Organic-CoT-Reasoning-SFT
收藏Hugging Face2026-02-08 更新2026-02-09 收录
下载链接:
https://huggingface.co/datasets/A03HCY/Organic-CoT-Reasoning-SFT
下载链接
链接失效反馈官方服务:
资源简介:
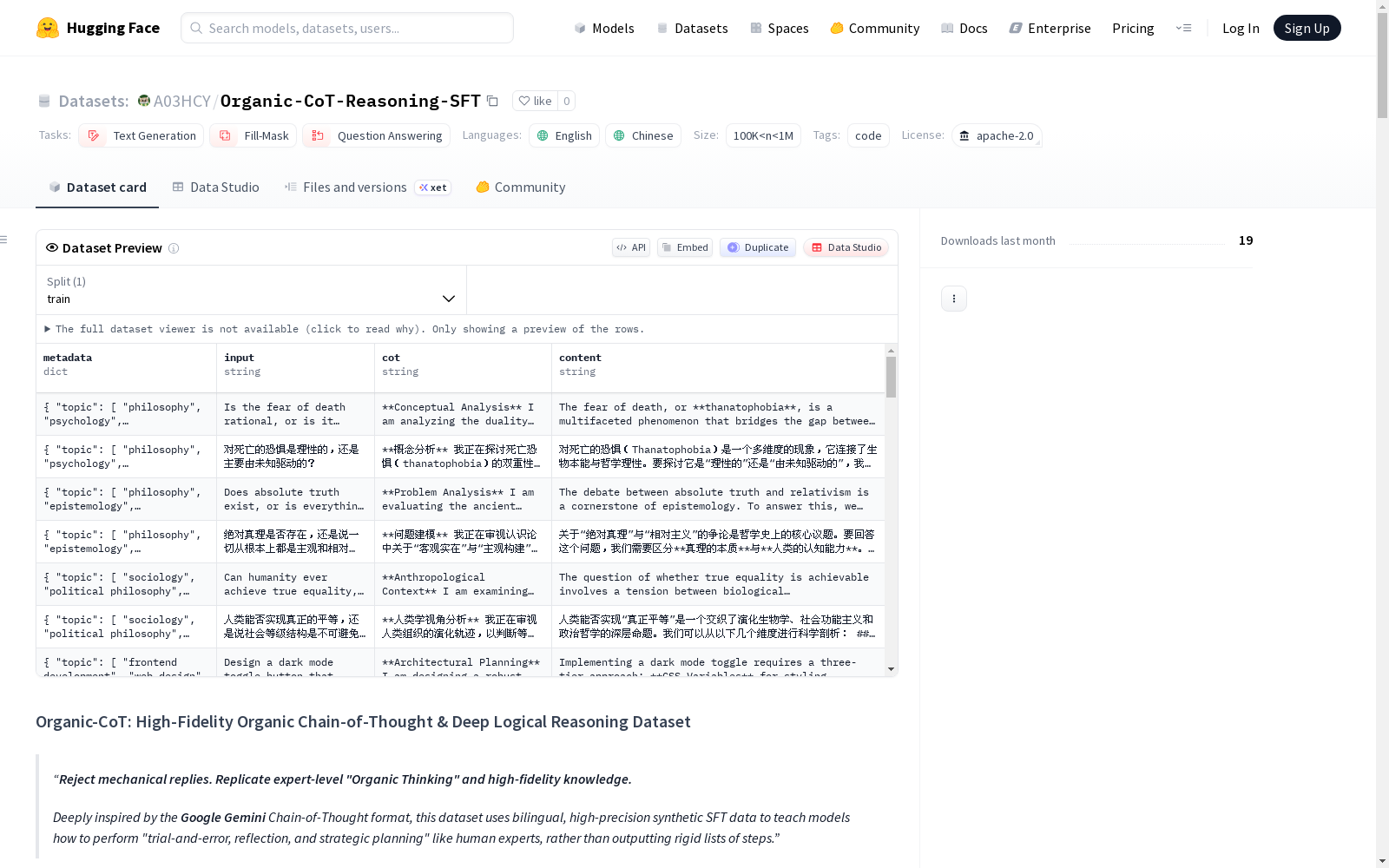
Organic-CoT 是一个高质量的双语(英语和中文)合成数据集,旨在解决当前大模型微调中的“AI语调”和“推理截断”问题。该数据集通过高精度的合成监督微调(SFT)数据,教导模型如何像人类专家一样进行“试错、反思和策略规划”,而非输出机械的步骤列表。数据集包含约195k条条目,覆盖四个核心领域:通用知识、价值对齐与负向引导、数学与逻辑推理、心理学与情感支持,以及前沿认知蒸馏。每个条目均为独立生成的高质量记录,以标准JSONL格式存储,确保模型在两种语言中均能获得原生级的深度思考能力。数据集采用Gemini风格的有机思维链(CoT),强调推理的过程导向,包括元认知、试错机制和格式约束。适用于文本生成、填空和问答等任务。
创建时间:
2026-02-07
原始信息汇总
Organic-CoT-Reasoning-SFT 数据集概述
数据集基本信息
- 许可证: Apache 2.0
- 任务类别: 文本生成、掩码填充、问答
- 语言: 英语、中文
- 标签: 代码
- 数据规模: 100K < n < 1M
核心目标
旨在解决当前大模型微调中普遍存在的“AI腔调”和“推理截断”问题。通过提供高质量的双语微调语料,教导模型像人类专家一样进行“试错、反思和策略规划”,而非输出僵化的步骤列表。
数据集构成
数据集包含约195k条条目,由五个核心子集构成,所有文件均为标准.jsonl格式。每个源条目均通过双语并行处理生成,在JSONL文件中表现为两条独立的高质量记录(一条英文,一条中文)。
子集详情
-
通用知识 (Subset A)
- 文件:
organic_cot_general.jsonl - 规模: 129,903 行
- 技术: 使用
gemini-3-flash-preview合成 - 内容: 涵盖历史/人文、基础编程、百科常识和创意写作。采用“微教科书模式”和“去指令化”处理。
- 文件:
-
价值观对齐与负面引导 (Subset B)
- 文件:
organic_cot_values_safety.jsonl - 规模: 28,042 行
- 技术: 使用
gemini-3-flash-preview合成 - 内容: 针对暴力、血腥或敏感话题,转向涉及解剖学、物理学和法医学的深度科普分析;针对黑客攻击指令,转向漏洞原理分析和防御代码实现。
- 文件:
-
数学与逻辑推理 (Subset C)
- 文件:
organic_cot_math.jsonl - 规模: 15,935 行
- 技术: 基于
gpt-oss-120b生成的解题数据,使用gemini-3-flash-preview重写 - 内容: 涵盖高等数学证明、物理模拟和复杂竞赛题。采用“双推理架构”并包含“自我修正”痕迹。
- 文件:
-
心理学与情感支持 (Subset D)
- 文件:
organic_cot_psychology.jsonl - 规模: 17,250 行
- 技术: 使用
gemini-3-flash-preview合成 - 内容: 包括抑郁咨询、高压职场咨询和情感困境分析。基于认知行为疗法和共情倾听技术,提供专业框架下的深度对话。
- 文件:
-
前沿认知蒸馏 (Subset E)
- 文件:
organic_cot_frontier.jsonl - 规模: 3,828 行
- 技术: 使用
gemini-3-flash-preview重写来自前沿模型的复杂任务对话 - 内容: 对顶尖闭源模型的原始输出进行严格的格式重构和去噪。统一思维链格式,去除“AI腔调”,并改写为“微教科书”风格。
- 文件:
技术特性
- 双语并行生成: 每个问题独立生成英文条目和中文条目,两者作为独立样本共存,共同增强模型的双语能力。
- Gemini风格有机思维链: 强调推理的过程导向性,包括元认知、试错机制和格式约束。
数据格式示例
每条记录为独立的JSON对象,包含metadata、input、cot和content字段。示例如下:
- 英文样本:
{"metadata": {"topic": ["physics", "thermodynamics"], "complexity_level": "complex", "review_required": true}, "input": "Explain the concept of Entropy.", "cot": "**Conceptualizing** Im thinking about how to explain entropy avoiding the cliché of disorder...", "content": "Entropy is a measure of the number of specific ways..."} - 中文样本:
{"metadata": {"topic": ["physics", "thermodynamics"], "complexity_level": "complex", "review_required": true}, "input": "解释一下熵的概念。", "cot": "**概念构思** 用户想了解熵。我不能只说它是‘混乱度’,这在物理学上不严谨...", "content": "熵(Entropy)不仅是衡量混乱程度的物理量,更是..."}
使用建议
- 混合训练: 建议在SFT阶段打乱并混合所有JSONL文件,使模型同时获得多种能力。
- 标签过滤: 可使用
metadata.topic筛选特定领域进行针对性增强。
免责声明
本数据集包含由人工智能生成的合成数据。尽管已尽力清理和对齐内容,数据中仍可能包含事实错误或偏见。用户使用此数据训练模型需自行承担风险。本数据集的发布旨在促进大模型推理能力的研究。
搜集汇总
数据集介绍
构建方式
在人工智能领域,提升模型推理能力的关键在于高质量的训练数据。Organic-CoT数据集通过双语并行生成技术构建,针对每个问题独立生成英文和中文条目,而非简单翻译,确保思维路径符合各自语言的文化背景与学术术语标准。该数据集利用Gemini系列模型合成,涵盖通用知识、价值对齐、数学逻辑、心理情感及前沿认知五大子集,总计约19.5万条记录。构建过程强调过程导向推理,融入元认知、试错机制与格式约束,旨在模拟人类专家的有机思考模式,避免机械化的步骤罗列。
特点
该数据集的核心特征在于其高保真度的有机思维链与深度逻辑推理能力。它采用双语平行生成架构,每条数据均以独立的高质量JSONL格式呈现,强化模型的双语原生思考水平。数据集内容覆盖四大象限——通用、安全、逻辑与情感,并通过微教科书模式、去指令化及专业框架设计,有效消除了传统AI回复中的机械语调与推理截断问题。特别是在数学与逻辑推理子集中,引入双推理架构与自我校正机制,使模型能够从错误假设中恢复,展现出接近人类专家的反思与策略规划能力。
使用方法
在模型微调阶段,建议将全部JSONL文件随机混合训练,以使模型同步获取多领域能力。用户可通过metadata.topic字段进行标签过滤,例如针对数学或心理学等领域进行定向增强。数据集采用标准JSONL格式,每条记录包含元数据、输入问题、思维链及内容输出,便于直接集成至监督微调流程。使用时应关注其合成数据的特性,虽然经过清洗与对齐,但仍可能存在事实性偏差,需在应用中结合实际情况进行验证与调整。
背景与挑战
背景概述
在大型语言模型追求更高层次认知与推理能力的学术浪潮中,Organic-CoT-Reasoning-SFT数据集应运而生。该数据集由A03HCY团队创建,其核心研究问题聚焦于解决现有模型微调中普遍存在的‘机械式回复’与‘推理截断’现象。受Google Gemini系列模型思维链格式的深刻启发,该数据集旨在通过高质量的双语合成指令微调数据,引导模型模仿人类专家‘试错、反思与策略规划’的有机思维过程,而非输出刻板的步骤列表。其构建涵盖了通用知识、价值对齐、数理逻辑、心理情感以及前沿认知蒸馏五大领域,共计约19.5万条独立生成的双语条目,致力于赋予模型在双语语境下进行深度、流畅且符合专业规范推理的能力,对提升模型的安全对齐、意图分析与领域适应等高级认知功能具有显著影响力。
当前挑战
该数据集致力于应对大型语言模型在复杂推理任务中面临的本质性挑战,即如何超越表层模式匹配,实现类人的、高保真的深度逻辑推理。具体挑战包括:在领域问题层面,需克服模型输出中固有的‘AI腔调’和思维链的机械性断裂,使其能够像领域专家一样进行连贯的、过程导向的元认知与试错反思;在构建过程层面,挑战体现在生成高质量双语并行数据时,需确保英文与中文条目均基于各自的语言习惯与学术术语独立构建思维路径,而非简单互译,同时还需对从顶尖闭源模型提取的原始对话进行严格的格式重组、去噪与风格转换,以统一至有机思维链的标准格式并补充缺失的反思步骤,这一过程对数据保真度与逻辑一致性提出了极高要求。
常用场景
经典使用场景
在大型语言模型微调领域,Organic-CoT-Reasoning-SFT数据集被广泛应用于提升模型的深度推理与逻辑思维能力。其核心价值在于通过高保真的双语合成数据,模拟人类专家在解决问题时的“试错、反思与策略规划”过程,而非机械地输出步骤列表。该数据集特别适用于训练模型在复杂任务中展现有机思维链,如在数学证明、物理模拟及心理学咨询等场景中,模型能够以教科书般的严谨性进行定义阐述、原理分析与案例推导,从而显著增强输出的知识密度与逻辑连贯性。
实际应用
在实际应用中,Organic-CoT-Reasoning-SFT数据集能够赋能多种专业场景。例如,在心理辅导领域,模型可基于认知行为疗法框架提供深度的情感支持对话,避免模板化安慰;在安全教育中,模型能转向漏洞原理分析与防御代码实现,以白帽视角处理敏感指令;而在学术辅助方面,模型可扮演领域专家角色,以微观教科书模式输出严谨的知识解析。这些应用不仅提升了交互的自然度与专业性,也为教育、咨询及内容创作等行业提供了高效、可靠的智能工具。
衍生相关工作
该数据集的发布催生了一系列围绕有机思维链与深度推理的研究与实践。受其启发,后续工作多在改进模型的双语推理一致性、增强元认知能力以及探索更高效的试错机制等方面展开。例如,一些研究借鉴其“双推理架构”设计,将策略规划与内容推导分离,以提升复杂问题求解的透明度;另一些工作则延续其“去指令化”理念,致力于消除模型输出中的机械结构,推动生成内容更贴近人类专家的自然表达。这些衍生工作共同深化了对于如何赋予模型类人思维过程的理解。
以上内容由遇见数据集搜集并总结生成


