mirea-tl-eda
收藏Hugging Face2026-01-18 更新2026-01-19 收录
下载链接:
https://huggingface.co/datasets/complicat9d/mirea-tl-eda
下载链接
链接失效反馈官方服务:
资源简介:
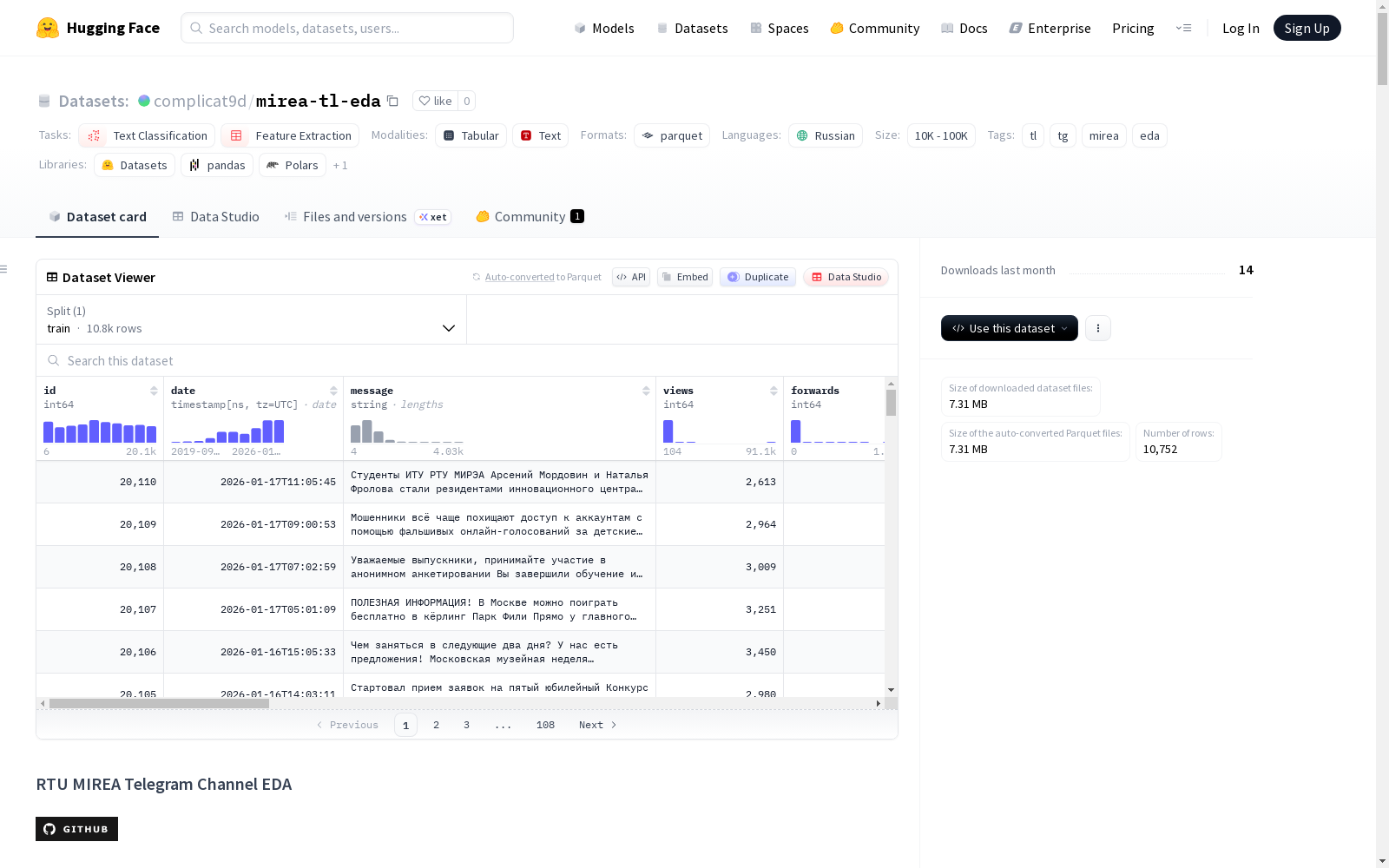
该数据集包含22个指标,描述了RTU MIREA Telegram频道在整个分析时间段内(超过1万条文本消息)的帖子用户参与度、语言单位特征、可读性、AI消息生成分数、语义主题标签和模型标签置信度。数据集是通过对RTU MIREA Telegram频道的数据进行探索性数据分析(EDA)得到的,数据通过aiogram获取。预处理步骤包括数据清理(去除表情符号、标签、多余空格)、过滤至少包含一个单词的消息,以及扁平化字典结构。分析涵盖了用户参与度指数、语言单位特征(如句法复杂性、音节频率)、可读性和年级水平指数、AI生成分数(基于困惑度和突发性)以及主题分类(使用17个标签的文本分类模型)。
创建时间:
2026-01-12
原始信息汇总
RTU MIREA Telegram Channel EDA 数据集概述
数据集基本信息
- 任务类别: 文本分类、特征提取
- 语言: 俄语 (ru)
- 标签: tl, tg, mirea, eda
- 规模: 10K < n < 100K
- 配置文件: default
- 数据文件: data/frames/*.parquet
- 数据集全称: I analysed RTU MIREA Telegram messages, so you wouldnt have to
数据来源与内容
- 数据来源于 RTU MIREA Telegram channel,通过 aiogram 获取。
- 包含分析时整个可用时间段(超过 1 万条文本消息)的 22 项指标。
- 指标涵盖:帖子用户参与度、语言单元特征、可读性、AI 消息生成分数、语义主题标签以及模型标注置信度。
数据预处理与特征工程
原始数据与清洗
- 从 Telegram API 获取的消息原始字段包括:id、date、views、forwards、replies、reactions。
- 消息经过清洗(移除表情符号、标签、多余空格),并过滤至少包含一个单词的消息。
- 字典类结构被扁平化处理。
用户参与度指标
- 使用转发、反应和回复相对于浏览量的千分比构建基础指标:F₁ₖ、R₁ₖ、P₁ₖ。
- 定义参与度指数 (EI):EI = 0.25 × F₁ₖ + 0.35 × R₁ₖ + 0.40 × P₁ₖ。
- 为保持指数在添加新数据时的历史可比性,未进行任何归一化处理。
语言单元特征
可读性与年级水平指数
- 采用适用于俄语的 Flesch-Kincaid 可读性指数、Flesch-Kincaid 年级水平指数和 LIX 指数。
- 计算公式:
- FK_R = (206.835 - 1.52W - 65.14S)_clip(0,100)
- LIX = W + 100L
- FK_G = (0.5W + 11.8S - 15.59)_clip(0,100)
- 其中:W = 每句平均词数,S = 每词平均音节数,L = 长词比例(字符数 > 6 的词)。
AI 生成分数
- 使用困惑度和句子突发性来评估文本是否为 AI 生成。
- 困惑度:基于 rugpt3 large model 计算。
- 突发性:B = (σ_L / μ_L) × 100%,其中 μ_L 为平均句子长度,σ_L 为句子长度的标准差。
- 分数计算:对困惑度和突发性进行归一化后,按公式 S = 1 - (0.7p + 0.3b) 计算 AI 分数。
- 判定阈值:使用 AI 分数分布的 75% 分位数作为判定消息是否可能由 AI 生成的阈值。
- 局限性说明:由于句子边界难以确定,突发性值可能存在偏差。困惑度分数仅适用于自回归语言模型,其泛化能力有限,与突发性结合使用有助于缓解此问题。
主题分类
- 使用包含 17 个标签的文本分类 模型 对消息进行主题分类。
- 该模型基于 RTU MIREA Telegram 频道的 1000 条已标注消息训练而成。
- 输出包含主题标签及对应的置信度分数。
关键分析发现摘要
帖子长度与参与度随时间变化
- 帖子发布随时间推移变得每日化、规律化,帖子总长度呈上升趋势。
- 帖子长度与用户参与度之间没有明确相关性。
- 用户参与度未显示明显趋势,处于停滞状态。
语言特征
- 词性分布:名词和完整形容词占据了所有词汇的主体,其他词性对帖子语义贡献不大。
- 词云与二元词组网络:高频词和二元词组主要与特定领域相关(如 РТУ, МИРЭА, студент, проект, Россия)。"война"一词主要出现在“伟大卫国战争”的语境中。
- 齐夫曲线分析:语料库略微偏离自然语言。类符-形符比约为 8%,表明文本重复性高;单次词比例达 46%。这些异常可由领域特异性(Telegram 消息和 RTU MIREA 特定术语)解释。
可读性与年级水平
- 由于句子边界确定困难、文本较短(非这些指数的原始设计用途)以及俄语特性未被完全考虑,所有指数的分布都相当偏斜。
- 大约 50% 的消息非常难读,需要教授级别的学位才能理解。
主题分类与参与度
- 高参与度主题:评分相关内容的参与度指数最高(6.62);“其他”类别(难以分类的消息)次之(6.01)。
- 中等参与度主题:一般公告和爱国主义主题消息(约 5.90)。
- 高频但中等参与度主题:社交内容(数量最多,1394 条),参与度为 5.25。
- 较低参与度主题:教育和学术内容(4.23-4.04)、竞赛公告(3.59)、天气预报(3.04)。
- 总体规律:参与度与内容数量呈反比关系:消息较少的类别往往获得更高的单条参与度。
AI 生成分数分布
- 高 AI 参与度主题:国际关系(38.3%)、爱国主义消息(35.6%)。
- 中等 AI 参与度主题:摘要(33.1%)、奖学金信息(31.7%)、志愿活动内容(27.9%)、科学通讯和招生相关内容(约 27%)。
- 低 AI 参与度主题:社交内容(23.0%)、公告(25.8%)、评分相关内容(15.9%)、“其他”类别(13.2%)、体育内容(13.0%)、天气预报(10.3%)。
- 最低 AI 参与度主题:网络安全通信(9.95%)。
相关资源
- GitHub 仓库: https://github.com/complicat9d/mirea-tl-eda
- 数据处理完整代码: 位于上述 GitHub 仓库中。
搜集汇总
数据集介绍
构建方式
在社交媒体分析领域,RTU MIREA Telegram Channel EDA数据集通过系统化的数据采集与多维度处理流程构建而成。研究团队利用aiogram框架从RTU MIREA官方Telegram频道获取原始消息数据,涵盖消息ID、发布时间、浏览数、转发量等基础元数据。经过数据清洗阶段移除表情符号、标签及冗余空格后,采用razdel工具进行俄语句子边界识别,结合pyphen和pymorphy3分别实现音节划分与词形还原。核心创新体现在构建22项量化指标的计算体系,包括基于转发率、互动率、回复率加权合成的用户参与度指数,适配俄语文本的弗莱士可读性指数与LIX复杂度指标,以及基于rugpt3大语言模型困惑度与句子突发性特征融合的AI生成概率评分。
特点
该数据集呈现出多模态特征融合的显著特点,在万余条俄语Telegram消息基础上衍生出四维分析体系。结构特征方面,既包含基础的文本统计指标,又整合了句法复杂度、语篇分割等深层语言学特征。评估维度上,同时涵盖人类可读性评估与机器生成概率检测的双重标准,其中AI评分机制创新性地结合了语言模型困惑度与句子长度变异系数。领域适应性体现在专门针对俄语语法特性调整的可读性计算公式,以及基于实际标注数据训练的17分类主题识别模型。数据分布特性通过词云可视化、齐夫定律曲线分析揭示了机构社交媒体用语的高度领域特异性与词汇重复模式。
使用方法
该数据集为社交媒体计算分析提供了标准化研究框架,使用者可通过parquet格式数据文件直接访问22项预处理指标。在文本分类任务中,研究者可基于预标注的17类主题标签及其置信度分数,开展机构社交媒体内容策略的横向比较研究。特征提取应用时,多维语言学指标与参与度指数的耦合关系可用于构建消息传播效果预测模型。对于人工智能生成文本检测领域,数据集提供的AI评分阈值与突发性特征为开发跨语言生成文本识别算法提供了基准数据。可视化组件包含的词频分布、二元网络等分析图表,可直接支撑社交媒体内容生态的纵向演变研究。
背景与挑战
背景概述
mirea-tl-eda数据集由RTU MIREA的研究者于近期构建,专注于对RTU MIREA官方Telegram频道进行探索性数据分析。该数据集涵盖了超过一万条俄语文本消息,通过22项指标深入剖析用户参与度、语言特征、可读性、AI生成概率及语义主题分类。其核心研究问题在于揭示社交媒体中机构官方频道的沟通模式与受众互动机制,为计算语言学与社会计算领域提供了宝贵的实证语料,尤其对俄语环境下的自然语言处理与数字人文研究具有显著参考价值。
当前挑战
该数据集旨在解决社交媒体文本分析中用户参与度量化与内容特征解析的挑战,其构建过程面临多重困难。在领域层面,Telegram消息的非正式书写风格导致句法结构异质,标点使用不一致,为句子边界识别与语言单位分割带来障碍;同时,俄语特有的语言特性使得传统可读性指标需重新适配,而短文本语境下这些指标的适用性亦存疑。在构建技术层面,AI生成分数的评估依赖于单一自回归语言模型的困惑度,其泛化能力有限,且句长突现性的计算受制于分割准确性;主题分类模型虽经微调,但标注数据规模仅千条,对未分类消息的覆盖不足,影响了分类置信度与全面性。
常用场景
经典使用场景
在社交媒体分析与自然语言处理领域,该数据集为研究机构官方Telegram频道的用户参与度与内容特征提供了经典范例。通过整合22项多维指标,包括用户互动指数、语言单元特征、可读性评分、AI生成概率及语义主题分类,它支持对俄语社交媒体文本进行深入的探索性数据分析。研究者可借此剖析消息长度、句法复杂性与互动模式间的关联,揭示内容策略对受众响应的动态影响,为机构传播效果评估奠定数据基础。
衍生相关工作
围绕该数据集衍生的经典工作主要集中在社交媒体分析方法的拓展与优化。例如,基于其参与度指数,后续研究开发了更精细的跨平台互动预测模型;针对主题分类任务,研究者利用其标注数据训练了多语言DeBERTa变体,提升了俄语短文本分类的准确性;在AI生成检测方面,该数据集的评估框架启发了结合结构特征与语义一致性的混合方法。这些工作不仅深化了对机构社交媒体生态的理解,也推动了自然语言处理技术在现实场景中的适配与创新。
数据集最近研究
最新研究方向
在社交媒体分析领域,基于Telegram频道数据的探索性研究正逐渐聚焦于多模态内容理解与自动化生成检测。以RTU MIREA数据集为例,其整合了用户参与度、语言学特征及AI生成评分等多维度指标,为机构传播策略提供了量化依据。当前前沿研究致力于开发更精细的主题分类模型,以应对未标记信息中潜在的高参与度内容模式,同时结合困惑度与突发性指标,增强AI文本检测的跨模型鲁棒性。这些探索不仅深化了对俄语社交媒体语言特性的理解,也为教育机构在数字化沟通中优化内容创作与分发机制提供了实证参考。
以上内容由遇见数据集搜集并总结生成


