C4
收藏arXiv2024-08-20 更新2024-08-22 收录
下载链接:
https://github.com/cs32963/REInstruct
下载链接
链接失效反馈官方服务:
资源简介:
C4数据集是由中国信息处理实验室等机构创建的一个大型无标签文本语料库,广泛用于大型语言模型的预训练。该数据集包含约4亿个经过清洗的文本段落,来源于多种高质量的非结构化文本资源。创建过程中,采用了启发式规则筛选出结构良好、内容有价值的部分,并通过生成指令和响应重写的方式提高了数据质量。C4数据集主要应用于大型语言模型的指令调优,旨在提升模型在零样本学习和其他自然语言处理任务中的性能。
The C4 dataset is a large-scale unlabeled text corpus developed by institutions such as the China Information Processing Laboratory, and is extensively utilized for the pre-training of large language models. It contains approximately 400 million cleaned text paragraphs sourced from various high-quality unstructured text resources. During its development, heuristic rules were adopted to screen out well-structured and content-valuable segments, and data quality was improved by generating instructions and rewriting responses. The C4 dataset is mainly applied to the instruction tuning of large language models, aiming to enhance the model's performance in zero-shot learning and other natural language processing tasks.
提供机构:
中国信息处理实验室 软件研究所 中国科学院 中国科学院大学 系统软件重点实验室
创建时间:
2024-08-20
原始信息汇总
REInstruct 数据集概述
REInstruct 是一个用于构建指令数据集的工具,源自 ACL 2024 Findings 论文 "REInstruct: Building Instruction Data from Unlabeled Corpus"。
数据准备
无标签文本准备
- 数据源:C4 数据集(C4 dataset)
- 处理步骤:
- 下载并解压 C4 数据集中的
en文件夹中的文本文件。 - 使用脚本
re_instruct/data/prepare_unlabeled_texts.py选择候选文本。
- 下载并解压 C4 数据集中的
训练数据
- 示例数据:
data/dummy_instruction_data.json
训练
训练脚本
- 硬件要求:8 块 A100-80G GPU
- 训练参数:
- 数据路径:
data/dummy_instruction_data.json - 模型名称或路径:
huggyllama/llama-7b - 最大序列长度:2048
- 输出目录:
exps/dummy_sft - 最大步数:100
- 每设备训练批次大小:1
- 梯度累积步数:16
- 使用 bf16 精度
- 优化器:
adamw_torch - 学习率:2e-5
- 学习率调度器类型:constant
- 使用 FSDP(全分片自动包装)
- 使用 tf32 精度
- 启用梯度检查点
- 报告到 wandb
- 运行名称:
dummy_sft - 日志记录步数:1
- 数据路径:
推理
推理脚本
- 硬件要求:8 块 A100-80G GPU
- 推理参数:
- 数据路径:
data/dummy_instruction_data.json - 模型名称或路径:
<path_to_trained_checkpoint> - 输出目录:
exp_data/dummy_inference - 提示类型:
<prompt_type> - 最大新 tokens:512
- 不进行采样
- 数据路径:
过滤重写响应
过滤脚本
- 过滤步骤:
- 使用脚本
re_instruct/data/filter_rewritten.py过滤失败的重写响应。 - 数据路径:
<path_to_data_for_filtering> - 输出目录:
<output_dir> - 移除拒绝:True
- 使用脚本
太阳爆发可视化
可视化脚本
- 依赖安装:Install required dependency
- 可视化步骤:
- 使用脚本
re_instruct/data/sunburst_visualize.py进行可视化。 - 数据路径:
example.json - 输出 SVG 路径:
example.svg
- 使用脚本
搜集汇总
数据集介绍
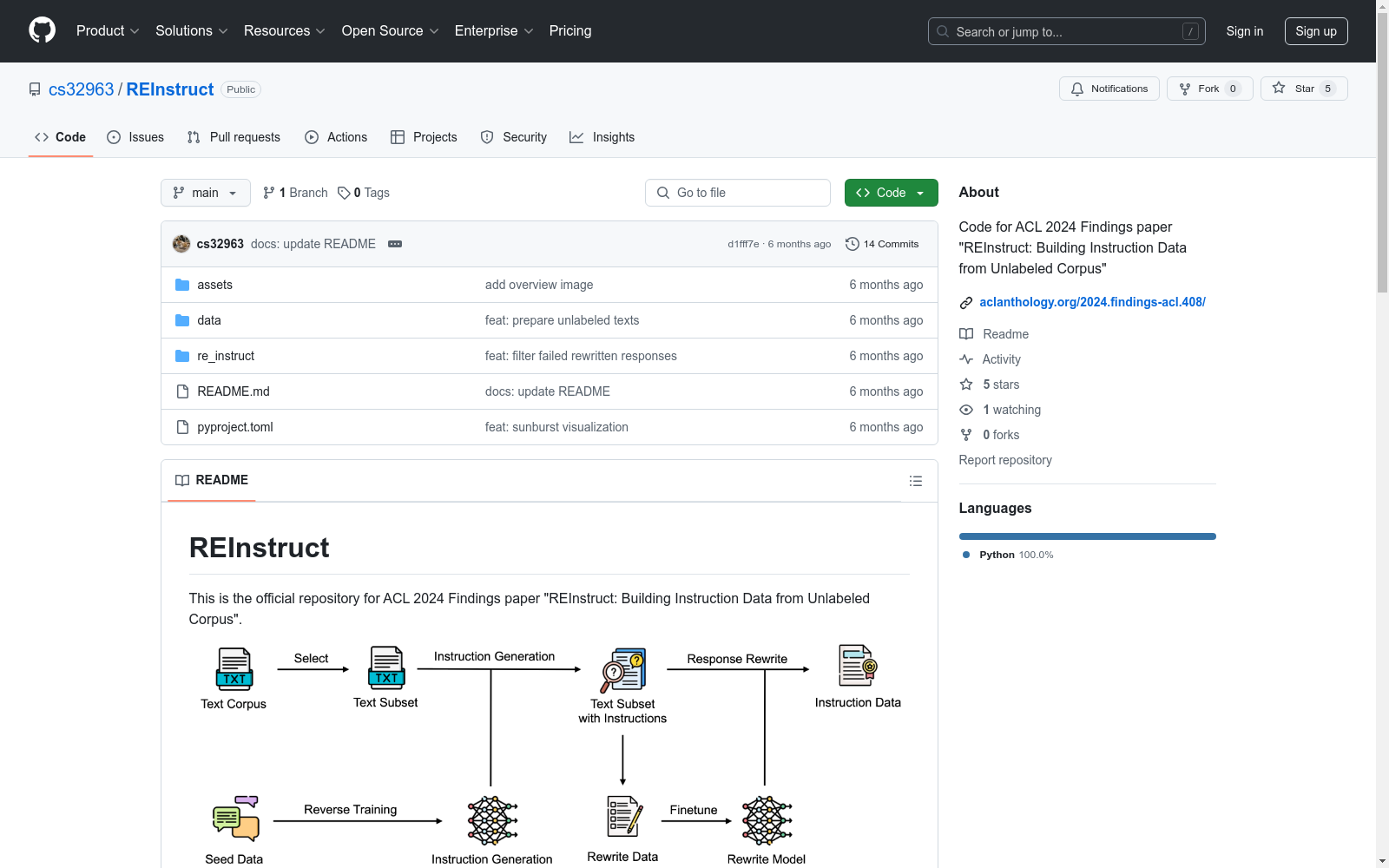
构建方式
C4数据集通过REInstruct方法从无标签的语料库中自动构建指令数据。具体而言,REInstruct首先利用启发式规则筛选出可能包含高质量、结构化内容的未标记文本子集,然后为这些文本生成指令。为了确保生成的指令数据准确且相关,REInstruct进一步采用基于重写的方法来提升生成指令数据的质量。通过结合3k种子数据和32k合成数据,训练后的模型在AlpacaEval排行榜上以65.41%的胜率超越了text-davinci003,表现优于其他开源、非蒸馏的指令数据构建方法。
使用方法
C4数据集适用于需要大规模指令数据进行微调的场景,特别是在需要提升模型指令遵循能力的任务中。用户可以通过REInstruct方法生成的指令数据对预训练语言模型进行微调,以增强其在各种任务上的表现。此外,该数据集的开源性质使得研究者和开发者能够自由访问和使用,进一步推动了指令调优领域的研究和发展。
背景与挑战
背景概述
C4数据集是由中国信息处理实验室(Chinese Information Processing Laboratory)的研究人员于2024年提出的,主要研究人员包括Shu Chen、Xinyan Guan、Yaojie Lu等。该数据集的核心研究问题是如何从无标签的语料库中自动构建指令数据,以减少对大型语言模型(LLMs)的手动标注依赖。C4数据集的提出对自然语言处理领域具有重要影响,特别是在指令调优(Instruction Tuning)方面,为大规模语言模型的训练提供了新的方法和资源。
当前挑战
C4数据集在构建过程中面临多个挑战。首先,自动标注指令数据的质量和多样性受到无标签语料库的限制,如何从海量无标签文本中筛选出高质量的指令数据是一个关键问题。其次,现有的自动标注方法通常依赖于专有的LLMs,这不仅限制了指令数据质量的上限,还可能引发版权问题。此外,如何在不依赖专有LLMs的情况下,确保生成的指令数据具有高准确性和相关性,也是一个亟待解决的难题。
常用场景
经典使用场景
C4数据集的经典使用场景在于自动构建指令数据,通过从无标签的语料库中选择潜在包含高质量结构化内容的文本,并生成相应的指令。这种方法不仅减少了对手动标注的依赖,还避免了使用专有大型语言模型(LLMs)带来的潜在版权问题。通过REInstruct方法,C4数据集能够生成高质量的指令数据,用于训练和微调大型语言模型,从而提升模型在零样本任务中的表现。
解决学术问题
C4数据集通过REInstruct方法解决了手动标注指令数据的高成本和难以扩展的问题。传统的自动标注方法依赖于从专有LLMs中提取合成数据,这不仅限制了指令数据质量的上限,还引发了潜在的版权问题。REInstruct方法通过从无标签语料库中自动构建指令数据,提供了一种简单且可扩展的解决方案,显著降低了标注成本,并为指令调优研究提供了新的可能性。
实际应用
C4数据集在实际应用中主要用于训练和微调大型语言模型,特别是在需要高质量指令数据的场景中。例如,在构建智能助手、聊天机器人或进行多任务学习时,C4数据集能够提供丰富的指令数据,帮助模型更好地理解和执行用户指令。此外,C4数据集还可用于学术研究,推动指令调优技术的发展,提升模型在各种任务中的表现。
数据集最近研究
最新研究方向
在自然语言处理领域,C4数据集的最新研究方向主要集中在自动构建指令数据集的方法上。REInstruct方法通过从未标注的语料库中自动生成指令数据,减少了对专有大型语言模型(LLMs)和人工标注的依赖。该方法首先筛选出可能包含高质量内容的未标注文本子集,然后生成相应的指令。为了提高生成指令数据的质量,REInstruct进一步提出了基于重写的方法。通过在Llama-7b模型上结合3k种子数据和32k合成数据进行微调,该方法在AlpacaEval排行榜上取得了65.41%的胜率,超越了其他开源的非蒸馏指令数据构建方法。这一研究不仅展示了自动构建指令数据的可行性,还为指令调优领域的进一步发展提供了新的思路。
相关研究论文
- 1REInstruct: Building Instruction Data from Unlabeled Corpus中国信息处理实验室 软件研究所 中国科学院 中国科学院大学 系统软件重点实验室 · 2024年
以上内容由遇见数据集搜集并总结生成


