PangeaBench-tydiqa
收藏Hugging Face2024-11-02 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/neulab/PangeaBench-tydiqa
下载链接
链接失效反馈官方服务:
资源简介:
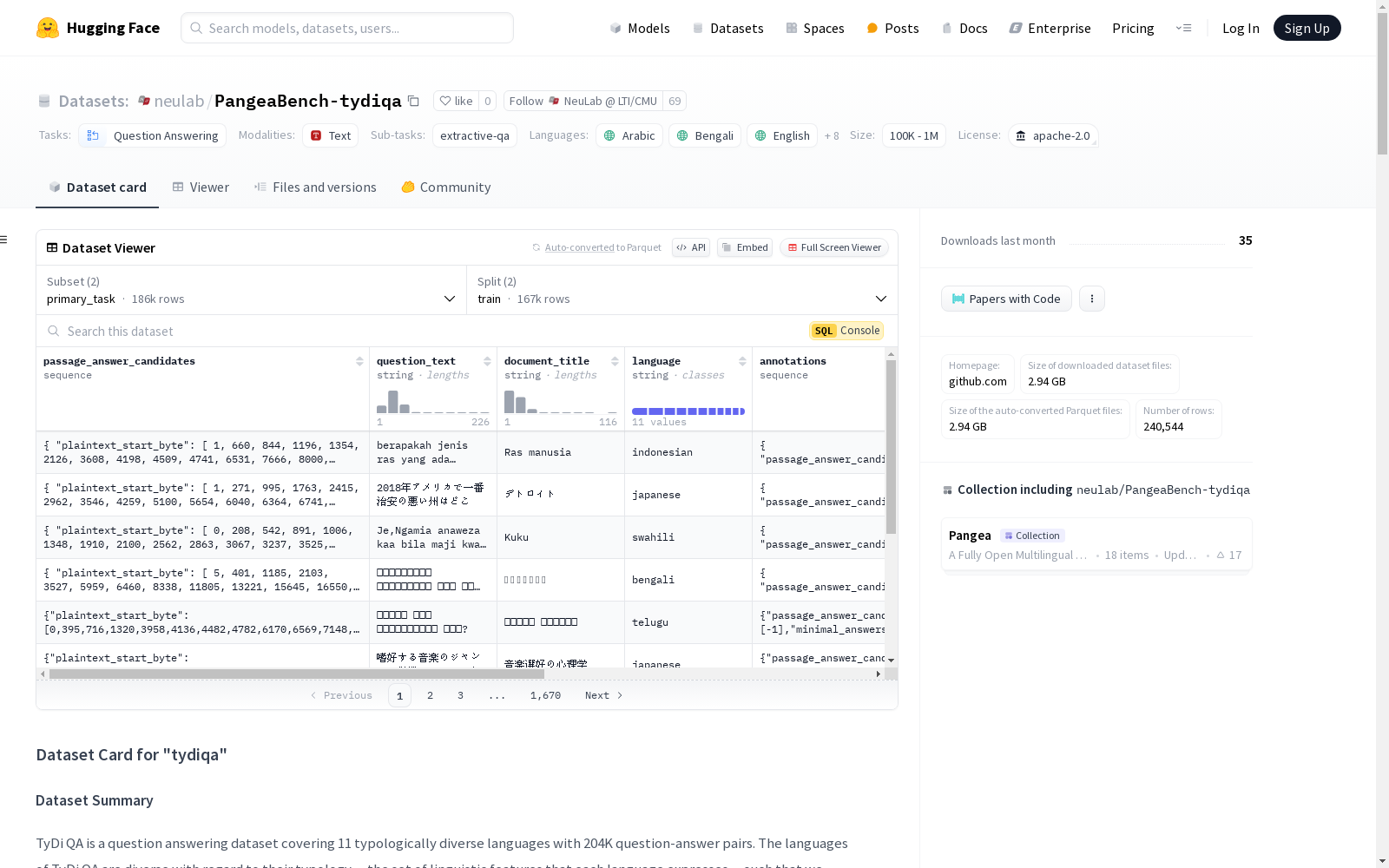
TyDi QA是一个涵盖11种类型多样语言的问答数据集,包含204K个问答对。这些语言包括阿拉伯语、孟加拉语、英语、芬兰语、印度尼西亚语、日语、韩语、俄语、斯瓦希里语、泰卢固语和泰语。该数据集旨在提供一个现实的信息检索任务,并通过让提问者不知道答案来避免提示效应。数据直接在每种语言中收集,不经过翻译,旨在捕捉在仅英语语料库中找不到的语言现象。数据集分为两个任务:primary_task和secondary_task,每个任务都有自己的特征和数据划分。primary_task包括passage_answer_candidates、question_text、document_title、language、annotations、document_plaintext和document_url等特征。secondary_task包括id、title、context、question和answers等特征。该数据集采用Apache 2.0许可证。
提供机构:
NeuLab @ LTI/CMU
创建时间:
2024-11-02
原始信息汇总
数据集概述
基本信息
- 数据集名称: TyDi QA
- 数据集类型: 问答数据集
- 语言: 阿拉伯语、孟加拉语、英语、芬兰语、印尼语、日语、韩语、俄语、斯瓦希里语、泰卢固语、泰语
- 许可证: Apache 2.0
- 多语言性: 多语言
- 任务类型: 问答(抽取式QA)
- 数据集大小:
- 下载大小: 2.91 GB
- 生成大小: 6.04 GB
数据集结构
配置
-
primary_task
- 特征:
passage_answer_candidates: 包含plaintext_start_byte和plaintext_end_bytequestion_text: 字符串document_title: 字符串language: 字符串annotations: 包含passage_answer_candidate_index,minimal_answers_start_byte,minimal_answers_end_byte,yes_no_answerdocument_plaintext: 字符串document_url: 字符串
- 数据分割:
- 训练集: 166916个样本, 5.55 GB
- 验证集: 18670个样本, 484.38 MB
- 特征:
-
secondary_task
- 特征:
id: 字符串title: 字符串context: 字符串question: 字符串answers: 包含text和answer_start
- 数据分割:
- 训练集: 49881个样本, 52.95 MB
- 验证集: 5077个样本, 5.01 MB
- 特征:
数据集创建
- 标注创建者: 众包
- 语言创建者: 众包
- 源数据: 扩展自维基百科
引用信息
@article{tydiqa, title = {TyDi QA: A Benchmark for Information-Seeking Question Answering in Typologically Diverse Languages}, author = {Jonathan H. Clark and Eunsol Choi and Michael Collins and Dan Garrette and Tom Kwiatkowski and Vitaly Nikolaev and Jennimaria Palomaki} year = {2020}, journal = {Transactions of the Association for Computational Linguistics} }
搜集汇总
数据集介绍
构建方式
PangeaBench-tydiqa数据集的构建基于众包模式,涵盖了11种类型多样的语言,包括阿拉伯语、孟加拉语、英语、芬兰语、印尼语、日语、韩语、俄语、斯瓦希里语、泰卢固语和泰语。数据源主要扩展自维基百科,确保了数据的广泛性和多样性。问题由真实的信息寻求者提出,避免了翻译带来的偏差,直接在各语言环境中收集,确保了数据的原生性和真实性。
使用方法
PangeaBench-tydiqa数据集的使用方法主要围绕问答任务展开,用户可以通过加载数据集的主任务和次任务配置,分别进行训练和验证。主任务适用于提取式问答,次任务则更适合生成式问答。用户可以根据具体需求选择不同的任务配置,利用数据集中的多语言特性,训练和评估跨语言问答模型。数据集的下载和加载过程通过HuggingFace平台实现,便于研究人员快速上手。
背景与挑战
背景概述
TyDi QA数据集由Google Research团队于2020年推出,旨在解决多语言问答系统中的关键问题。该数据集涵盖了11种类型学上多样化的语言,包括阿拉伯语、孟加拉语、英语、芬兰语、印尼语、日语、韩语、俄语、斯瓦希里语、泰卢固语和泰语,共包含204,000个问答对。其核心研究问题在于如何构建一个能够跨语言泛化的问答模型,尤其是在面对非英语语料时,模型能否有效处理这些语言中的独特语言现象。TyDi QA的独特之处在于其问题由真实的信息寻求者提出,而非通过翻译或人工构造,这为模型提供了一个更为真实的测试环境。该数据集对自然语言处理领域,尤其是多语言问答系统的研究,具有重要的推动作用。
当前挑战
TyDi QA数据集在构建和应用过程中面临多重挑战。首先,多语言问答系统的复杂性要求模型能够处理不同语言之间的语法、语义和文化差异,这对模型的泛化能力提出了极高要求。其次,数据集的构建依赖于众包标注,确保标注的一致性和准确性成为一大难题,尤其是在处理低资源语言时,标注者的语言能力和文化背景可能影响数据质量。此外,数据集的规模庞大,处理和分析这些数据需要大量的计算资源和时间,这对研究者的技术能力和硬件设施提出了挑战。最后,如何在不引入偏见的情况下,确保数据集在不同语言和文化中的公平性,也是该领域亟待解决的问题。
常用场景
经典使用场景
PangeaBench-tydiqa数据集在自然语言处理领域中被广泛用于多语言问答系统的开发与评估。其涵盖了11种类型多样的语言,提供了丰富的语言现象和复杂的问答对,使得研究者能够深入探索跨语言问答模型的性能。该数据集通过直接收集非翻译的原始语言数据,确保了问答任务的真实性和语言表达的多样性。
解决学术问题
PangeaBench-tydiqa数据集解决了多语言问答系统中语言多样性不足的问题。传统的问答数据集往往局限于英语或少数几种语言,难以全面评估模型在多种语言上的表现。该数据集通过覆盖11种类型各异的语言,为研究者提供了一个全面的基准,帮助开发出更具泛化能力的跨语言问答模型,推动了多语言自然语言处理技术的发展。
实际应用
在实际应用中,PangeaBench-tydiqa数据集被广泛应用于构建多语言搜索引擎、智能客服系统以及跨语言信息检索工具。这些应用场景要求系统能够理解并回答多种语言的问题,该数据集提供的多样化语言数据为这些系统的训练和优化提供了坚实的基础,提升了其在全球范围内的适用性和用户体验。
数据集最近研究
最新研究方向
在自然语言处理领域,多语言问答系统的研究正逐渐成为热点。PangeaBench-tydiqa数据集作为涵盖11种类型多样语言的问答数据集,为跨语言问答模型的开发与评估提供了重要资源。近年来,研究者们利用该数据集探索了多语言模型的泛化能力,特别是在低资源语言上的表现。通过引入先进的预训练模型和迁移学习技术,研究者们致力于提升模型在非英语语言上的问答准确率。此外,该数据集还被用于研究语言类型学对模型性能的影响,揭示了不同语言结构在问答任务中的独特挑战。这些研究不仅推动了多语言问答技术的发展,也为全球信息获取的公平性提供了技术支撑。
以上内容由遇见数据集搜集并总结生成


