scikit-learn/credit-card-clients
收藏Hugging Face2022-06-20 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/scikit-learn/credit-card-clients
下载链接
链接失效反馈官方服务:
资源简介:
该数据集包含了2005年4月至9月期间台湾信用卡客户的违约支付、人口统计因素、信用数据、支付历史和账单信息。数据集包含25个变量,涵盖了客户的ID、信用额度、性别、教育程度、婚姻状况、年龄、各月的还款状态、账单金额和支付金额等信息。
This dataset contains default payment records, demographic factors, credit data, payment history and billing information of credit card clients in Taiwan during the period from April to September 2005. It includes 25 variables covering customer ID, credit limit, gender, education level, marital status, age, monthly repayment status, bill amounts, payment amounts and other relevant information.
提供机构:
scikit-learn
原始信息汇总
数据集概述
数据集名称
Default of Credit Card Clients Dataset
数据集来源
UCI machine learning repository
数据集内容
- 时间范围:2005年4月至2005年9月
- 地理位置:台湾
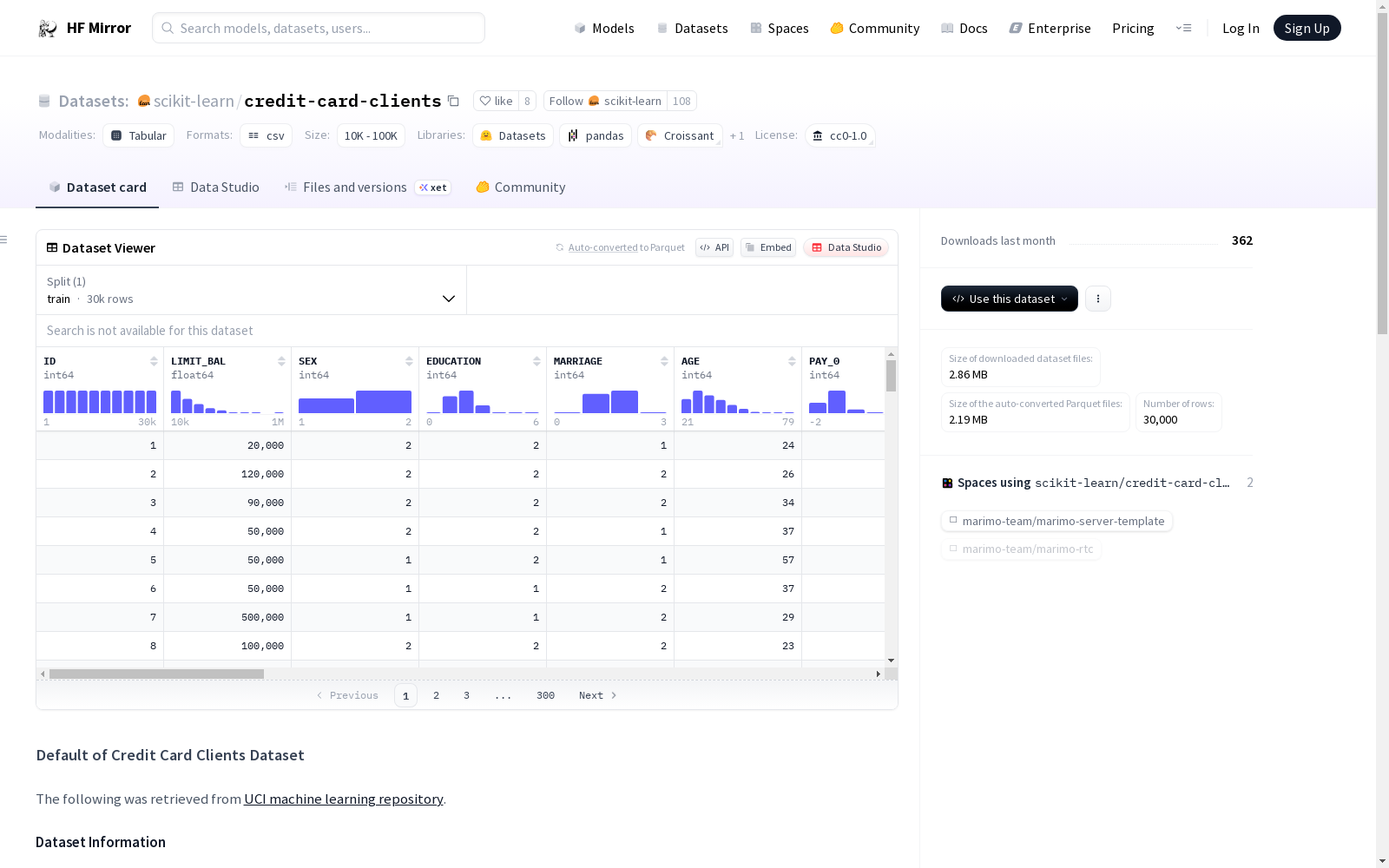
- 数据类型:包含25个变量,涉及客户ID、信用额度、性别、教育程度、婚姻状况、年龄、还款状态、账单金额和前期支付金额等。
变量详情
- ID:客户ID
- LIMIT_BAL:信用额度(新台币)
- SEX:性别(1=男, 2=女)
- EDUCATION:教育程度(1=研究生, 2=大学, 3=高中, 4=其他, 5=未知, 6=未知)
- MARRIAGE:婚姻状况(1=已婚, 2=单身, 3=其他)
- AGE:年龄(岁)
- PAY_0 to PAY_6:各月份还款状态(-1=准时还款, 1-9=不同程度的延迟还款)
- BILL_AMT1 to BILL_AMT6:各月份账单金额(新台币)
- PAY_AMT1 to PAY_AMT6:各月份前期支付金额(新台币)
- default.payment.next.month:下月是否违约(1=是, 0=否)
数据集用途
- 探索不同人口统计变量类别下违约概率的变化。
- 识别预测违约的最强变量。
许可证
cc0-1.0
搜集汇总
数据集介绍
构建方式
scikit-learn/credit-card-clients数据集的构建,是基于台湾地区2005年4月至9月间信用卡客户的还款、人口统计、信用记录、还款历史及账单数据。该数据集涵盖了25个变量,包括客户的ID、信用额度、性别、教育程度、婚姻状况、年龄、还款状态、账单金额以及前一个月的还款金额等,旨在为信用风险评估提供详实的数据基础。
使用方法
使用该数据集时,研究者可根据需求,通过Python的scikit-learn库直接导入。数据集的每个字段都有明确的定义,便于理解与分析。针对不同的研究目的,可以对数据集进行清洗、转换和特征提取等预处理操作,进而利用机器学习算法进行模型训练和评估。同时,数据集的开放性使得研究者能够方便地进行拓展研究和二次开发。
背景与挑战
背景概述
在金融风险管理的领域内,信用违约是极具研究价值的现象。'scikit-learn/credit-card-clients'数据集,源自于台湾地区2005年4月至9月间信用卡客户的信用记录,由UCI机器学习库提供,旨在探讨信用卡用户违约的影响因素。该数据集涵盖了25个变量,包括客户的个人信息、信用额度、婚姻状况、教育背景以及过去数月的还款情况等,为研究人员提供了一个深入分析信用卡违约行为的丰富资源。数据集自发布以来,对信用评分模型的构建与优化,以及对金融信贷风险评估策略的完善,产生了显著影响。
当前挑战
尽管该数据集为相关领域的研究提供了宝贵的资源,但在使用过程中也面临着若干挑战。首先,数据集样本的多样性与代表性可能有限,这可能会影响模型的泛化能力。其次,数据集包含了缺失值和分类不明确的变量(如教育背景中的'unknown'分类),这对数据清洗和预处理提出了更高要求。此外,如何有效结合时序特征(如过去数月的还款情况)来预测未来的违约行为,也是构建精确信用评分模型时必须克服的技术难题。
常用场景
经典使用场景
在金融风险评估领域,scikit-learn/credit-card-clients数据集被广泛用于构建信用评分模型。该数据集详细记录了台湾地区信用卡客户的个人信息、信用额度、还款历史以及账单信息,为研究人员提供了丰富的特征变量,以预测客户是否会拖欠下一月的信用卡还款,是信用风险模型构建的经典案例。
解决学术问题
该数据集解决了信用评估中的关键问题,如如何通过客户的历史还款行为、账单金额和人口统计信息来预测其违约概率。这对于降低金融机构的信贷风险、优化资源配置以及提升风险管理效率具有显著意义,是金融学术研究中极具价值的数据资源。
实际应用
实际应用中,该数据集被金融机构用于设计风险管理策略,通过分析客户数据,制定相应的信贷政策和营销策略。此外,该数据集也常用于数据挖掘和机器学习竞赛,以促进信用评分模型的创新和发展。
数据集最近研究
最新研究方向
在金融风险管理领域,scikit-learn/credit-card-clients数据集近期的研究焦点主要集中在违约预测模型的构建与优化上。学者们通过深度挖掘数据中的性别、教育背景、婚姻状况等人口统计学特征,以及信用历史和账单信息,探寻预测个人信用违约的强预测因子。这些研究不仅有助于银行和金融机构更准确地评估信贷风险,还为个性化金融产品设计与风险控制策略提供了数据支持。
以上内容由遇见数据集搜集并总结生成


