imo_2025
收藏Hugging Face2025-08-03 更新2025-08-04 收录
下载链接:
https://huggingface.co/datasets/MathArena/imo_2025
下载链接
链接失效反馈官方服务:
资源简介:
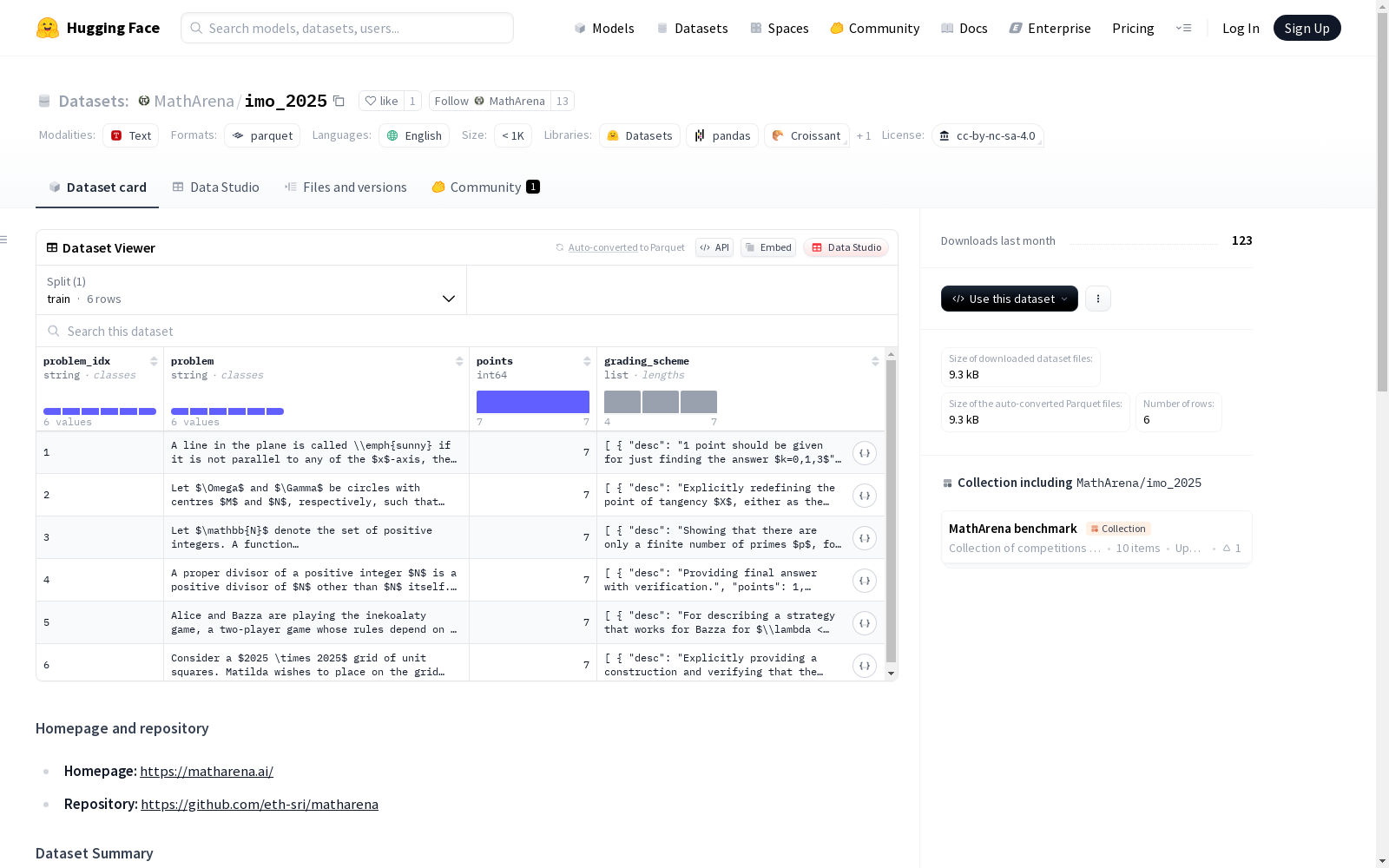
IMO 2025数据集包含了2025年国际数学奥林匹克(IMO)竞赛的问题。这个数据集旨在用于MathArena排行榜,其中每个问题都有详细的描述、可获得的分数以及评分方案的标题、描述和分值。数据集分为训练集,共有6个示例,大小为7418字节。
创建时间:
2025-07-21
原始信息汇总
IMO 2025数据集概述
数据集基本信息
- 名称: IMO 2025
- 语言: 英语 (en)
- 许可证: Attribution-NonCommercial-ShareAlike 4.0 International (CC BY-NC-SA 4.0)
- 大小分类: n<1K
- 下载大小: 9303 bytes
- 数据集大小: 7418 bytes
数据集结构
- 特征:
problem_idx(string): 问题在竞赛中的索引problem(string): 完整的问题陈述points(int64): 该问题可获得的分数grading_scheme(list[dict]): 评分方案列表,每个字典包含:desc(string): 该部分评分方案的描述points(int64): 该部分证明可获得的分数title(string): 与该部分评分方案相关的标题
- 数据划分:
train: 包含6个示例,大小为7418 bytes
数据来源
- 原始问题: 来自IMO 2025竞赛
- 处理: 问题被提取、转换为LaTeX格式并验证
引用信息
bibtex @misc{balunovic_srimatharena_2025, title = {MathArena: Evaluating LLMs on Uncontaminated Math Competitions}, author = {Mislav Balunović and Jasper Dekoninck and Ivo Petrov and Nikola Jovanović and Martin Vechev}, copyright = {MIT}, url = {https://matharena.ai/}, publisher = {SRI Lab, ETH Zurich}, month = feb, year = {2025}, }
相关链接
- 主页: https://matharena.ai/
- 代码库: https://github.com/eth-sri/matharena
搜集汇总
数据集介绍
构建方式
IMO 2025数据集源自国际数学奥林匹克竞赛2025年的真实赛题,经过系统性的整理与验证构建而成。研究人员将原始竞赛题目提取并转换为LaTeX格式,确保数学符号与公式的精确呈现。每个问题均标注了唯一索引、完整题目描述、对应分值以及详细评分方案,评分方案进一步细分为多个可获分的证明部分,每部分包含标题、描述和分值。
使用方法
研究者可通过HuggingFace平台直接下载该数据集,其结构化设计特别适合用于大型语言模型在数学推理能力的评估。使用时应遵循CC BY-NC-SA 4.0许可协议,典型应用场景包括:构建数学问题解答系统的训练数据、开发自动评分算法、或作为基准测试评估模型对复杂数学证明的理解能力。数据中的分级评分方案可用于细粒度分析模型在不同证明步骤中的表现差异。
背景与挑战
背景概述
IMO 2025数据集由苏黎世联邦理工学院SRI实验室的Mislav Balunović等研究人员于2025年构建,旨在为数学竞赛领域提供高质量的评估基准。该数据集收录了国际数学奥林匹克竞赛(IMO)2025年的全部试题,包含题目索引、完整题干、分值及详细评分方案等结构化信息。作为MathArena项目的重要组成部分,该数据集为大型语言模型在数学推理能力评估方面提供了无污染的测试环境,推动了人工智能与数学教育交叉领域的研究进展。
当前挑战
该数据集主要面临双重挑战:在领域问题层面,数学竞赛题目的高抽象性和严格逻辑性对模型的符号推理与分步证明能力提出极高要求,传统神经网络难以准确捕捉数学证明的严谨结构;在构建过程中,试题的LaTeX格式转换需保持数学符号系统的完整性,评分方案的细粒度标注需要专业数学家的深度参与,确保每个证明步骤的分数分配符合国际竞赛标准。这些挑战使得数据集的构建过程兼具技术复杂性和领域专业性。
常用场景
经典使用场景
在国际数学奥林匹克竞赛(IMO)的研究领域中,imo_2025数据集为数学问题求解和自动推理提供了宝贵的资源。该数据集收录了2025年IMO竞赛的题目及其评分细则,为研究者在数学问题形式化、自动求解算法开发以及评分标准制定等方面提供了标准化的测试平台。经典使用场景包括利用这些题目评估大型语言模型在数学推理和问题解决方面的能力,特别是在无污染环境下测试模型的真实数学水平。
解决学术问题
imo_2025数据集有效解决了数学自动推理领域中的多个关键问题。首先,它提供了标准化的数学竞赛题目,克服了传统数学数据集题目来源不一致的缺陷。其次,详细的评分细则为研究自动评分算法提供了基准,有助于推动数学问题自动评分技术的发展。最重要的是,该数据集为评估AI系统的数学推理能力提供了可靠的测试标准,填补了高水平数学问题评估资源的空白。
实际应用
在实际应用层面,imo_2025数据集已被广泛应用于数学教育技术和AI系统开发领域。教育科技公司利用该数据集开发智能辅导系统,为学生提供接近IMO水平的数学训练。AI研究团队则将其作为基准测试集,评估和提升大型语言模型在复杂数学问题上的表现。此外,数学竞赛培训领域也借助该数据集开发更精准的评分和反馈系统,提升培训效果。
数据集最近研究
最新研究方向
近年来,随着大型语言模型(LLM)在数学推理领域的应用不断深入,IMO 2025数据集作为国际数学奥林匹克竞赛的权威题库,正成为评估模型数学推理能力的重要基准。该数据集不仅包含了高难度的数学问题,还详细标注了评分方案,为研究者提供了细粒度的评估标准。当前的研究热点主要集中在如何利用该数据集提升模型在复杂数学问题上的推理能力,以及探索模型在自动解题和评分方面的潜力。这一方向的研究不仅推动了数学教育智能化的发展,也为人工智能在学术竞赛中的应用开辟了新的可能性。
以上内容由遇见数据集搜集并总结生成


