central-bank-communications
收藏Hugging Face2025-12-25 更新2025-12-26 收录
下载链接:
https://huggingface.co/datasets/aufklarer/central-bank-communications
下载链接
链接失效反馈官方服务:
资源简介:
该数据集包含来自九家主要中央银行(美联储、欧洲央行、英格兰银行、日本银行、加拿大银行、中国人民银行、俄罗斯中央银行、尼日利亚中央银行和巴西中央银行)的货币政策声明和决策,每个句子使用GPT-4o在四个维度上进行分类:主题(如通货膨胀、利率、经济活动等)、立场(前瞻性或回顾性)、受众(金融部门、商业部门、公众等)和情感(鹰派、鸽派、中性等)。数据集提供了详细的分类标准,并包含两个数据文件:documents.jsonl(完整文档文本及元数据)和sentences.jsonl(带分类的单个句子)。
创建时间:
2025-12-25
原始信息汇总
中央银行通信数据集概述
数据集基本信息
- 许可证: CC-BY-4.0
- 任务类别: 文本分类
- 语言: 英语
- 规模: 10K<n<100K
- 标签: 中央银行、货币政策、经济学、自然语言处理、美联储、欧洲中央银行、英格兰银行、日本银行、加拿大银行、中国人民银行、俄罗斯中央银行、尼日利亚中央银行、巴西中央银行
数据集描述
该数据集包含来自九家主要中央银行的货币政策声明和决策,其中每个句子都使用GPT-4o在四个维度上进行了分类:
- 主题: 句子涉及的内容
- 立场: 时间导向
- 受众: 目标受众
- 情感: 政策倾向
分类体系
主题(货币政策)
mp_inflation: 价格稳定、通胀目标mp_interest_rate: 政策利率决策mp_economic_activity: GDP、增长前景mp_exchange_rate: 汇率考量mp_labor_market: 就业、工资mp_balance_sheet: 量化宽松、资产购买mp_credit: 信贷条件mp_open_market_ops: 市场操作mp_reserve_requirements: 银行准备金
主题(其他)
financial_stability: 系统性风险fiscal_policy: 政府支出governance: 中央银行运营- 以及其他类别
立场
forward_looking: 未来计划、预期、指引backward_looking: 过去/当前状况、数据
受众
financial_sector: 银行、投资者business_sector: 公司、行业general_public: 公民、消费者government: 财政当局international_stakeholders: 外国实体
情感
hawkish: 紧缩倾向dovish: 宽松倾向neutral: 平衡risk_highlighting: 风险警告confidence_building: 安抚语气
数据文件
documents.jsonl: 包含元数据的完整文档文本sentences.jsonl: 带有分类的单个句子
使用方法
python from datasets import load_dataset
加载带有分类的句子(默认)
sentences = load_dataset("aufklarer/central-bank-communications", "sentences")
加载完整文档
documents = load_dataset("aufklarer/central-bank-communications", "documents")
筛选鹰派的美联储声明
hawkish_fed = sentences["train"].filter(lambda x: x["central_bank"] == "fed" and x["sentiment"] == "hawkish")
方法论参考
分类体系基于国际货币基金组织工作文件WP/25/109:"From Text to Quantified Insights: A Large-Scale LLM Analysis of Central Bank Communication"
搜集汇总
数据集介绍
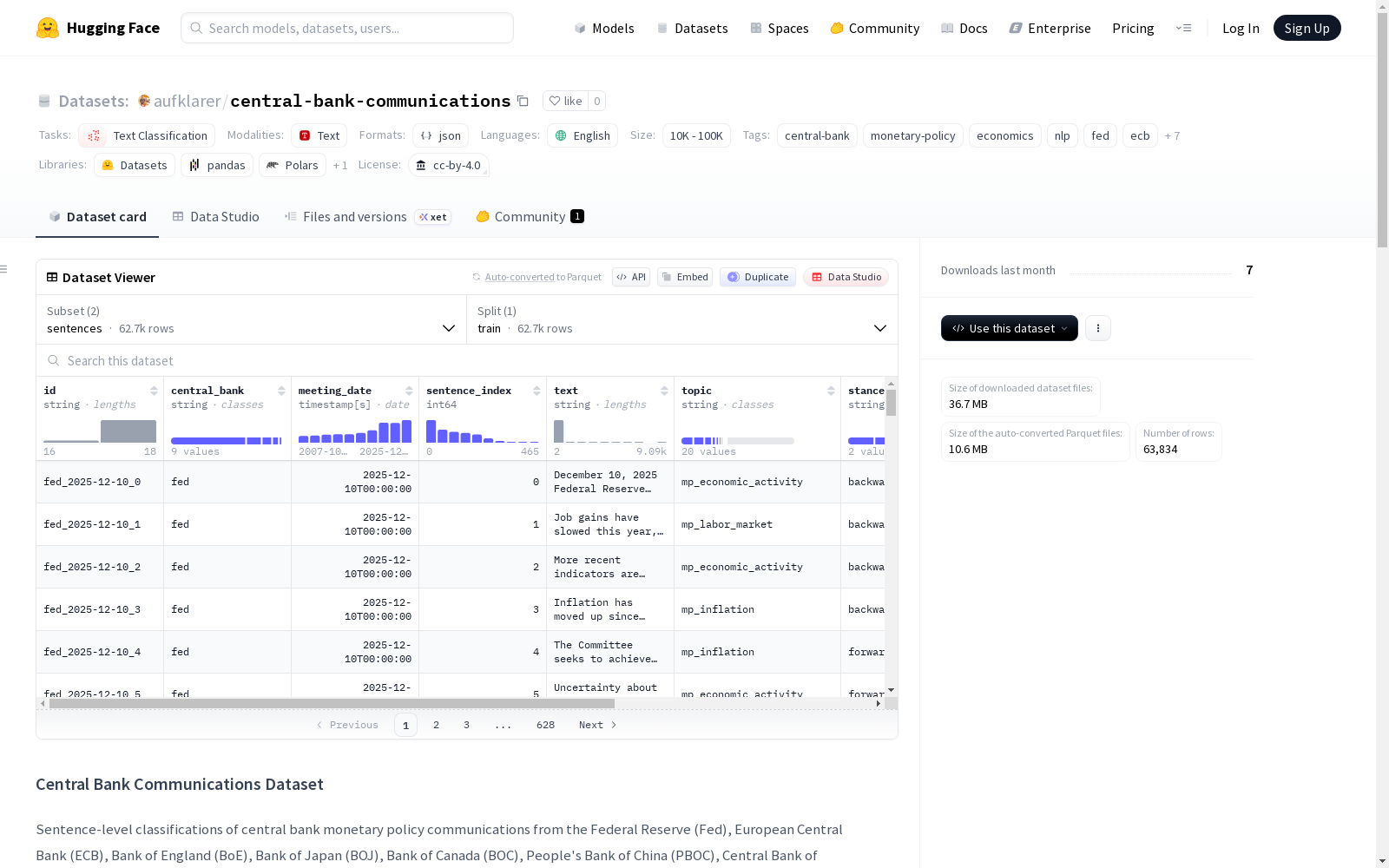
构建方式
在货币政策分析领域,中央银行的公开声明是理解政策意图和市场预期的重要文本来源。本数据集系统性地收集了包括美联储、欧洲中央银行、英格兰银行等九家主要中央银行发布的货币政策声明与决策文件,并通过先进的GPT-4o模型对每个句子进行了精细的多维度标注。构建过程首先整合了来自各央行官方网站的原始文档,随后利用大语言模型自动化地识别句子边界,并依据国际货币基金组织工作论文中提出的分类框架,为每个句子赋予主题、立场、受众和情感倾向四个层面的结构化标签,从而将非结构化的政策文本转化为可供量化研究的标准化数据。
特点
该数据集的核心特征在于其多层次、细粒度的分类体系。它不仅涵盖了通货膨胀、利率、经济活动等经典货币政策主题,还扩展至金融稳定、财政政策等关联领域,为宏观金融研究提供了宽广的视角。每个句子均被标注了前瞻性或回顾性的时间立场,明确了其面向金融部门、企业或公众等不同受众的指向,并识别出鹰派、鸽派、中性等揭示政策偏好的情感色彩。这种多维标注结构使得研究者能够深入剖析央行沟通的策略、透明度及其对市场的异质性影响,数据集规模介于一万至十万条之间,确保了分析的统计效力与代表性。
使用方法
利用该数据集进行研究,用户可通过Hugging Face的`datasets`库便捷加载。数据集提供句子和文档两种配置:`sentences.jsonl`包含带有完整分类标签的独立句子,适用于基于句子的文本分类、情感分析或主题建模任务;`documents.jsonl`则保留了原始文档的完整文本与元数据,适合进行文档级的整体分析或上下文关联研究。研究人员可以轻松执行过滤操作,例如提取特定央行的鹰派表态语句,从而构建时间序列指标、进行跨国比较或训练预测模型,以实证检验央行沟通的有效性与市场反应。
背景与挑战
背景概述
中央银行沟通数据集由研究人员于近年构建,旨在系统分析全球主要央行货币政策声明中的文本信息。该数据集涵盖了美联储、欧洲央行、中国人民银行等九家重要中央银行的官方文件,通过GPT-4o模型对每个句子进行了多维度标注,包括主题、立场、受众和情感倾向。其核心研究问题聚焦于如何从非结构化的政策文本中提取结构化信息,以量化分析央行的政策意图和市场沟通策略。这一数据集为货币经济学、金融文本挖掘以及政策效果评估等领域提供了重要的实证基础,推动了自然语言处理技术在宏观经济分析中的应用,增强了学术界与市场参与者对央行前瞻性指引的理解能力。
当前挑战
该数据集致力于解决中央银行沟通文本的自动化解析与量化挑战,其核心问题在于如何准确识别政策声明中的细微语义差异,例如区分鹰派与鸽派倾向,或界定前瞻性与回顾性表述。构建过程中的主要挑战包括:一是央行文本具有高度的专业性与语境依赖性,需设计精细的分类体系以涵盖通胀、利率、经济活力等多重主题;二是不同央行的沟通风格与术语存在显著差异,要求标注模型具备跨机构的泛化能力;三是确保大规模自动标注的准确性与一致性,避免因模型幻觉或偏见引入噪声,从而保证数据在学术研究与政策分析中的可靠性。
常用场景
经典使用场景
在货币经济学与自然语言处理交叉领域,中央银行的沟通文本是理解政策意图和市场信号的关键载体。该数据集通过精细的句子级标注,为研究者提供了分析央行货币政策声明中主题、立场、受众和情感倾向的统一框架。经典应用场景包括训练机器学习模型,以自动识别和分类央行文件中的政策导向,例如从美联储或欧洲央行的声明中提取关于通胀预期的前瞻性指引,从而量化政策语言的细微变化。这为宏观经济预测和文本分析研究奠定了高质量的数据基础。
解决学术问题
该数据集有效解决了中央银行沟通研究中长期存在的文本量化难题。传统上,学者依赖人工编码或简单关键词匹配来解读政策文本,这种方法既耗时又难以保证一致性。本数据集利用先进的LLM技术,提供了大规模、多维度、跨央行的标准化标注,使研究人员能够系统考察货币政策传递的透明度、一致性及其对市场预期的影响。它促进了关于央行沟通策略、政策信号有效性以及文本情感与金融市场反应关联的实证研究,推动了计算经济学与政策分析方法的融合。
衍生相关工作
围绕该数据集,已衍生出一系列重要的学术与实务工作。其分类体系直接参考了国际货币基金组织(IMF)的工作论文,为后续研究提供了权威的理论基础。相关经典工作包括利用该数据训练专门的Transformer模型,以预测利率决议或市场波动率;也有研究将其与高频金融数据结合,实证检验央行沟通对债券收益率或汇率的影响机制。此外,该数据集还催生了针对新兴市场央行(如巴西、尼日利亚)沟通特点的比较分析,拓展了全球货币政策研究的地理覆盖与理论视野。
以上内容由遇见数据集搜集并总结生成


