ibm-research/VAKRA
收藏Hugging Face2026-03-31 更新2026-04-05 收录
下载链接:
https://hf-mirror.com/datasets/ibm-research/VAKRA
下载链接
链接失效反馈官方服务:
资源简介:
---
license: cc-by-nc-sa-4.0
task_categories:
- question-answering
- text-retrieval
- text-generation
language:
- en
tags:
- LLM Agent
- tool-calling
- multi-hop
- multi-source
- rag
size_categories:
- 1K<n<10K
configs:
- config_name: multihop_multisource_with_policies
data_files:
- split: input
path:
- test/capability_4_multiturn/input/*.json
- split: output
path:
- test/capability_4_multiturn/input/*.json
- config_name: multihop_reasoning
data_files:
- split: input
path:
- train/capability_3_multihop_reasoning/input/*.json
- split: output
path:
- train/capability_3_multihop_reasoning/output/*.json
- config_name: tool_chaining
data_files:
- split: input
path:
- train/capability_1_bi_apis/input/*.json
- split: output
path:
- train/capability_1_bi_apis/output/*.json
- config_name: tool_selection
data_files:
- split: input
path:
- train/capability_2_dashboard_apis/input/*.json
- split: output
path:
- train/capability_2_dashboard_apis/output/*.json
---
# 🔷 VAKRA: A Benchmark for Evaluating Multi-Hop, Multi-Source Tool-Calling Capabilities in AI Agents
**VAKRA** (e**V**aluating **A**PI and **K**nowledge **R**etrieval **A**gents using multi-hop, multi-source dialogues) is a tool-grounded, executable benchmark designed to evaluate how well AI agents reason end-to-end in enterprise-like settings.
Rather than testing isolated skills, **VARKA** measures compositional reasoning across APIs and documents, using full execution traces to assess whether agents can reliably complete multi-step workflows, not just individual steps. **VARKA** provides an executable environment where agents interact with over 8,000 locally hosted APIs (sourced from LiveAPIBench[1]) backed by real databases (sourced from BIRD-SQL[2]) spanning 62 domains, along with domain-aligned document collections (sourced from CLAPnq[3] and Wikidata5M[4]).
---
## ✨ Key Features
- 🔧 **8,000+ executable APIs** backed by real databases across **62 domains**
- 🔁 **Multi-hop reasoning (3–7 steps)** combining API calls and document retrieval
- 📚 **Cross-source grounding** via structured APIs + unstructured documents
- 📏 **Trace-level verification** with replayable execution paths
- 🔒 **Deterministic evaluation** using locally hosted tools
---
## 🔗 Resources
- 🏆 **Leaderboard:** [https://ibm-research-vakra.hf.space/](https://ibm-research-vakra.hf.space/)
- 🛠 **Environment & Setup:** [github.com/ibm/vakra/setup.md](https://github.com/IBM/vakra/blob/main/setup.md)
- 📊 **Evaluation & Scoring:** [github.com/ibm/vakra](https://github.com/IBM/vakra)
---
## 🧩 Benchmark Structure
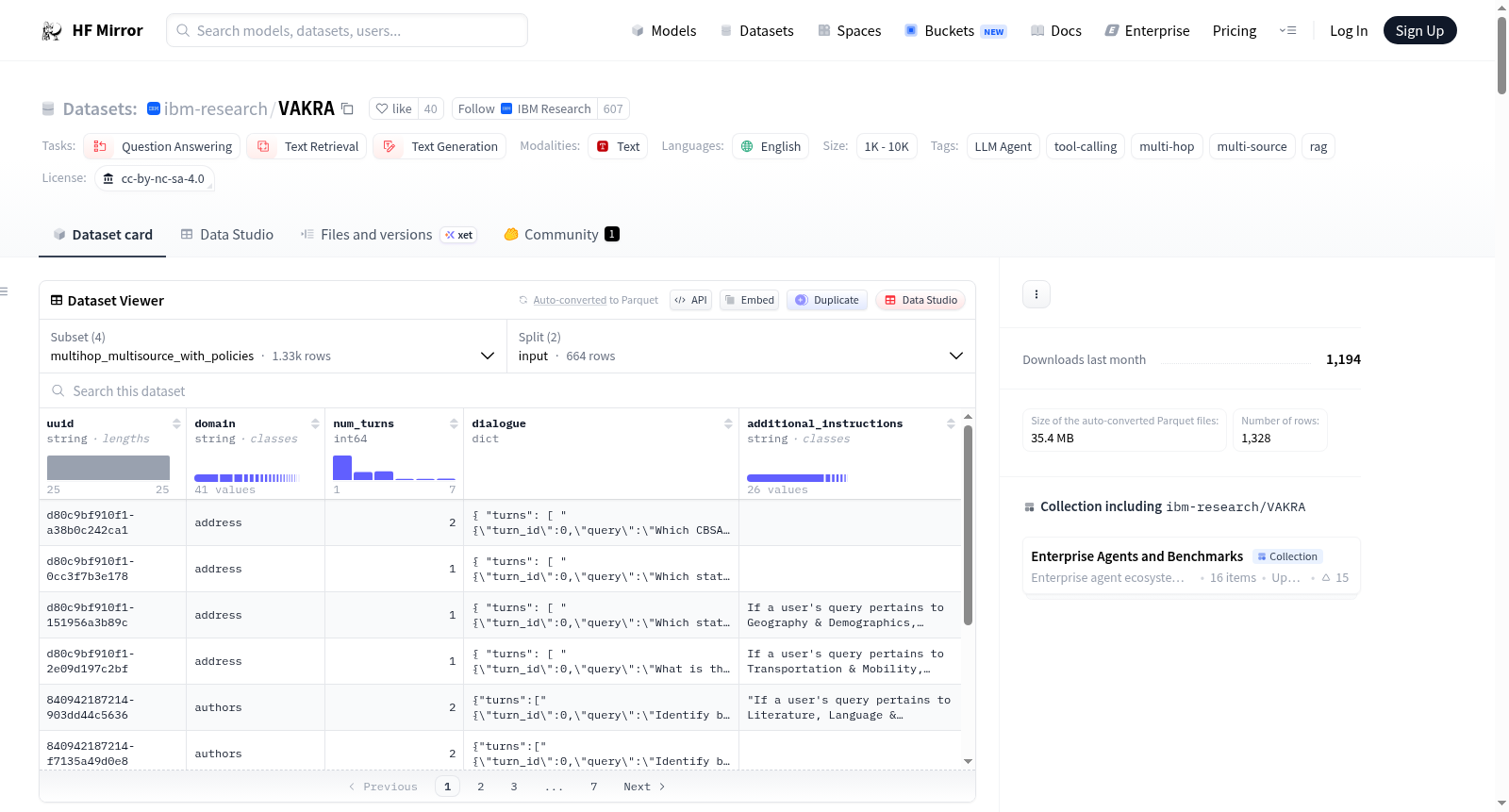
VAKRA organizes evaluation into four capabilities, which together reflect three progressively complex settings. The dataset viewer shows a snippet of the train dataset.
### 1. Diverse API Interaction Styles
These tasks focus on structured tool use over APIs with different interface abstractions.
- `capability_1_bi_apis` (API Chaining): nested and compositional API chaining
- `capability_2_dashboard_apis` (Tool Selection): large-scale tool selection over query-aligned endpoints
### 2. Multi-hop Reasoning over Structured APIs
These tasks require dependent reasoning chains over APIs, where earlier outputs must be interpreted and transformed for later calls.
We have single-turn queries that can be answered by a reasoning chain of 1–3 APIs. For example, a sample may be answered by a single API (API), or by two APIs where the output of API₁ is transformed and passed to API₂ (API₁ → API₂), or by three APIs (API₁ → API₂ → API₃).
- `capability_3_multihop_reasoning` (Multihop API Reasoning)
### 3. Multi-hop, Multi-source Reasoning with Tool-use Policies
These tasks combine reasoning over APIs and document retrieval in a multi-turn setting and also include natural-language constraints about tool use.
We have multi-turn dialogues represented as context-response-pairs wherein queries could be answered by a reasoning chain of 1-4 tools (ex., a three-turn dialogue "(API)(RAG)(API-RAG)" wherein using the context from the first two turns, an answer needs to be obtained for the (API-RAG) turn.)
- `capability_4_multiturn` (MultiHop MultiSource with Policy Adherence)
This represents the most challenging setting, mirroring decision workflows.
---
## 📊 Dataset Statistics
### 🧪 Training Split
| Capability | Description | Domains | Samples | Avg Tool Calls | Max Tool Calls | Avg Turns | Max Turns |
|------------|------------|---------|---------|----------------|----------------|-----------|-----------|
| Capability_1 | API Chaining | 33 | 1,324 | 4.05 | 12 | — | — |
| Capability_2 | Tool Selection | 40 | 1,860 | 1.00 | 1 | — | — |
| Capability_3 | Multihop API Reasoning | 28 | 346 | 2.05 | 3 | — | — |
| Capability_4 | MultiHop MultiSource with Policy Adherence | 36 | 898 | 1.05 | 3 | 2.06 | 5 |
---
### 🧪 Test Split
| Capability | Description | Domains | Samples | Avg Tool Calls | Max Tool Calls | Avg Turns | Max Turns |
|------------|------------|---------|---------|----------------|----------------|-----------|-----------|
| Capability_1 | API Chaining | 54 | 2,077 | 3.96 | 10 | — | — |
| Capability_2 | Tool Selection | 17 | 1,597 | 1.00 | 1 | — | — |
| Capability_3 | Multihop API Reasoning| 38 | 869 | 2.04 | 5 | — | — |
| Capability_4 | MultiHop MultiSource with Policy Adherence | 41 | 644 | 1.34 | 4 | 2.01 | 7 |
---
## 📁 Directory Structure
```
<base_path>/
├── indexed_documents/
├── databases/
│ └── <domain>/
│ ├── database_description/
│ └── domain.sqlite
├── test/
│ └── capability-X/
│ └── input/
└── train/
└── capability-X/
├── input/
└── output/
```
---
## 🧪 Dataset Format
Following is an example of the input & output structure of the dataset.
### Input Sample
```json
{
"uuid": "str",
"domain": "str",
"num_turns": 2,
"dialogue": {
"turns": [
{
"turn_id": 0,
"query": "str",
"answer": `str | list | int | float` # Only present for historical-turns in capability_4_multiturn
},
{
"turn_id": 1,
"query": "str"
}]},
"additional_instructions": "str" # This field is only present for capability_4_multiturn
}
```
Expected datatypes:
- `uuid`: `str`
- `domain`: `str`
- `num_turns`: `int`
- `dialogue.turns`: `list`
- `turn_id`: `int`
- `query`: `str`
- `answer` in historical turns: `str | list | int | float`
- `additional_instructions`: `string`
Notes:
- In `capability_*/input`, all historical turns can have `answer`, but the last turn must not have `answer`.
- In non-multiturn input files, `additional_instructions`, historical-turn would be absent as they are single turn dialogues.
---
### 🔹 Output Schema
```json
{
"uuid": "str",
"domain": "str",
"output": [
{
"turn_id": 0,
"query": "str",
"answer": "str",
"sequence": {
"tool_call": [
{
"name": "str",
"arguments": {
"key": "value"
}
}
],
"tool_response": [
{
"name": "str",
"response": {
"key": "value"
}}]}}],
"additional_instructions": "str"
}
```
Expected datatypes:
- `uuid`: `str`
- `domain`: `str`
- `output`: `list`
- `turn_id`: `int`
- `query`: `str`
- `answer`: `str | list | int | float`
- `sequence`: `dict`
- `sequence.tool_call`: `list`
- `sequence.tool_response`: optional, typically `list`
- `additional_instructions`: `string` for `capability_4_multiturn/output`
---
## 🚀 Getting Started
Follow the instructions - [github.com/ibm/vakra/setup.md](https://github.com/IBM/vakra/blob/main/setup.md) to download the dataset and set up the repository.
---
## 🏁 Evaluation & Scoring
Evaluation code, scoring scripts, and field exclusion lists are maintained at:
**[github.com/ibm/vakra](https://github.com/IBM/vakra)**
The benchmark uses a waterfall judge consisting of three judges
- **PolicyJudge:** Programmatically evaluates the adherence to policy.
- **ExactMatchJudge:** Programmatically evaluates an order-invariant exact match (subset-based) between the predicted tool responses and ground truth tool responses.
- **GroundednessJudge:** LLM-as-a-Judge evaluating the groundedness of an answer to the tool responses and query.
👉 Full details of judging criteria: **[github.com/ibm/vakra](https://github.com/IBM/vakra)**
---
## 🤝 Contributing
To submit results, create a GitHub issue using the
👉 Leaderboard Submission Template:
https://github.com/IBM/vakra/issues/new?template=leaderboard_submission.yml
To contact the author, create a GitHub issue using https://github.com/IBM/vakra/issues/new?template=leaderboard_submission.md
---
## References
- [1] Elder, Benjamin, et al. "Live API-Bench: 2500+ Live APIs for Testing Multi-Step Tool Calling." Proceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers). 2026.
- [2] Li, Jinyang, et al. "Can llm already serve as a database interface? a big bench for large-scale database grounded text-to-sqls." Advances in Neural Information Processing Systems 36 (2023): 42330-42357.
- [3] Rosenthal, Sara, et al. "CLAPnq: C ohesive L ong-form A nswers from P assages in Natural Questions for RAG systems." Transactions of the Association for Computational Linguistics 13 (2025): 53-72.
- [4] Wang, Xiaozhi, et al. "KEPLER: A unified model for knowledge embedding and pre-trained language representation." Transactions of the Association for Computational Linguistics 9 (2021): 176-194.
- [5] Shlomov, Segev, et al. "From Benchmarks to Business Impact: Deploying IBM Generalist Agent in Enterprise Production." Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 40. No. 47. 2026.
## Acknowledgments
We especially acknowledge Chulaka Gunasekara, Hamid Adebayo, Harold Ship, Himanshu Gupta, Huaiyu Zhu, Jaydeep Sen, Nir Mashkif, Renuka Sindhgatta, Sameep Mehta, Sara Rosenthal, and Segev Shlomov for their contributions and insights.
We also thank our interns, Raavi Gupta and Abhinav Jain, for their efforts in benchmark generation and development.
## Citation
```
@misc{vakra,
title={VAKRA: A Benchmark for Evaluating Multi-Hop, Multi-Source Tool-Calling Capabilities in AI Agents},
author={Ankita Rajaram Naik*, Anupama Murthi*, Benjamin Elder*, Siyu Huo*, Praveen Venkateswaran, Danish Contractor},
year={2026},
url={https://huggingface.co/spaces/ibm-research/VAKRA},
}
```
_* Equal contributions_
提供机构:
ibm-research
搜集汇总
数据集介绍
构建方式
在人工智能代理工具调用能力评估领域,VAKRA数据集的构建体现了严谨的工程化设计理念。该数据集通过整合来自LiveAPIBench的真实可执行API、BIRD-SQL的数据库以及CLAPnq和Wikidata5M的文档集合,构建了一个覆盖62个领域、包含超过8000个API的仿真企业环境。其构建过程以多跳推理和多源检索为核心,将任务组织为四个渐进式复杂的能力模块,每个模块均包含结构化的输入输出对,并确保所有工具调用轨迹可在本地环境中确定性地重放与验证。
特点
VAKRA数据集的核心特征在于其对企业级复杂工作流的深度模拟。数据集提供了从简单API链式调用到融合结构化API与无结构文档的多轮、多源推理的完整谱系,其中任务步骤可达七步,要求智能体进行组合式推理。其独特之处在于引入了工具使用策略的自然语言约束,并采用轨迹级验证机制,通过可重放的执行路径对代理的端到端推理能力进行确定性评估,而非孤立地测试单项技能。
使用方法
使用VAKRA数据集进行模型评估,需遵循其预设的标准化流程。研究者首先需按照官方指南配置本地执行环境,加载相应的数据库与文档索引。评估时,模型需处理以JSON格式提供的多轮对话输入,生成包含具体工具调用序列及参数的回答。系统随后通过策略符合性、精确匹配和答案基于工具响应的真实性这三重评判机制,对模型输出的完整执行轨迹进行自动化评分,从而全面衡量其在复杂、真实场景下的工具调用与推理能力。
背景与挑战
背景概述
在人工智能代理技术快速演进的背景下,对复杂任务中多步骤推理与多源信息整合能力的评估需求日益凸显。VAKRA数据集由IBM研究院等机构的研究人员于2026年创建,旨在系统评估AI代理在企业级场景下的端到端推理能力。该数据集的核心研究问题聚焦于如何精准衡量代理在结合结构化API调用与非结构化文档检索的多跳、多源工作流中的表现。通过整合超过8000个可执行API、真实数据库及领域对齐文档集合,VAKRA为智能代理的复合推理能力设定了新的评估标准,对推动具身智能与工具调用研究的发展具有重要影响力。
当前挑战
VAKRA数据集致力于解决智能代理在复杂环境中进行多跳、多源工具调用的核心挑战,这要求模型不仅需精准选择与序列化调用多个API,还需在结构化数据与非结构化文本间进行交叉验证与信息融合。构建过程中的挑战尤为显著,涉及大规模异构资源的集成,包括从LiveAPIBench、BIRD-SQL等多个基准协调API、数据库与文档,并确保其可执行性与领域一致性。此外,设计能够反映真实企业决策流程的多轮对话与策略约束任务,同时建立具有确定性且可复现的轨迹级评估框架,均是数据集构建中需要克服的关键难题。
常用场景
经典使用场景
在人工智能代理研究领域,VAKRA数据集被广泛用于评估模型在复杂企业级环境中的多跳、多源工具调用能力。该数据集通过模拟真实工作流程,要求代理在结构化API与无结构文档之间进行组合推理,执行包含三至七个步骤的端到端任务。经典使用场景包括测试代理能否在跨域API链式调用中准确解析中间结果,并依据自然语言策略约束,在对话式交互中整合检索增强生成技术,以完成依赖多轮上下文的决策任务。
衍生相关工作
围绕VAKRA数据集,学术界与工业界已衍生出一系列经典研究工作。这些工作主要集中于扩展多模态工具调用基准、开发更鲁棒的轨迹验证方法,以及探索混合推理框架在受限环境下的优化策略。部分研究借鉴VAKRA的评估范式,构建了面向垂直领域的专用评测集;另一些工作则利用其提供的执行路径数据,训练具备更强泛化能力的序列决策模型,进一步推动了工具增强型代理在动态环境中的部署与应用。
数据集最近研究
最新研究方向
在大型语言模型智能体研究领域,VAKRA数据集正推动着多跳、多源工具调用能力评估的前沿探索。该数据集通过整合超过8000个可执行API与真实数据库,并融合非结构化文档检索,构建了模拟企业级决策流程的复杂环境。当前研究聚焦于智能体在长链条推理任务中的组合式泛化能力,特别是在跨模态工具链编排与策略约束遵从方面的表现。随着检索增强生成与工具学习技术的融合,VAKRA为评估智能体在动态环境下的端到端工作流完成度提供了标准化基准,其多层级验证机制正成为衡量工业级智能体可靠性的重要标尺。
以上内容由遇见数据集搜集并总结生成


