CaptionEmporium/furry-e621-sfw-7m-hq
收藏Hugging Face2024-03-21 更新2024-06-11 收录
下载链接:
https://hf-mirror.com/datasets/CaptionEmporium/furry-e621-sfw-7m-hq
下载链接
链接失效反馈官方服务:
资源简介:
该数据集名为furry-e621-sfw-7m-hq,包含692万条来自e621(也称为e926)的适合工作场所(SFW)图片的标注。这些标注由LLM(mistralai/Mistral-7B-v0.1)和CogVLM(THUDM/CogVLM)生成,每张图片有8个LLM生成的标注和1个CogVLM生成的标注。标注语言为英语,且大多数标注长度超过77个token,不适合使用当前的CLIP方法进行区分。数据集还包括通过DINOv2 giant模型训练的多标签分类器生成的标签,这些标签被手动分类为12个类别。数据集的创建过程、已知的偏见和限制也在README中进行了讨论。
该数据集名为furry-e621-sfw-7m-hq,包含692万条来自e621(也称为e926)的适合工作场所(SFW)图片的标注。这些标注由LLM(mistralai/Mistral-7B-v0.1)和CogVLM(THUDM/CogVLM)生成,每张图片有8个LLM生成的标注和1个CogVLM生成的标注。标注语言为英语,且大多数标注长度超过77个token,不适合使用当前的CLIP方法进行区分。数据集还包括通过DINOv2 giant模型训练的多标签分类器生成的标签,这些标签被手动分类为12个类别。数据集的创建过程、已知的偏见和限制也在README中进行了讨论。
提供机构:
CaptionEmporium
原始信息汇总
数据集概述
基本信息
- 数据集名称: furry-e621-sfw-7m-hq
- 许可证: CC-BY-SA-4.0
- 语言: 英语
- 任务类别: image-to-text
- 数据集大小: 6.92 M captions
数据集描述
- 联系人: Caption Emporium
- 数据集内容: 包含6.92 M张安全内容(SFW)的图像描述,这些描述由LLMs和CogVLM生成,每张图像有8个LLM描述和1个CogVLM描述。
- 语言: 所有描述均为英语。
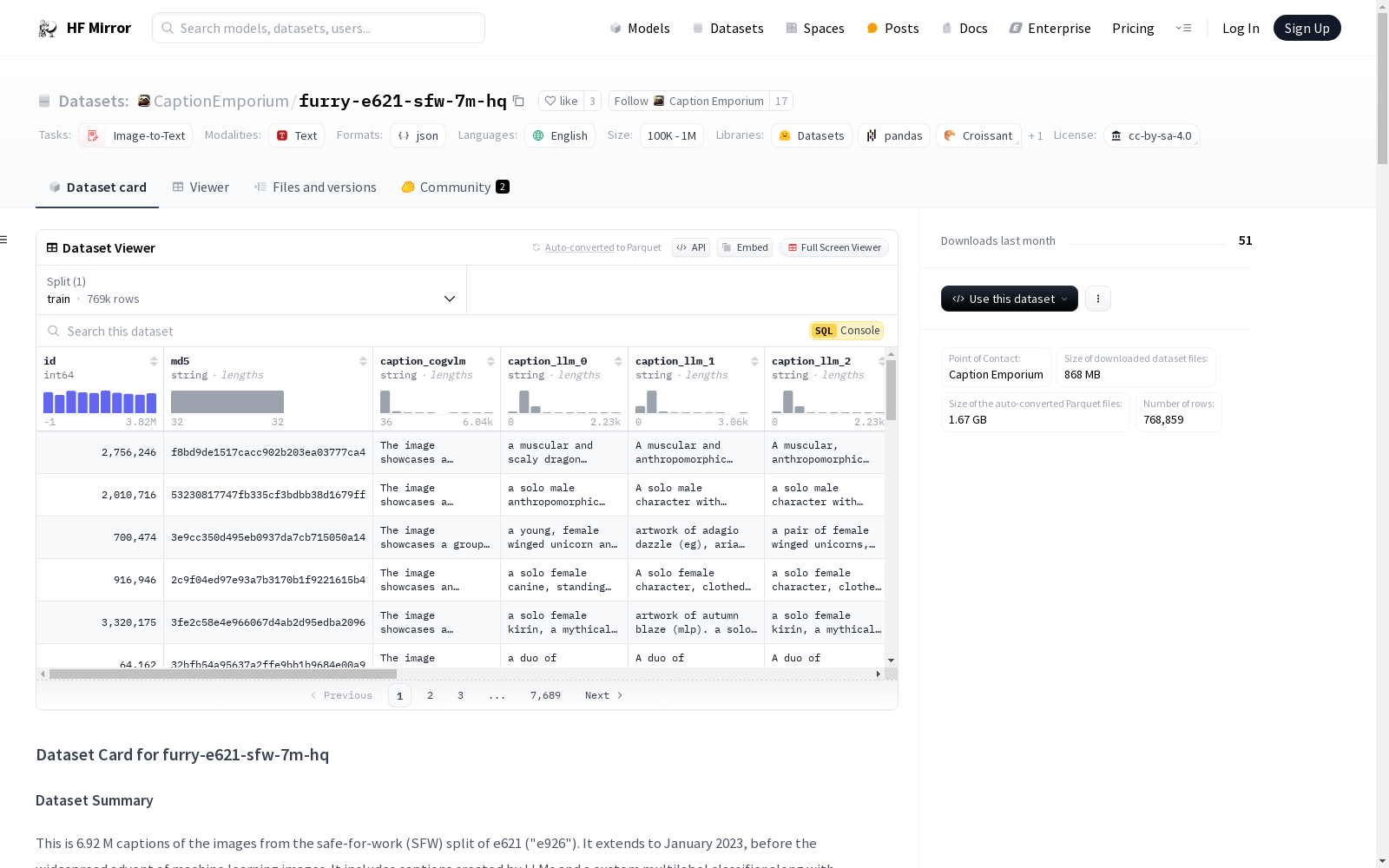
数据实例
- 示例结构: 每个实例包含图像ID、MD5哈希值以及多个描述文本,包括CogVLM和LLM生成的描述。
数据标签
- 标签分类: 标签被手动分类为多个类别,如动物与拟人特征、服装与配饰、角色与性别等。
- 标签处理: 使用DINOv2 giant模型进行多标签分类,训练使用APL损失,最佳模型达到AP 0.342和F1 0.5576。
数据生成
- LLM描述生成: 使用mistralai/Mistral-7B-v0.1权重,根据分类标签生成描述,每张图像生成8个描述,交替使用合成标签和真实标签。
- CogVLM描述生成: 使用THUDM/CogVLM权重,根据真实分类标签生成描述,可能包含重复前缀,可通过特定脚本去除。
数据分割
- 训练集大小: 768,859个实例
数据集创建
- 源数据: 从e621收集,遵循其内容存档的速率限制。
- 已知限制: LLM和CogVLM描述可能包含幻觉文本或重复标签,部分图像可能未计算LLM描述。
附加信息
- 数据集维护者: Caption Emporium
- 许可证: 遵循Creative Commons ShareAlike (CC BY-SA 4.0)
搜集汇总
数据集介绍
构建方式
该数据集‘furry-e621-sfw-7m-hq’由Caption Emporium构建,包含从e621网站的‘e926’安全内容中提取的6.92百万条图像描述。数据集的构建结合了大型语言模型(LLMs)和CogVLM模型生成的描述,每张图像对应8条LLM描述和1条CogVLM描述。描述内容通过多标签分类器进行筛选,该分类器基于DINOv2 giant模型,经过1000个epoch的训练,使用APL损失函数,最终达到0.342的AP和0.5576的F1分数。标签被手动分类为12个类别,包括动物与拟人化特征、服装与配饰等,确保描述内容的安全性和多样性。
特点
该数据集的主要特点在于其大规模和多样性,每张图像包含9条详细描述,涵盖了从动物特征到背景设置的多个方面。描述长度通常超过77个token,不适合当前基于CLIP的分类方法。此外,数据集中的描述通过LLM和CogVLM生成,结合了人工分类标签,确保了描述的准确性和丰富性。尽管数据集标记为‘安全’,但未对所有图像进行安全性检查,可能包含不适当内容。
使用方法
该数据集适用于图像到文本的任务,如图像描述生成和图像理解。用户可以通过访问HuggingFace平台下载数据集,并使用提供的描述进行模型训练和评估。数据集中的描述可以通过特定的提示词生成,用户可以根据需要调整提示词以生成不同的描述。此外,数据集提供了处理重复前缀的脚本,便于用户进行后处理。在使用过程中,用户应注意数据集可能存在的偏见和局限性,特别是在描述的准确性和内容安全性方面。
背景与挑战
背景概述
furry-e621-sfw-7m-hq数据集由Caption Emporium创建,涵盖了从e621网站的‘安全内容’(SFW)分割中提取的6.92百万张图像的描述。该数据集的构建时间延伸至2023年1月,旨在捕捉机器学习图像广泛应用之前的图像描述。数据集中的描述由大型语言模型(LLMs)和自定义多标签分类器生成,每张图像包含8个LLM(基于mistralai/Mistral-7B-v0.1)和1个CogVLM(THUDM/CogVLM)生成的描述。这些描述不仅长度超过77个词元,且不适合当前基于CLIP的方法进行分类。数据集的标签经过精心筛选,保留了约7000个与安全内容相关的标签,并通过DINOv2巨型视觉编码器进行多标签分类器的训练,以确保描述的准确性和多样性。
当前挑战
furry-e621-sfw-7m-hq数据集在构建过程中面临多项挑战。首先,描述的长度超过77个词元,使得现有基于CLIP的分类方法难以有效处理。其次,LLM生成的描述中存在文本幻觉现象,部分描述可能包含重复词元或标签列表,影响数据质量。此外,CogVLM生成的描述虽然具有较高的OCR准确性,但仍可能偶尔出现文本幻觉或细节错误。数据集的标签分类过程也面临挑战,需确保标签的准确性和覆盖范围,同时避免偏见。最后,尽管数据集被标记为‘安全’,但并未对所有图像进行安全性检查,可能存在不适当的内容。
常用场景
经典使用场景
furry-e621-sfw-7m-hq数据集主要用于图像描述生成任务,特别是在图像到文本的转换领域。该数据集包含了6.92百万条高质量的英文描述,这些描述由大型语言模型(LLM)和CogVLM生成,适用于训练和评估图像描述生成模型。由于每张图像都有多个描述,研究人员可以利用这些多样化的描述来提升模型的鲁棒性和多样性。
衍生相关工作
基于furry-e621-sfw-7m-hq数据集,研究者们已经开展了多项相关工作,包括改进图像描述生成模型的架构、优化多标签分类器的性能,以及探索如何减少生成描述中的偏见和错误。此外,该数据集还激发了对多模态学习、跨模态检索等领域的深入研究,推动了图像与文本结合的技术发展。
数据集最近研究
最新研究方向
在图像描述生成领域,furry-e621-sfw-7m-hq数据集的最新研究方向主要集中在多标签分类与大规模语言模型(LLM)的结合应用上。该数据集通过整合Mistral-7B和CogVLM等先进模型,生成了大量高质量的图像描述,这些描述不仅涵盖了丰富的视觉特征,还通过多标签分类器对图像内容进行了细致的语义标注。研究者们正探索如何利用这些标注信息提升图像描述的准确性和多样性,尤其是在处理复杂场景和多对象图像时。此外,该数据集的广泛应用也推动了图像描述生成技术在虚拟角色设计、游戏开发等领域的实际应用,进一步拓展了其在数字创意产业中的影响力。
以上内容由遇见数据集搜集并总结生成


