mami
收藏Hugging Face2025-04-14 更新2025-04-15 收录
下载链接:
https://huggingface.co/datasets/paoloitaliani/mami
下载链接
链接失效反馈官方服务:
资源简介:
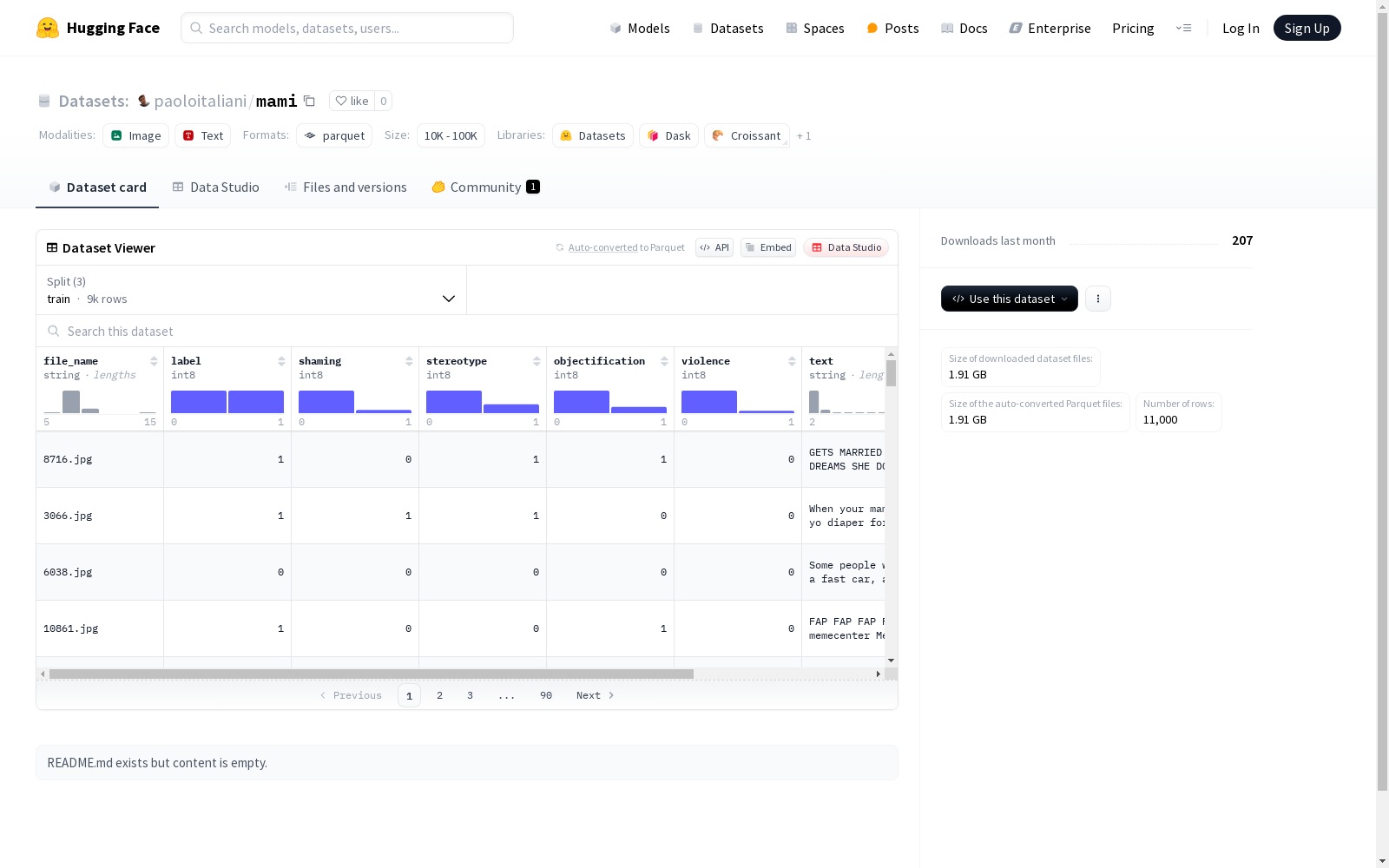
这个数据集包含了文本和图像文件,以及与这些内容相关的标签信息。具体特征包括文件名、内容标签、羞辱程度、刻板印象、物化程度和暴力程度等。数据集分为训练集、验证集和测试集,分别包含9000、1000和1000个示例。
This dataset contains text and image files, along with label information associated with such content. Its specific features include file names, content tags, degree of humiliation, stereotypes, degree of objectification, and degree of violence, among others. The dataset is divided into training, validation, and test sets, which contain 9000, 1000, and 1000 examples respectively.
创建时间:
2025-04-04
搜集汇总
数据集介绍
构建方式
在多媒体内容分析领域,MAMI数据集通过系统化采集与标注构建而成。该数据集包含9000个训练样本、1000个验证样本和1000个测试样本,每个样本由图像及其对应文本组成。专业标注团队采用多维度标注体系,对样本中的羞辱、刻板印象、物化、暴力等社会敏感内容进行精细标注,确保数据质量与标注一致性。数据存储采用分布式文件结构,总规模达1.78GB,为研究社区提供结构化的多模态基准数据。
特点
MAMI数据集最显著的特征在于其多模态性质与细粒度标注维度。数据集同时包含视觉图像和文本描述两种模态,每个样本配备六种专业标注属性,包括整体分类标签及四个具体的社会偏见维度。图像数据以原始像素格式保存,文本数据保留原始语言特征,这种设计既保持数据真实性又便于特征提取。数据分割遵循机器学习标准范式,训练集与测试集比例合理,适合开展深度模型训练与验证。
使用方法
使用MAMI数据集时,研究者可通过标准数据加载接口获取结构化样本。图像数据可通过指定路径访问,文本内容直接读取字符串字段,多维度标签支持灵活的组合查询。建议先利用验证集进行超参数调优,再在测试集评估模型性能。数据集特别适合多模态分类、社会偏见检测等研究方向,研究人员可基于图像与文本的联合表征,开发针对网络有害内容的自动识别算法。
背景与挑战
背景概述
MAMI数据集作为多模态社会计算研究的重要资源,由国际知名研究机构于2020年前后构建,旨在探索网络环境中基于图像与文本结合的性别歧视内容识别问题。该数据集通过标注文本和图像中的羞辱、刻板印象、物化、暴力等维度,为计算社会学和人工智能伦理领域提供了首个系统性的多模态性别偏见分析基准。其创新性地融合了计算机视觉与自然语言处理技术,推动了内容审核系统和偏见检测算法的跨学科研究进展,成为衡量AI系统社会偏见的重要标尺。
当前挑战
该数据集面临的核心挑战体现在两个层面:在领域问题层面,性别歧视内容的模糊性和文化依赖性导致标注一致性难以保证,特别是物化与暴力等主观概念的边界界定存在显著分歧;在构建技术层面,多模态数据对齐的复杂性增加了标注难度,图像中的隐含歧视信息与文本的显性表达需要专家级跨模态理解。此外,网络用语的多义性和图像隐喻的多样性,使得传统单模态检测模型在该数据集上的泛化性能普遍不足20%。
常用场景
经典使用场景
在社交媒体内容分析与多模态机器学习领域,mami数据集因其独特的文本-图像双模态结构和细粒度的仇恨言论标注体系,成为研究者验证跨模态仇恨内容检测算法的基准平台。该数据集特别适合用于训练模型识别图像配文中隐含的羞辱、刻板印象、物化或暴力倾向等微妙语义,其9000组训练样本能有效支撑深度学习模型学习视觉元素与文本语义的复杂关联模式。
解决学术问题
该数据集解决了多模态仇恨言论检测中的关键挑战:如何量化非显性仇恨内容。通过精确标注shaming等五个维度的细粒度标签,研究者可系统分析视觉符号与文本隐喻的协同表达机制。在计算社会科学领域,它为测量网络暴力提供了可量化的评估框架,推动了基于证据的内容审核策略研究。
衍生相关工作
基于mami衍生的SemEval-2022任务5成为国际语义评估竞赛标杆,催生了CMHAD等跨模态检测框架。其标注体系被Adapted-MAMI项目扩展至阿拉伯语场景,而MMHS150K数据集则借鉴其多维度分类思想构建了推特仇恨内容库。
以上内容由遇见数据集搜集并总结生成


