NautData
收藏arXiv2025-10-31 更新2025-11-04 收录
下载链接:
https://github.com/H-EmbodVis/NAUTILUS
下载链接
链接失效反馈官方服务:
资源简介:
NautData是一个大规模的水下指令跟随数据集,包含145万对图像-文本,支持八种水下场景理解任务。数据集涵盖了图像、区域和对象级别的理解,拥有多样的会话结构和庞大的规模。它为水下场景理解模型的发展和评估提供了坚实的基础,有助于推动水下机器人探索、环境保护和资源开发等领域的发展。
NautData is a large-scale underwater instruction-following dataset containing 1.45 million image-text pairs, which supports eight underwater scene understanding tasks. It encompasses image-, region-, and object-level understanding, featuring diverse conversational structures and a substantial scale. This dataset provides a solid foundation for the development and evaluation of underwater scene understanding models, and facilitates the advancement of fields such as underwater robotic exploration, environmental protection and resource exploitation.
提供机构:
华中科技大学
创建时间:
2025-10-31
原始信息汇总
NAUTILUS 数据集概述
数据集基本信息
- 数据集名称: NautData
- 数据规模: 包含145万图像-文本对
- 数据类型: 大规模水下指令跟随数据集
- 主要用途: 支持水下大型多模态模型的开发和评估
数据集特点
- 专门针对水下场景理解任务构建
- 包含丰富的图像-文本配对数据
- 为水下视觉任务提供训练和评估基准
数据获取
- 数据地址: https://github.com/H-EmbodVis/NAUTILUS/tree/dataset
- 处理后的数据: https://huggingface.co/datasets/Wang017/NautData
- 标注文件: https://huggingface.co/datasets/Wang017/NautData-Instruct
相关模型
数据集支持以下两个版本的NAUTILUS模型:
- NAUTILUS(LLaVA): 基于LLaVA-1.5架构
- NAUTILUS(Qwen): 基于Qwen2.5-VL架构
模型性能
数据集在多个水下场景理解任务上表现出色,包括分类、描述、定位、检测、视觉问答和计数等任务。
搜集汇总
数据集介绍
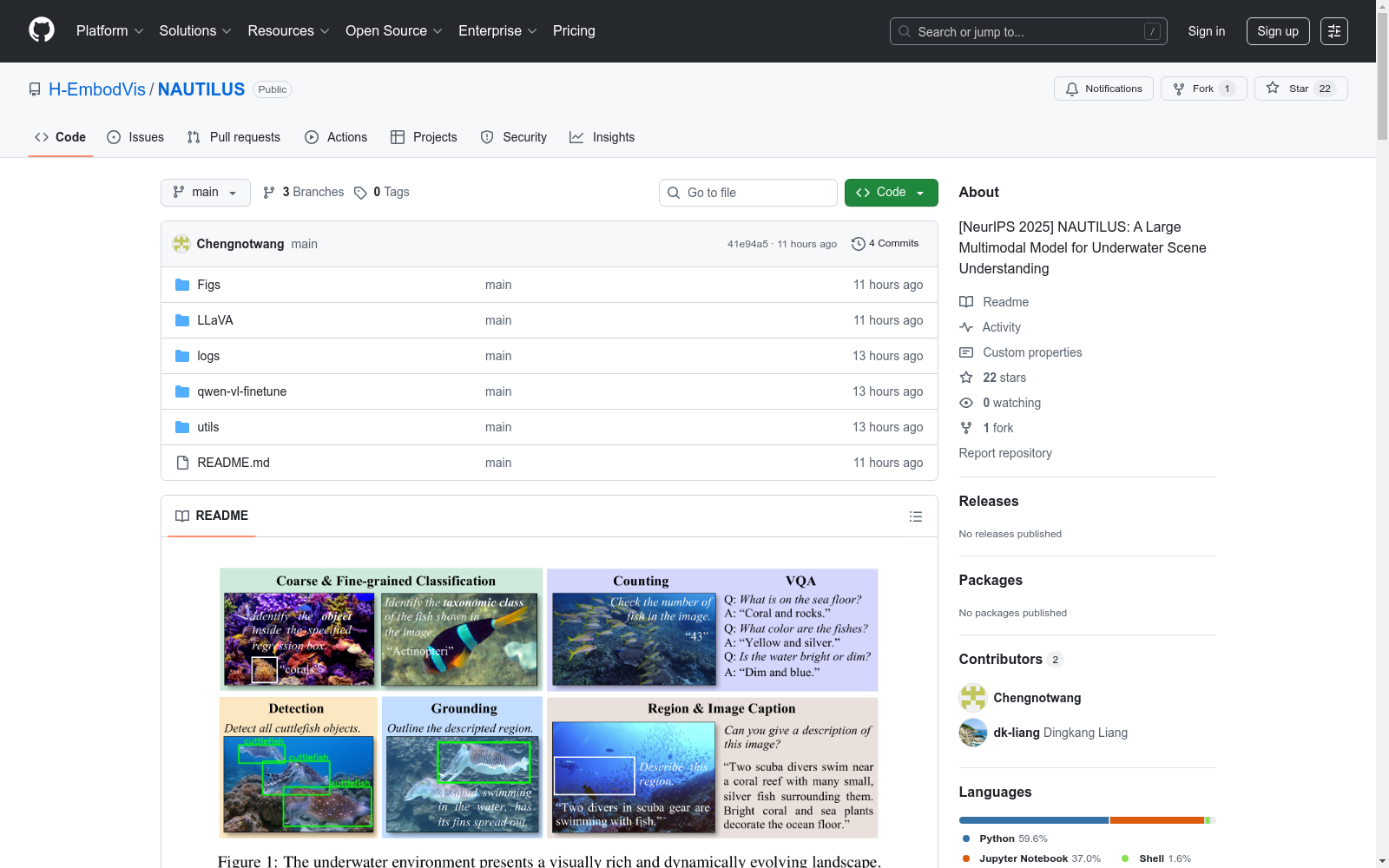
构建方式
在构建NautData数据集的过程中,研究团队整合了十个公开水下数据集资源,采用多模态指令生成框架系统性地构建了145万对图像-文本样本。数据生成过程融合了规则模板、大模型集成与自由形式生成三种策略:通过预定义模板转化目标检测坐标与分类标签构建感知任务对话;利用Gemini 2.0 Flash与Qwen2.5-VL等大语言模型生成区域描述和整体语义理解内容;最后通过人工校验与GPT-4o评估确保数据质量,形成了覆盖图像级、区域级和对象级三个粒度层次的八类任务标注体系。
使用方法
该数据集主要服务于水下大模型训练与评估两大应用场景。研究人员可采用参数高效微调策略,将数据集输入基于LLaVA-1.5或Qwen2.5-VL的基线模型进行指令调优,重点优化视觉-语言投影层与特征增强模块。评估阶段可利用内置测试集的3920张图像与7916个问答样本,通过准确率、METEOR、mAP等指标系统衡量模型在八类任务上的表现。数据集设计的退化场景分类(低光照/浑浊水体等)还可用于模型鲁棒性专项验证,推动水下视觉理解技术的实际部署。
背景与挑战
背景概述
NautData数据集于2025年由华中科技大学与国防科技大学联合团队构建,旨在解决水下场景理解领域多粒度感知任务的数据匮乏问题。该数据集包含145万图像-文本对,覆盖粗粒度分类、细粒度分类、计数、视觉问答、检测、定位、区域描述和图像描述八大任务,成为首个支持多层次水下场景理解的大规模指令调优数据集。其创新性在于融合物理成像先验与多模态学习,显著推动了水下自主探索、资源开发等应用领域的技术发展,为水下大模型研究奠定了坚实基础。
当前挑战
NautData面临的领域挑战在于水下图像退化对多任务感知的干扰,包括光线散射与吸收导致的颜色失真、低对比度及能见度下降,直接影响分类与检测精度。构建过程中需克服大规模高质量标注数据稀缺的难题,通过融合规则生成与自由式语言模型输出,确保八类任务标注的多样性与准确性。同时,水下物种多样性及复杂环境特性要求模型具备跨域泛化能力,而数据采集受限于设备成本与标注专业性,进一步增加了数据集构建的复杂性。
常用场景
经典使用场景
在海洋生态研究领域,NautData数据集通过整合158万张图像与145万组问答对,构建了覆盖粗粒度分类、细粒度分类、计数、视觉问答、检测、定位、区域描述和图像描述八大任务的完整评估体系。该数据集特别适用于训练多模态大模型进行水下场景的层次化理解,其多粒度标注机制能够同时支持目标识别、群体行为分析和语义描述生成,为水下智能探测提供了标准化基准。
解决学术问题
该数据集有效解决了水下视觉领域长期存在的三大挑战:首先,通过融合物理成像先验与特征增强模块,显著缓解了水下图像退化对模型性能的干扰;其次,其多层次标注体系突破了传统单任务模型的认知局限,实现了从像素级到语义级的跨粒度理解;最后,大规模指令调优数据填补了水下多任务学习的空白,为领域自适应研究提供了重要基础设施。
实际应用
在海洋资源勘探实践中,该数据集支撑的模型已应用于自主水下机器人系统,实现了珊瑚礁生态监测、渔业资源评估和海底地形测绘等任务。通过实时解析水下视频流中的生物种类分布与群体动态,为海洋保护区的智能化管理提供决策依据。在军事安防领域,其多任务感知能力可用于水下设施巡检与异常目标追踪,显著提升水下作业的自动化水平。
数据集最近研究
最新研究方向
水下场景理解领域正经历从单一任务模型向多粒度多模态大模型的范式转变。前沿研究聚焦于构建大规模指令调优数据集以克服水下图像退化与领域偏移的挑战,NautData作为首个涵盖八项任务的145万图像-文本对资源,推动了层次化感知与语义理解的一体化发展。热点方向包括基于物理成像模型的视觉特征增强技术,通过融合深度先验与暗像素先验显式恢复退化信息,显著提升了模型在低光照、浑浊水域等复杂环境下的鲁棒性。这类研究对海洋资源勘探、生态监测等应用具有深远意义,为水下自主系统提供了更可靠的环境交互能力。
相关研究论文
- 1NAUTILUS: A Large Multimodal Model for Underwater Scene Understanding华中科技大学 · 2025年
以上内容由遇见数据集搜集并总结生成


