Omni-DuplexEval-Examples
收藏Hugging Face2026-05-06 更新2026-05-07 收录
下载链接:
https://huggingface.co/datasets/foragi/Omni-DuplexEval-Examples
下载链接
链接失效反馈官方服务:
资源简介:
Omni-DuplexEval-Examples 是 Omni-DuplexEval 的一个精选子集,用于定性可视化和论文演示。该数据集旨在评估实时双工多模态交互能力,包含两个主要场景:实时描述(RTD)和主动提醒(PR)。RTD 评估模型在流式设置下持续描述视频内容的能力,包含 6 个任务;PR 评估模型识别相关事件并在适当时机响应的能力,包含 3 个任务。每个任务包含 5 个代表性样本,覆盖所有基准场景和任务类型。数据集包含 9 个任务,每个样本包含视频文件、问题音频、问题文本、参考答案、提醒时间戳等字段。视频来源于公开平台,经过人工检查以确保安全性。
Omni-DuplexEval-Examples is a curated subset of Omni-DuplexEval, designed for qualitative visualization and paper demonstrations. The dataset aims to evaluate real-time duplex multimodal interaction capabilities, consisting of two main scenarios: Real-Time Description (RTD) and Proactive Reminding (PR). RTD assesses the models ability to continuously describe video content in a streaming setting, comprising 6 tasks; PR evaluates the models capability to identify relevant events and respond at appropriate times, comprising 3 tasks. Each task includes 5 representative samples, covering all benchmark scenarios and task types. The dataset contains 9 tasks, with each sample including video files, question audio, question text, reference answers, reminder timestamps, and other fields. Videos are sourced from public platforms and manually reviewed to ensure safety.
创建时间:
2026-05-02
原始信息汇总
数据集概述:Omni-DuplexEval-Examples
基本信息
- 数据集名称:Omni-DuplexEval-Examples
- 许可协议:Apache-2.0
- 数据集主页:https://huggingface.co/datasets/foragi/Omni-DuplexEval-Examples
数据集简介
Omni-DuplexEval-Examples 是完整基准数据集 Omni-DuplexEval 的一个精选子集,主要用于定性可视化和论文演示。每个任务包含 5 个代表性样本,覆盖所有基准场景和任务类型。该子集的标注格式和数据结构与完整基准数据集保持一致。
完整基准:Omni-DuplexEval
Omni-DuplexEval 是一个用于评估实时双工多模态交互的基准数据集。与传统的离线视频理解基准不同,该基准专注于流式场景,要求模型持续处理不断变化的多模态输入,并自主决定回答内容和回答时机。
基准场景
该基准包含两个主要场景:
1. 实时描述(Real-Time Description, RTD)
评估模型在流式设置下持续描述动态视频内容的能力。
包含以下任务:
- RTD_Omni:通用实时描述
- RTD_counting:计数任务
- RTD_fine_grained_movement:细粒度运动描述
- RTD_interaction_relation:交互关系描述
- RTD_OCR:文字识别描述
- RTD_world_knowledge:世界知识描述
2. 主动提醒(Proactive Reminder, PR)
评估模型识别相关事件并在适当时刻主动响应的能力。
包含以下任务:
- PR_event_reminder:事件提醒
- PR_post_event_reminder:事件后提醒
- PR_correction:纠正提醒
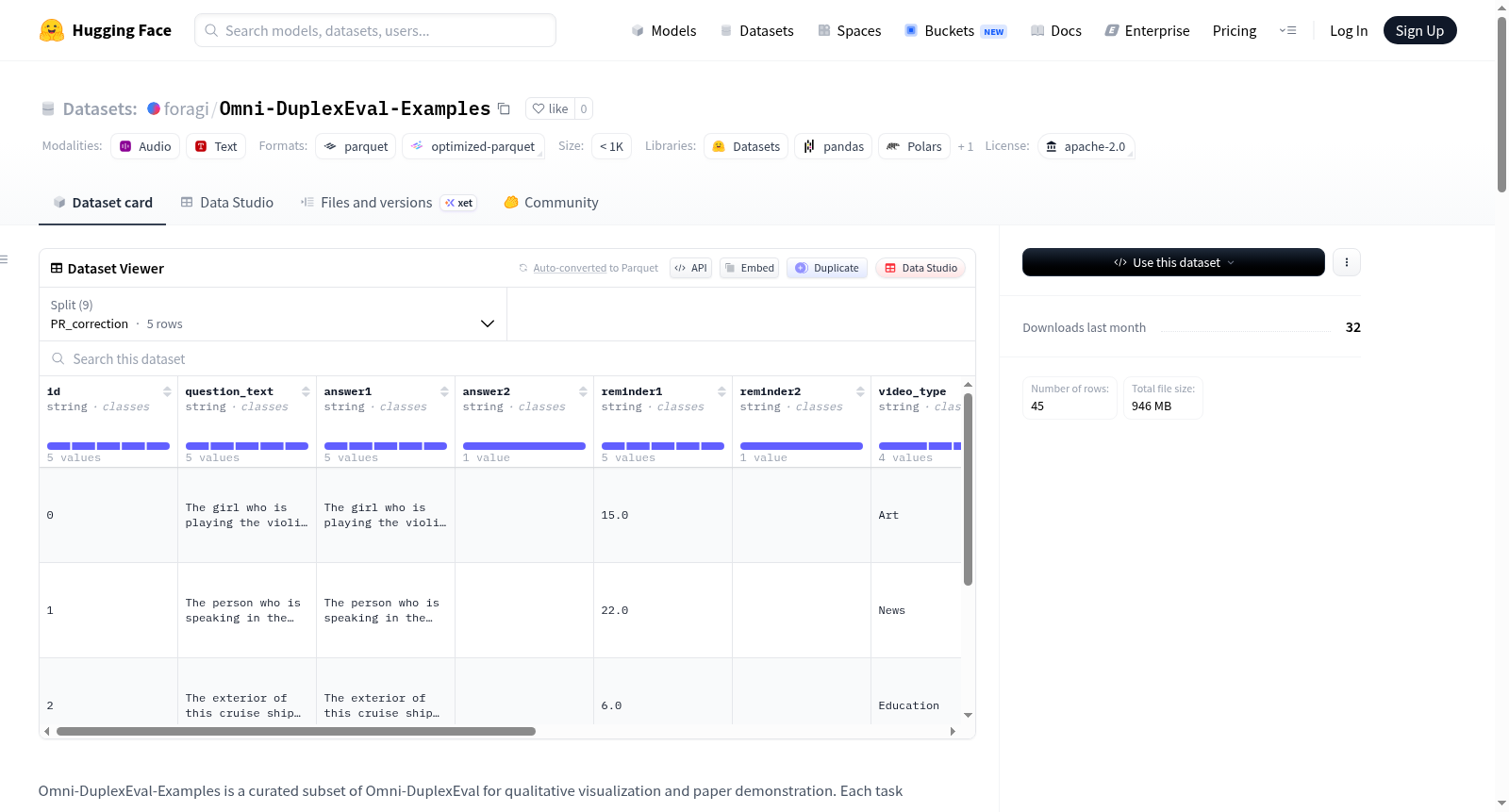
数据格式
每个样本包含以下字段:
| 字段 | 描述 |
|---|---|
id |
唯一样本标识符 |
video |
视频文件 |
question_audio |
问题的音频版本,音频时长与视频时长一致 |
question_text |
问题的文本版本 |
answer1 |
参考回答1 |
answer2 |
参考回答2 |
reminder1 |
时间戳标注1 |
reminder2 |
时间戳标注2 |
video_type |
视频类别 |
video_duration |
视频时长 |
标注细节
问题音频(question_audio)
- 与完整视频时长对齐
- RTD任务:问题在视频开始时提出
- PR任务:问题可能在任意时间戳出现
参考回答(answer1 和 answer2)
- 提供人工标注的参考响应
- 纠正任务中,answer1 额外包含修正后的目标响应
- PR_event_reminder 和 PR_post_event_reminder 任务中,回答字段为空
提醒时间戳(reminder1 和 reminder2)
- 存储与提醒事件相关的时间戳标注
- 纠正任务中,reminder1 包含错误用户陈述/事件的时间戳
- RTD任务中,提醒字段为空
数据收集与安全保障
- 视频来源于 YouTube 和 Bilibili 等公开平台
- 不包含个人敏感信息
- RTD视频:选择具有清晰时间动态和持续演变主体的内容
- PR视频:选择包含明确且无歧义事件的内容,以确保稳定评估
- 所有样本均经过人工检查,排除了潜在不安全或高风险内容
搜集汇总
数据集介绍
构建方式
Omni-DuplexEval-Examples 作为 Omni-DuplexEval 基准评测的子集,精心选取了涵盖所有基准场景与任务类型的代表性样本,每项任务包含5个典型实例,专为论文及补充材料中的定性可视化与演示而设计。其标注格式与数据结构与完整基准完全一致,确保了样本的代表性与结果的通用性。数据源于 YouTube、Bilibili 等公开平台,视频经过人工审核以排除潜在不安全或高风险内容,构建过程严谨可靠。
使用方法
数据集以结构化字段存储,每个样本包含视频、问题音频(与视频时长对齐)、问题文本、参考答案及提醒时间戳等关键信息。在实时描述任务中,问题于视频起始处提出;在主动提醒任务中,问题可能出现在任意时间点,用以触发模型在适当时机做出响应。用户可结合视频与问题音频,驱动模型在流式输入下持续生成描述或识别事件,并通过参考答案和时间戳进行定量与定性评估,适用于研究多模态流式交互系统的演示与验证。
背景与挑战
背景概述
在实时双模态交互领域,现有基准多聚焦于静态或离线场景,难以捕捉流式多模态输入中动态演化的语义信息与交互时机。为填补这一空白,Omni-DuplexEval于2025年由相关研究团队构建,旨在评估模型在流式设定下的实时描述与主动提醒能力。该基准涵盖9项细粒度任务,包含实时描述(RTD)与主动提醒(PR)两大场景,并通过人工标注的时间戳提供精准参考。作为其子集,Omni-DuplexEval-Examples专为论文演示与定性可视化设计,每任务精选5个代表性样本,在保持全量基准结构与格式一致性的同时,为多模态交互评估提供了可复现的典型案例。
当前挑战
Omni-DuplexEval所解决的领域挑战在于突破传统离线视频理解的局限,聚焦于实时双工交互中模型对不断变化的输入进行持续感知、决策响应时机以及事件驱动的主动交互能力。在构建过程中,RTD任务面临视频内容时序动态性强、主体持续演化带来的精细描述难度,而PR任务则需精确定位显式事件的发生与响应时机,要求标注人员对交互边界做出人工判断。此外,视频数据源自公开平台,需经严格筛查以排除敏感或高风险内容,确保基准的安全性与评测公平性。
常用场景
经典使用场景
在实时多模态交互研究的星辰大海中,Omni-DuplexEval-Examples以其精心设计的流式评估架构,成为衡量模型在动态场景下持续感知与响应能力的试金石。该数据集经典的使用场景聚焦于两大核心任务:实时描述(RTD)与主动提醒(PR)。在RTD任务中,模型需对不断演变的视频内容进行连续、流畅的流式描述,涵盖物体计数、精细运动、交互关系、OCR识别及世界知识等多样维度;而在PR任务中,模型被要求具备事件感知能力,能在恰当时间节点主动发起提醒或纠正用户行为。这一设计使得该数据集成为评估多模态模型从“离线理解”迈向“在线交互”的关键验证场。
解决学术问题
该数据集的问世,精准击中了长尾分布于传统离线视频理解基准未能触及的学术盲区——实时双工多模态交互能力的量化评估。它系统性地解决了模型在流式设定下“何时该响应”与“该响应什么”的双重决策难题。通过引入人工标注的细粒度时间戳,Omni-DuplexEval为研究者提供了测量模型在动态信息流中保持上下文连贯性、捕捉关键事件并及时作出恰当反馈的能力的可靠标尺。这一突破性贡献不仅填补了流式交互评测的方法论空白,更推动了多模态对话系统研究从静态分析向动态协同的范式转换,对构建真正具备人类级交互智能的AI系统具有深远学术意义。
实际应用
在产业界对实时智能助手日益渴求的浪潮中,Omni-DuplexEval所勾勒出的能力图谱具有明晰的应用映射。实际部署场景涵盖智能驾驶环境中的路况实时播报与异常事件主动提醒、远程协作场景下对操作流程的同步描述与纠错、以及增强现实设备中根据用户视野动态变化提供情境感知的语音助理。该数据集为这些应用提供了一个标准化的评估沙盘,使开发者能够系统性地调试模型在真实流式场景中的延迟容忍度、上下文保持能力与主动服务的时机选择,从而加速技术从实验室原型向可靠产品的转化。
数据集最近研究
最新研究方向
在实时双模态交互领域,Omni-DuplexEval-Examples子集所隶属的Omni-DuplexEval基准测试,正引领着从离线理解迈向流式处理的前沿探索。该基准聚焦于流媒体场景,要求模型不仅需持续解析动态多模态输入,还需自主决策响应内容与时机,精准映射了对话式AI、智能助手及自动驾驶中人机协同等热点事件的挑战。其两大核心场景——实时描述与主动提醒,分别评估了模型对连续时序事件的语言生成能力,以及对关键事件的感知与主动干预能力,这对提升具身智能体在复杂环境中的交互自然性与安全性具有重要意义。通过涵盖9个精细任务与人类标注的时间戳,该数据集为评估模型在动态交互中的实时性、上下文感知与事件驱动响应提供了标准化框架,推动着多模态AI从被动应答向主动服务范式的变革。
以上内容由遇见数据集搜集并总结生成


