myeongkyunkang/LLaVA-Med-60K-IM-text
收藏Hugging Face2024-07-13 更新2024-07-22 收录
下载链接:
https://hf-mirror.com/datasets/myeongkyunkang/LLaVA-Med-60K-IM-text
下载链接
链接失效反馈官方服务:
资源简介:
LLaVA-Med-60K-IM-text数据集是基于[llava_med_instruct_60k_inline_mention.json](https://hanoverprod.z21.web.core.windows.net/med_llava/instruct/llava_med_instruct_60k_inline_mention.json)生成的文本格式数据集。该数据集使用Meta-Llama-3-70B-Instruct模型将问答对重写为段落格式,并排除了无法下载的PMC文章和非医学图像。尽管进行了这些处理,数据集仍不完全干净。
The LLaVA-Med-60K-IM-text dataset is a text format derived from the llava_med_instruct_60k_inline_mention.json file, specifically designed for rewriting question-answer pairs into paragraph format in the medical field. This dataset was built using the Meta-Llama-3-70B-Instruct model, excluding PMC articles that failed to download and non-medical images, though it is not perfectly error-free.
提供机构:
myeongkyunkang
原始信息汇总
LLaVA-Med-60K-IM-text
概述
- 数据集名称:LLaVA-Med-60K-IM-text
- 数据格式:文本格式
- 数据来源:基于llava_med_instruct_60k_inline_mention.json构建
- 构建方法:使用
Meta-Llama-3-70B-Instruct模型,指令为“将问答对重写为段落格式(不要在响应中使用问题和答案这两个词)”
数据处理
- 排除未能下载的PMC文章
- 自动排除非医学图像(如图表)
- 数据集并非完全干净
引用
-
作者:Kang, Myeongkyun
-
发布年份:2024
-
引用格式:
@misc{LLaVA-Med-60K-IM-text, title={LLaVA-Med-60K-IM-text}, author={Kang, Myeongkyun}, howpublished={url{https://huggingface.co/datasets/myeongkyunkang/LLaVA-Med-60K-IM-text}}, year={2024} }
搜集汇总
数据集介绍
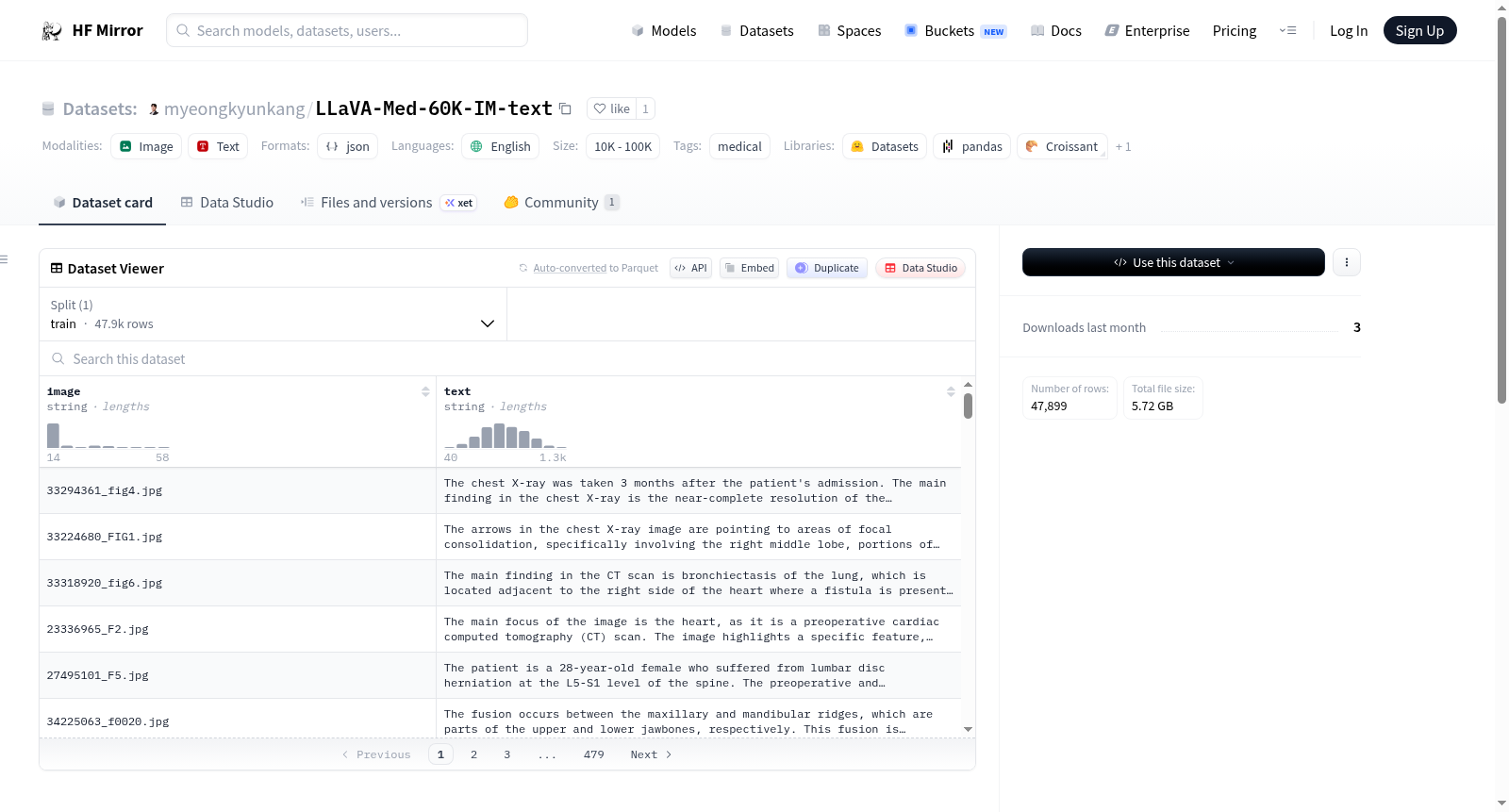
构建方式
在医学信息处理领域,构建高质量文本数据集对于推动多模态模型的发展至关重要。LLaVA-Med-60K-IM-text数据集源于原始的多模态医学指令数据,通过Meta-Llama-3-70B-Instruct模型进行自动化转换,将原有的问答对改写为连贯的段落格式,同时避免使用“问题”和“答案”等词汇。构建过程中,系统排除了无法获取的PMC文章以及通过自动筛选识别的非医学图像,尽管经过这些处理,数据集仍可能存在一定噪声,反映了真实世界数据处理的复杂性。
使用方法
在医学人工智能研究中,该数据集主要服务于文本生成与理解模型的训练与评估。研究人员可直接加载该文本语料,用于微调预训练语言模型,以增强其在医学领域的叙事生成能力。数据集适用于多种下游任务,如医学报告自动生成、临床知识问答系统的增强,或作为多模态医学模型训练中的纯文本输入模块。使用时应结合具体研究目标,注意数据集的潜在噪声,并建议通过交叉验证等方式确保模型性能的稳健性。
背景与挑战
背景概述
在医学人工智能领域,多模态学习正成为推动精准医疗发展的关键驱动力。2024年,由研究人员Myeongkyun Kang构建的LLaVA-Med-60K-IM-text数据集应运而生,其核心研究问题聚焦于将医学视觉问答对转化为连贯的文本段落,旨在增强大型语言模型对医学图像与文本关联性的深层理解。该数据集源自LLaVA-Med项目,通过利用Meta-Llama-3-70B-Instruct模型进行指令重构,剔除了非医学图像与无法获取的PMC文章,为医学自然语言处理与多模态分析提供了重要的数据基础,促进了医学知识表示与推理能力的提升。
当前挑战
该数据集致力于解决医学多模态理解中视觉与文本信息融合的挑战,尤其在生成连贯、准确的医学描述文本方面存在难度,需要模型克服专业术语歧义与复杂图像内容的解释问题。在构建过程中,面临数据清洗的严峻考验,如下载失败的PMC文章需被排除,非医学图像的自动过滤可能引入噪声,导致数据集并非完全纯净,这些因素共同影响了最终数据的质量与可靠性。
常用场景
经典使用场景
在医学人工智能领域,多模态学习正成为提升模型理解复杂临床信息的关键路径。LLaVA-Med-60K-IM-text数据集以其独特的文本化医学视觉问答对格式,为研究者提供了经典的应用场景:训练和评估大型语言模型在医学图像描述生成与推理任务中的性能。通过将原始的问答对转化为连贯的段落叙述,该数据集能够模拟临床报告撰写或医学图像解读的自然语言输出过程,从而支持模型学习如何从视觉信息中提取关键医学概念并以专业文本形式呈现。
解决学术问题
该数据集主要致力于解决医学人工智能中多模态对齐与知识融合的学术挑战。传统医学图像分析往往局限于视觉特征识别,而缺乏与丰富文本知识的深度结合。LLaVA-Med-60K-IM-text通过提供大规模、结构化的医学图像-文本对,使研究人员能够探索视觉语言模型在医学领域的适应性问题,例如如何让模型准确理解放射学图像中的病理特征并用专业术语进行描述。这不仅推动了跨模态表示学习的发展,也为构建可信赖的临床决策辅助系统奠定了数据基础。
实际应用
在实际医疗环境中,该数据集具有显著的应用潜力。它可用于开发智能医学影像报告生成系统,辅助放射科医生快速起草初步诊断描述,提升工作效率。同时,基于该数据集训练的模型能够服务于医学教育,为医学生提供自动化的图像解读练习材料。此外,在临床决策支持领域,此类技术有助于整合视觉证据与文本知识,为医生提供更全面的患者信息视图,从而优化诊疗流程。
数据集最近研究
最新研究方向
在医学人工智能领域,多模态学习正成为推动临床决策支持系统发展的核心驱动力。LLaVA-Med-60K-IM-text数据集通过将医学图像与文本指令对转化为连贯的段落描述,为构建端到端的医学视觉语言模型提供了关键训练资源。该数据集基于前沿的大语言模型Meta-Llama-3-70B-Instruct生成,其设计紧密关联于当前医学人工智能中视觉问答与报告自动生成的热点研究方向。研究者们正利用此类结构化文本数据,探索模型在医学图像理解、跨模态语义对齐以及临床知识推理方面的性能提升,这些进展有望缓解医疗资源分布不均的挑战,并为辅助诊断工具的智能化发展奠定数据基础。
以上内容由遇见数据集搜集并总结生成


