MOLE
收藏arXiv2025-05-26 更新2025-05-28 收录
下载链接:
https://huggingface.co/datasets/IVUL-KAUST/MOLE
下载链接
链接失效反馈官方服务:
资源简介:
MOLE数据集由KAUST研究机构创建,包含10000个标记的Tokens,用于命名实体识别(NER)和词性标注(PoS)任务。该数据集旨在帮助从科学论文中自动提取元数据属性,支持多语言数据集,包括阿拉伯语、英语、俄语、法语和日语。数据集的创建过程涉及对52篇不同语言的论文进行手动标注,并使用结构化模式进行元数据属性的提取和验证。MOLE数据集的发布旨在促进科学研究的可发现性和可重复性,并推动基于大语言模型的信息提取技术的发展。
The MOLE dataset was developed by King Abdullah University of Science and Technology (KAUST). It contains 10,000 annotated Tokens, and is targeted at Named Entity Recognition (NER) and Part-of-Speech (PoS) tagging tasks. This dataset is designed to facilitate automatic metadata attribute extraction from scientific papers, and is a multilingual resource covering Arabic, English, Russian, French and Japanese. The construction of the dataset entails manual annotation of 52 papers written in different languages, alongside extraction and validation of metadata attributes via structured schemas. The release of the MOLE dataset aims to enhance the discoverability and reproducibility of scientific research, and advance the development of information extraction technologies based on Large Language Models (LLMs).
提供机构:
KAUST
创建时间:
2025-05-26
原始信息汇总
MOLE数据集概述
📌 基本信息
- 名称: MOLE (Metadata Extraction and Validation in Scientific Papers)
- 用途: 评估和验证从科学论文中提取的元数据
- 语言: 英语(en)、阿拉伯语(ar)、法语(fr)、日语(jp)、俄语(ru)
- 数据规模: <1K样本
- 许可证: Apache 2.0
- 任务类别: 特征提取
📋 数据集结构
主要属性
- Name (str): 数据集名称
- Subsets (List[Dict[Name, Volume, Unit, Dialect]]): 数据集的方言子集
- Link (url): 数据集访问链接
- HF Link (url): Huggingface数据集链接
- License (str): 数据集许可证
- Year (date[year]): 数据集发布年份
- Language (str): 数据集包含的语言
- Dialect (str): 数据集的方言
- Domain (List[str]): 数据集的来源
- Form (str): 数据形式
- Collection Style (List[str]): 数据收集方式
- Description (str): 数据集简要描述
- Volume (float): 数据集大小
- Unit (str): 数据集包含的示例类型
- Ethical Risks (str): 数据集的伦理风险级别
- Provider (List[str]): 数据集提供者
- Derived From (List[str]): 用于创建该数据集的数据集
- Paper Title (str): 论文标题
- Paper Link (url): 论文链接
- Script (str): 数据集脚本
- Tokenized (bool): 数据集是否已分词
- Host (str): 数据集托管仓库名称
- Access (str): 数据集可访问性
- Cost (str): 数据集费用(若非免费)
- Test Split (bool): 是否包含训练/验证和测试分割
- Tasks (List[str]): 数据集适用的NLP任务
- Venue Title (str): 论文发表的会议/期刊标题
- Venue Type (str): 会议/期刊类型
- Venue Name (str): 论文发表的会议/期刊全称
- Authors (List[str]): 论文作者
- Affiliations (List[str]): 作者所属机构
- Abstract (str): 论文摘要
📁 加载数据集
python from datasets import load_dataset dataset = load_dataset(IVUL-KAUST/mole)
⛔️ 局限性
- 数据集包含52篇标注论文,可能不足以全面评估大型语言模型(LLMs)
🔑 许可证
- 许可证类型: Apache 2.0
- 许可证链接: https://www.apache.org/licenses/LICENSE-2.0
引用
bibtex @misc{mole, title={MOLE: Metadata Extraction and Validation in Scientific Papers Using LLMs}, author={Zaid Alyafeai and Maged S. Al-Shaibani and Bernard Ghanem}, year={2025}, eprint={2505.19800}, archivePrefix={arXiv}, primaryClass={cs.CL}, url={https://arxiv.org/abs/2505.19800}, }
搜集汇总
数据集介绍
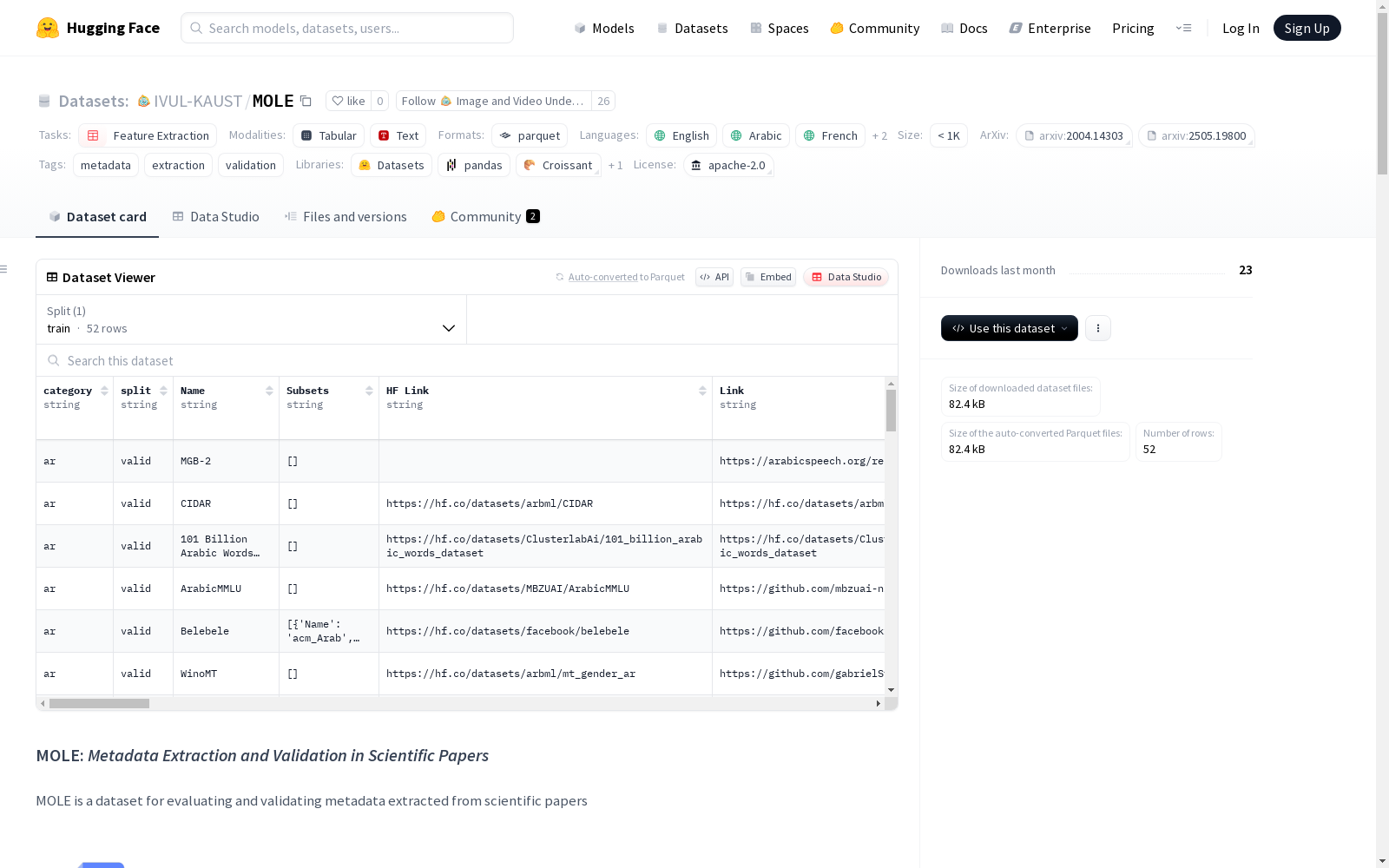
构建方式
MOLE数据集的构建采用了基于大语言模型(LLMs)的自动化元数据提取框架,通过处理科学论文的LaTeX源码或PDF格式文档,结合结构化模式(schema)引导的提取方法,实现了对多语言数据集30余种元数据属性的系统性抽取。该框架创新性地整合了类型验证、选项验证和长度验证三重校验机制,并引入网页浏览功能以补充论文中缺失的元数据信息。研究人员手动标注了涵盖阿拉伯语、英语、法语等6种语言类别的52篇论文作为测试基准,每篇论文平均标注61个元数据字段,构建过程充分考虑了科学文献的异构性和多语言特性。
特点
作为科学文献元数据提取领域的创新性资源,MOLE数据集具有三大核心特征:其多维度覆盖性体现在支持从论文中提取名称、许可证、数据量等32类结构化属性,较传统方法提升3-6倍的属性覆盖广度;跨语言兼容性表现为专门设计了适应阿拉伯语、日语等不同语言特性的模式体系,例如针对日语数据集的文字类型(假名/汉字)标注方案;技术前瞻性则反映在采用7种前沿LLM进行系统性评估,包括Gemini 2.5 Pro和GPT-4o等模型,基准测试显示最佳模型在属性提取准确率上达到67.42%。数据集特别强化了对数据可追溯性(派生来源)、伦理风险等级等新兴元数据维度的采集能力。
使用方法
该数据集的使用遵循标准化流程:研究者首先将科学论文的LaTeX或PDF文档输入预处理模块,通过LLM引擎根据预设模式生成初始元数据JSON;随后利用验证模块对输出进行类型转换、选项匹配等规范化处理,对于论文中缺失的许可证等关键属性,可激活浏览模块从HuggingFace等存储库补充信息。评估阶段提供多粒度指标,包括基于验证组(可访问性、多样性等)的分类准确率分析,以及针对长文本处理、小样本学习等特定场景的消融实验。数据集配套发布的模式定义文件和标注指南支持用户快速适配新的元数据规范,其CC0许可协议保障了学术使用的自由度。
背景与挑战
背景概述
MOLE(Metadata Extraction and Validation in Scientific Papers Using LLMs)是由KAUST和SDAIA-KFUPM联合人工智能研究中心的研究人员于2025年提出的一个框架,旨在利用大语言模型(LLMs)自动从科学论文中提取元数据。该数据集的创建背景源于科学研究的指数级增长,使得元数据提取成为数据编目和保存的关键任务。MOLE扩展了早期工作Masader的范围,不仅支持阿拉伯语数据集,还涵盖英语、俄语、法语和日语等多语言数据集。其核心研究问题是通过自动化手段提取超过30种元数据属性,以解决科学数据发现和可重复性方面的挑战。MOLE的影响力体现在其提出的模式驱动方法和验证机制,为科学文献的元数据管理提供了新的解决方案。
当前挑战
MOLE数据集面临的挑战主要包括两个方面:领域问题的挑战和构建过程中的挑战。在领域问题方面,MOLE旨在解决科学论文中元数据提取的复杂性问题,包括处理多语言、多格式文档以及确保元数据的准确性和一致性。具体挑战包括:1) 科学论文的异构性导致传统规则或监督学习方法难以适应;2) 元数据属性的多样性(如许可证、数据集链接等)需要灵活的提取和验证机制。在构建过程中,挑战包括:1) 处理不同输入格式(如LaTeX、PDF)的技术难题;2) 设计有效的验证机制以确保输出符合预定模式;3) 创建涵盖多语言的基准测试集以评估模型性能。这些挑战凸显了在快速发展的科学数据生态系统中实现自动化元数据提取的复杂性。
常用场景
经典使用场景
MOLE数据集在学术文献的元数据提取领域具有广泛的应用场景,特别是在处理多语言科学论文时表现出色。该数据集通过利用大型语言模型(LLMs)自动提取超过30种不同的元数据属性,显著提升了元数据提取的效率和准确性。其经典使用场景包括从科学论文中提取数据集名称、发布年份、许可证类型、语言类别等关键信息,为学术研究和数据管理提供了强有力的支持。
解决学术问题
MOLE数据集解决了学术研究中元数据提取的自动化难题,尤其是在多语言环境下。传统方法依赖人工标注或规则系统,难以应对科学论文的异构性和快速增长的文献数量。MOLE通过LLMs的上下文处理能力和模式驱动的方法,显著提高了元数据提取的覆盖率和一致性,从而促进了研究数据的可发现性和可重复性。
衍生相关工作
MOLE数据集衍生了多项相关研究工作,包括基于LLMs的元数据提取框架的优化、多语言元数据标准的制定以及元数据验证机制的改进。例如,研究人员利用MOLE的基准测试评估了不同LLMs在元数据提取任务中的表现,进一步推动了自动化元数据提取技术的发展。此外,MOLE还为其他领域(如化学、医疗和能源)的元数据提取提供了参考和借鉴。
以上内容由遇见数据集搜集并总结生成


