KPoEM
收藏Hugging Face2025-08-20 更新2025-08-22 收录
下载链接:
https://huggingface.co/datasets/AKS-DHLAB/KPoEM
下载链接
链接失效反馈官方服务:
资源简介:
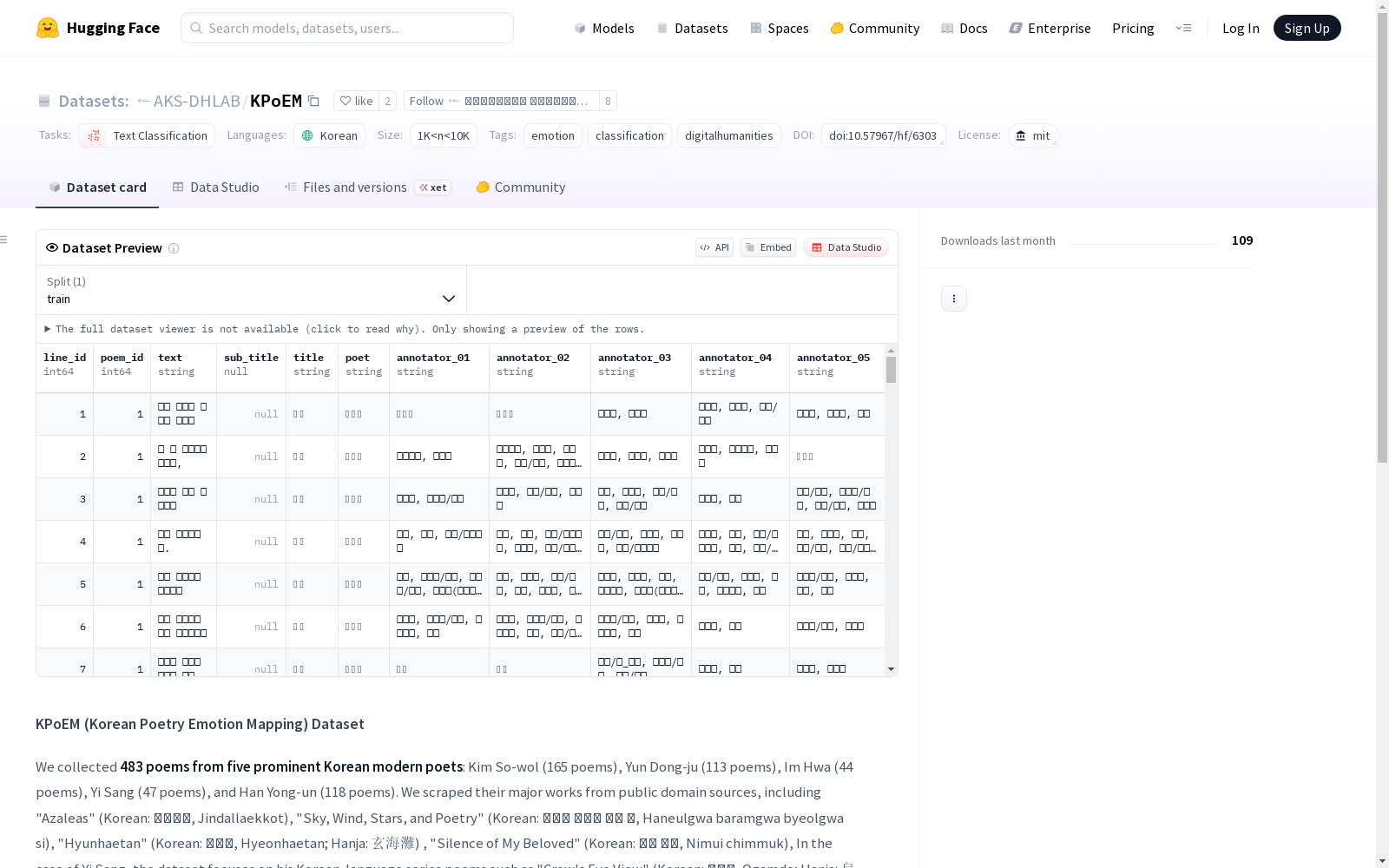
KPoEM数据集是从公共领域资源中收集的五位韩国现代著名诗人的483首诗,包含7,007行情感注释的文本。数据集支持文本分类任务,专注于情感分析和分类,适用于韩国文学文本的计算机辅助情感分类和生成型人工智能研究。
创建时间:
2025-08-15
搜集汇总
数据集介绍
构建方式
在数字人文领域,KPoEM数据集的构建依托于韩国现代诗歌的经典文本,系统采集了金素月、尹东柱等五位代表性诗人的483首作品。通过从公共领域资源中爬取原始诗歌文本,研究团队采用人工标注方式对每行诗句进行情感标注,最终形成涵盖7007行诗句的细粒度情感映射数据,为文学计算分析提供了结构化基础。
特点
该数据集的核心特点在于其专注于韩国现代诗歌的情感维度,标注粒度达到行级别,实现了对诗歌文本中情感变化的精准捕捉。数据涵盖喜悦、悲伤、愤怒等多元情感类别,且所有标注均经过多名标注者的一致性验证,确保了标注质量的可靠性。诗歌来源均选自公共领域经典作品,兼具文学价值与学术规范性。
使用方法
研究者可通过加载TSV格式的数据文件,按行或按诗歌作品单位进行模型训练与验证。该数据集适用于文本情感分类任务的模型开发,尤其适合用于跨文化情感分析研究和生成式AI的诗歌情感生成实验。使用前建议参考项目GitHub仓库中的预处理代码,并注意训练集与测试集需自行划分以满足具体研究需求。
背景与挑战
背景概述
韩国诗歌情感映射数据集KPoEM由韩国数字人文实验室团队于2025年构建,主要研究者IRO LIM与Byungjun Kim等人系统收录了金素月、尹东柱等五位代表性现代诗人的483首作品。该数据集聚焦于文学计算与情感计算交叉领域,通过标注7,007行诗句的情感标签,为韩国现代诗歌的数字化分析与生成式AI应用建立了重要基准,推动了计算文学研究方法论的发展。
当前挑战
数据集核心挑战在于诗歌文本的多义性情感标注,需解决文学语言中隐喻、反讽等修辞手法带来的情感歧义问题。构建过程中面临诗歌版权清理、方言与古语词汇标准化、跨学科标注团队协作等难题,同时需保持文学文本原有意境与计算标注规范之间的平衡。
常用场景
经典使用场景
在数字人文与情感计算交叉领域,KPoEM数据集为韩国现代诗歌的情感分析提供了标准化研究基础。该数据集通过标注五位代表性诗人的7007行诗句情感标签,典型应用于诗歌情感模式挖掘、诗人风格对比研究以及跨时代情感表达演变分析。研究者可借助机器学习模型识别诗歌中隐含的忧郁、渴望、孤独等细腻情感层次,深化对韩国现代文学情感美学的理解。
解决学术问题
该数据集有效解决了文学计算中情感标注粒度粗糙的问题,实现了诗句级别的精准情感映射。通过系统化标注金素月、尹东柱等诗人的作品,为量化研究韩国现代诗歌的情感结构提供了实证基础,填补了非英语文学情感数据集的空白。其意义在于建立了文学文本与计算分析方法之间的桥梁,推动数字人文领域向细粒度、多维度方向发展。
衍生相关工作
该数据集已衍生出多项经典研究工作,包括基于Transformer的诗歌情感分类模型、诗人风格迁移生成系统,以及跨语言情感对比分析框架。相关研究通过结合深度学习方法,探索了传统文学与现代人工智能技术的融合路径,例如利用情感标签训练生成模型模仿特定诗人的情感表达风格,为 computational literary studies 领域提供了新的方法论范式。
以上内容由遇见数据集搜集并总结生成


