:
- 图像(image): 图片格式
- LaTeX公式(latex): 字符串格式
数据划分
- 训练集(train):
- 样本数量: 1268
- 数据大小: 17026438.7字节
- 测试集(test):
- 样本数量: 70
- 数据大小: 906906字节
存储信息
- 下载大小: 17724298字节
- 数据集总大小: 17933344.7字节
数据集描述
- 用途: 用于训练和评估数学公式OCR系统,支持手写、印刷体和复杂表达式的识别
- 开发机构: WLHEX INC.
- 应用场景: 教育和研究领域需要精确LaTeX公式识别的场景
相关资源
- GitHub仓库: https://github.com/Wrste/bigSunOCR
- 包含内容: 完整代码、预训练模型和使用说明
引用信息
bibtex @misc{BigSunOCR, author = {XingChengFu (bigSun), WLHEX INC.}, title = {BigSunOCR: Deep Learning-based Mathematical Formula OCR Recognition System}, year = 2024, url = {https://github.com/Wrste/bigSunOCR} }
搜集汇总
数据集介绍
构建方式
在数学公式光学字符识别领域,BigSunOCR-hand数据集通过系统化采集流程构建而成。该数据集整合了1268个训练样本和70个测试样本,每个样本包含手写数学公式图像及其对应的LaTeX标注。数据采集过程注重多样性,涵盖不同书写风格和复杂度的数学表达式,通过专业标注团队确保LaTeX序列的准确性,为OCR模型训练提供高质量的配对数据。
特点
作为专注于数学公式识别的专业数据集,BigSunOCR-hand具有鲜明的领域特征。其核心价值在于同时包含手写体图像和结构化的LaTeX标注,支持端到端的OCR系统开发。数据集特别设计了长序列LaTeX标注能力,能有效处理复杂数学表达式的识别任务。1K-10K的规模区间使其既具备模型训练的可靠性,又保持较高的使用效率。
使用方法
该数据集适用于训练和评估基于深度学习的数学公式OCR系统。典型使用流程包括:通过加载图像-LaTeX配对数据,构建CRNN等序列识别模型的训练集;利用测试集评估模型对手写公式的识别准确率。开发者可结合GitHub提供的预训练模型进行迁移学习,或基于PyTorch框架重新训练。数据集的标准化格式支持直接接入主流深度学习框架的视觉-文本处理管道。
背景与挑战
背景概述
BigSunOCR数据集由WLHEX INC.于2024年推出,专注于数学公式的光学字符识别(OCR)任务。该数据集旨在为手写、印刷及复杂数学表达式的识别提供训练和评估资源,推动教育及研究领域的高效LaTeX公式识别技术发展。其核心研究问题在于解决数学公式OCR中的长序列LaTeX编码挑战,通过改进的CRNN架构提升识别精度。作为开源项目的一部分,该数据集不仅包含丰富的图像-文本配对样本,还配套提供了预训练模型与完整代码库,为相关领域的研究与实践提供了重要支持。
当前挑战
BigSunOCR数据集面临的挑战主要体现在两个方面:领域问题层面,数学公式结构复杂且符号多样,尤其是手写体的笔画变异和空间布局差异,增加了OCR系统对长序列LaTeX编码的准确解析难度;数据构建层面,需平衡手写与印刷公式的样本多样性,同时确保LaTeX标签与图像内容的精确对齐,这对标注一致性与数据质量控制提出了较高要求。此外,跨场景应用的泛化能力仍需通过更大规模的多样化数据来强化。
常用场景
经典使用场景
在数学公式识别领域,BigSunOCR-hand数据集为研究者提供了丰富的训练样本,特别是针对手写数学公式的识别任务。该数据集通过结合图像与对应的LaTeX标签,成为开发高效OCR系统的关键资源。其典型应用场景包括教育技术中的自动批改系统,以及科研文献中的公式提取与转换。
衍生相关工作
基于BigSunOCR-hand数据集,研究者们已开发出多个改进型CRNN架构,特别是在注意力机制与序列建模方面取得突破。相关衍生工作包括端到端的公式识别系统、多语言数学符号处理框架,以及结合语义理解的混合式OCR解决方案,这些成果在CVPR、ICML等顶级会议中均有所体现。
数据集最近研究
最新研究方向
在数学公式光学字符识别领域,BigSunOCR数据集因其专注于手写与印刷体混合的复杂数学表达式而备受关注。近期研究主要围绕提升长序列LaTeX符号的识别准确率展开,通过改进CRNN架构中的时序建模模块,显著增强了模型对嵌套分数、多重积分等复杂结构的解析能力。随着STEM教育数字化进程加速,该数据集在智能批改系统和交互式学习平台中的应用成为热点,微软Teams等教育科技产品已开始整合类似技术以实现实时公式转录。其开源特性进一步推动了跨语言公式识别研究,特别是在中日韩等非拉丁语系场景下,研究者正探索结合注意力机制与字形先验知识的新方法。
以上内容由遇见数据集搜集并总结生成


