plant-genomic-benchmark
收藏魔搭社区2025-11-24 更新2025-07-05 收录
下载链接:
https://modelscope.cn/datasets/lgq12697/plant-genomic-benchmark
下载链接
链接失效反馈官方服务:
资源简介:
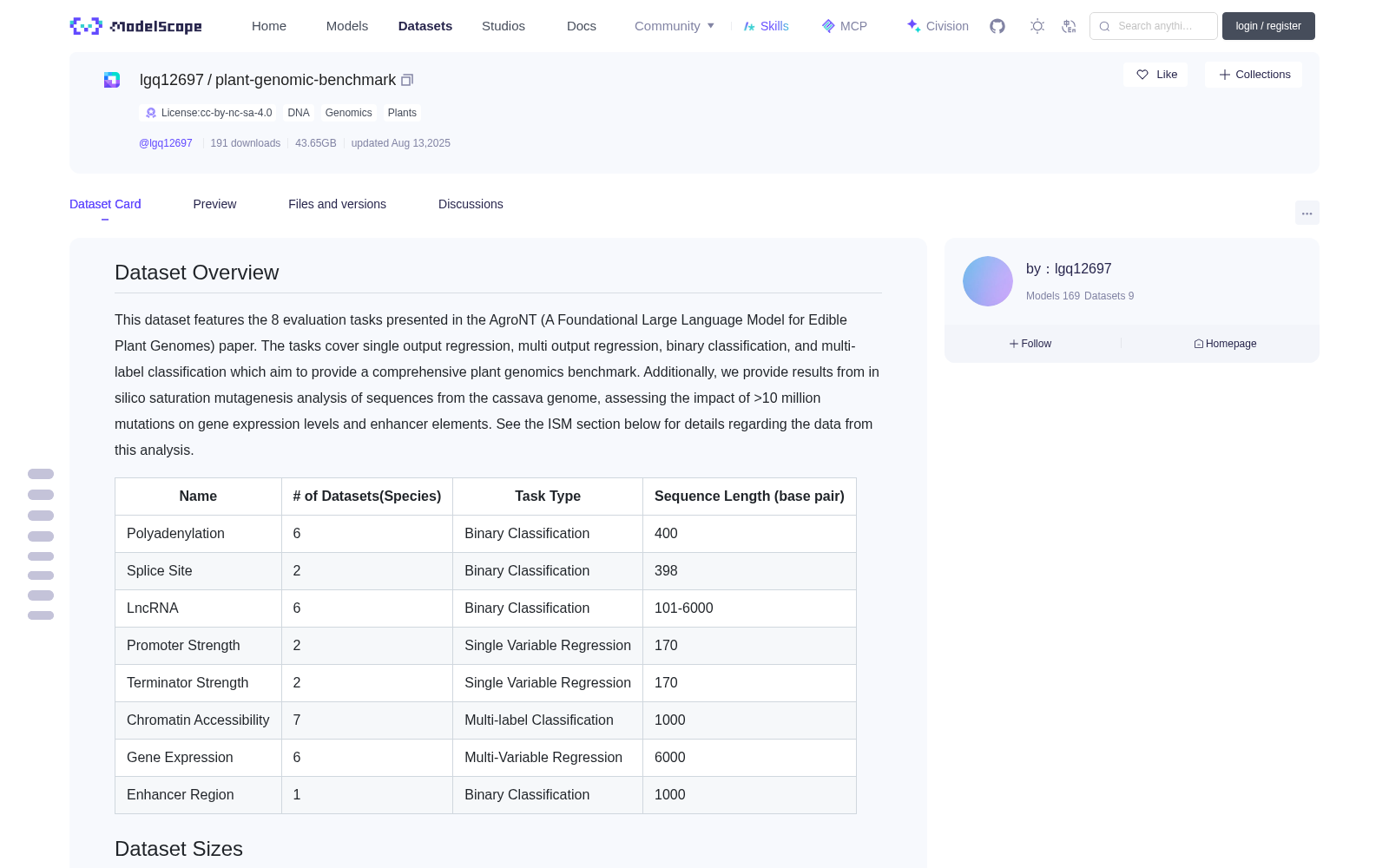
## Dataset Overview
This dataset features the 8 evaluation tasks presented in the AgroNT (A Foundational Large Language Model for Edible Plant
Genomes) paper. The tasks cover single output regression, multi output regression, binary classification, and multi-label classification which
aim to provide a comprehensive plant genomics benchmark. Additionally, we provide results from in silico saturation mutagenesis analysis of sequences
from the cassava genome, assessing the impact of >10 million mutations on gene expression levels and enhancer elements. See the ISM section
below for details regarding the data from this analysis.
| Name | # of Datasets(Species) | Task Type | Sequence Length (base pair) |
| -------- | ------- | -------- | ------- |
| Polyadenylation | 6 | Binary Classification | 400 |
| Splice Site | 2 | Binary Classification | 398 |
| LncRNA | 6 | Binary Classification | 101-6000 |
| Promoter Strength | 2 | Single Variable Regression | 170 |
| Terminator Strength | 2 | Single Variable Regression | 170 |
| Chromatin Accessibility | 7 | Multi-label Classification | 1000 |
| Gene Expression | 6 | Multi-Variable Regression | 6000 |
| Enhancer Region | 1 | Binary Classification | 1000 |
## Dataset Sizes
| Task Name | # Train Samples | # Validation Samples | # Test Samples |
| -------- | ------- | -------- | ------- |
|poly_a.arabidopsis_thaliana|170835|---|30384|
|poly_a.oryza_sativa_indica_group|98139|---|16776|
|poly_a.trifolium_pratense|111138|---|13746|
|poly_a.medicago_truncatula|47277|---|8850|
|poly_a.chlamydomonas_reinhardtii|90378|---|10542|
|poly_a.oryza_sativa_japonica_group|120621|---|20232|
|splicing.arabidopsis_thaliana_donor|2588034|---|377873|
|splicing.arabidopsis_thaliana_acceptor|1704844|---|250084|
|lncrna.m_esculenta|4934|---|360|
|lncrna.z_mays|8423|---|1629|
|lncrna.g_max|11430|---|490|
|lncrna.s_lycopersicum|7274|---|1072|
|lncrna.t_aestivum|11252|---|1810|
|lncrna.s_bicolor|8654|---|734|
|promoter_strength.leaf|58179|6825|7154|
|promoter_strength.protoplast|61051|7162|7595|
|terminator_strength.leaf|43294|5309|4806|
|terminator_strength.protoplast|43289|5309|4811|
|gene_exp.glycine_max|47136|4803|4803|
|gene_exp.oryza_sativa|31244|3702|3702|
|gene_exp.solanum_lycopersicum|27321|3827|3827|
|gene_exp.zea_mays|34493|4483|4483|
|gene_exp.arabidopsis_thaliana|25731|3401|3402|
|chromatin_access.oryza_sativa_MH63_RS2|5120000|14848|14848|
|chromatin_access.setaria_italica|5120000|19968|19968|
|chromatin_access.oryza_sativa_ZS97_RS2|5120000|14848|14848|
|chromatin_access.arabidopis_thaliana|5120000|9984|9984|
|chromatin_access.brachypodium_distachyon|5120000|14848|14848|
|chromatin_access.sorghum_bicolor|5120000|29952|29952|
|chromatin_access.zea_mays|6400000|79872|79872|
|pro_seq.m_esculenta|16852|1229|812|
*** It is important to note that fine-tuning for lncrna was carried out using all datasets in a single training. The reason for this is that the datasets are small and combining
them helped to improve learning.
## Example Usage
```python
from datasets import load_dataset
task_name='terminator_strength.protoplast' # one of the task names from the above table
dataset = load_dataset("InstaDeepAI/plant-genomic-benchmark",task_name=task_name)
```
## In Silico Saturation Mutagensis
### File structure for: ISM_Tables/Mesculenta_305_v6_PROseq_ISM_LOG2FC.txt.gz
Intergenic enhancer regions based on Lozano et al. 2021 (https://pubmed.ncbi.nlm.nih.gov/34499719/) <br>
Genome version: Manihot esculenta reference genome v6.1 from Phytozome <br>
CHR: Chromosome <br>
POS: Physical position (bp) <br>
REF: Reference allele <br>
ALT: Alternative allele <br>
LOG2FC: Log fold change in Intergenic enhancer probability (log2(p_mutated_sequence / p_original_sequence)) <br>
### File structure for: ISM_Tables/Mesculenta_v6_GeneExpression_ISM_LOG2FC.txt.gz
Gene expression prediction based on: Wilson et al. 2016 (https://pubmed.ncbi.nlm.nih.gov/28116755/) <br>
Genome version: Manihot esculenta reference genome v6 from Ensembl 56 <br>
CHR: Chromosome <br>
POS: Physical position (bp) <br>
REF: Reference allele <br>
ALT: Alternative allele <br>
GENE: Gene ID <br>
STRAND: Gene strand <br>
TISSUE: Tissue type (Acronyms detailed in Figure 1 of Wilson et al.) <br>
LOG2FC: Gene expression log fold change (log2(gene_exp_mutated_sequence / gene_exp_original_sequence)) <br>
## Data source for Figures 2-8
### File structure for: Figures/Figure[FIGURE_NUMBER]_panel[PANEL_LETTER].txt
Text files containing the data used to plot Figures 2 to 8 from Mendoza-Revilla & Trop et al., 2024.
The text files are named using the following format: Figure[FIGURE_NUMBER]_panel[PANEL_LETTER].txt
[FIGURE_NUMBER]: This is the number of the figure in the publication. For example, if the data corresponds to Figure 3, this part of the file name will be "Figure3".
[PANEL_LETTER]: This is the letter corresponding to a specific panel within the figure. Figures often contain multiple panels labeled with letters (e.g., a, b, c). For example, if the data corresponds to panel b of Figure 3, this part of the file name will be "panelb".
# 数据集概览
本数据集包含AgroNT(一种针对食用植物基因组的基础大语言模型)论文中提出的8项评估任务。这些任务涵盖单输出回归、多输出回归、二分类以及多标签分类,旨在构建一套全面的植物基因组基准测试集。此外,我们还提供了针对木薯基因组序列开展的计算机饱和诱变(in silico saturation mutagenesis)分析结果,评估了超过1000万种突变对基因表达水平及增强子元件的影响。有关该分析数据的详细信息,请参见下文的计算机饱和诱变章节。
| 任务名称 | 数据集数量(物种数) | 任务类型 | 序列长度(碱基对) |
| ----------------------- | -------------------- | ---------------------- | ------------------ |
| 多聚腺苷酸化(Polyadenylation) | 6 | 二分类 | 400 |
| 剪接位点(Splice Site) | 2 | 二分类 | 398 |
| 长链非编码RNA(Long non-coding RNA, LncRNA) | 6 | 二分类 | 101-6000 |
| 启动子强度(Promoter Strength) | 2 | 单变量回归 | 170 |
| 终止子强度(Terminator Strength) | 2 | 单变量回归 | 170 |
| 染色质可及性(Chromatin Accessibility) | 7 | 多标签分类 | 1000 |
| 基因表达(Gene Expression) | 6 | 多变量回归 | 6000 |
| 增强子区域(Enhancer Region) | 1 | 二分类 | 1000 |
# 数据集规模
| 任务名称 | 训练样本数 | 验证样本数 | 测试样本数 |
| ----------------------- | ---------- | ---------- | ---------- |
| poly_a.拟南芥(Arabidopsis thaliana) | 170835 | --- | 30384 |
| poly_a.籼稻(Oryza sativa indica group) | 98139 | --- | 16776 |
| poly_a.红三叶(Trifolium pratense) | 111138 | --- | 13746 |
| poly_a.蒺藜苜蓿(Medicago truncatula) | 47277 | --- | 8850 |
| poly_a.莱茵衣藻(Chlamydomonas reinhardtii) | 90378 | --- | 10542 |
| poly_a.粳稻(Oryza sativa japonica group) | 120621 | --- | 20232 |
| splicing.拟南芥供体位点(Arabidopsis thaliana donor) | 2588034 | --- | 377873 |
| splicing.拟南芥受体位点(Arabidopsis thaliana acceptor) | 1704844 | --- | 250084 |
| lncrna.木薯(Manihot esculenta) | 4934 | --- | 360 |
| lncrna.玉米(Zea mays) | 8423 | --- | 1629 |
| lncrna.大豆(Glycine max) | 11430 | --- | 490 |
| lncrna.番茄(Solanum lycopersicum) | 7274 | --- | 1072 |
| lncrna.普通小麦(Triticum aestivum) | 11252 | --- | 1810 |
| lncrna.高粱(Sorghum bicolor) | 8654 | --- | 734 |
| promoter_strength.叶片组织(leaf) | 58179 | 6825 | 7154 |
| promoter_strength.原生质体(protoplast) | 61051 | 7162 | 7595 |
| terminator_strength.叶片组织(leaf) | 43294 | 5309 | 4806 |
| terminator_strength.原生质体(protoplast) | 43289 | 5309 | 4811 |
| gene_exp.大豆(Glycine max) | 47136 | 4803 | 4803 |
| gene_exp.水稻(Oryza sativa) | 31244 | 3702 | 3702 |
| gene_exp.番茄(Solanum lycopersicum) | 27321 | 3827 | 3827 |
| gene_exp.玉米(Zea mays) | 34493 | 4483 | 4483 |
| gene_exp.拟南芥(Arabidopsis thaliana) | 25731 | 3401 | 3402 |
| chromatin_access.籼稻MH63RS2(Oryza sativa MH63_RS2) | 5120000 | 14848 | 14848 |
| chromatin_access.谷子(Setaria italica) | 5120000 | 19968 | 19968 |
| chromatin_access.籼稻ZS97RS2(Oryza sativa ZS97_RS2) | 5120000 | 14848 | 14848 |
| chromatin_access.拟南芥(Arabidopsis thaliana) | 5120000 | 9984 | 9984 |
| chromatin_access.二穗短柄草(Brachypodium distachyon) | 5120000 | 14848 | 14848 |
| chromatin_access.高粱(Sorghum bicolor) | 5120000 | 29952 | 29952 |
| chromatin_access.玉米(Zea mays) | 6400000 | 79872 | 79872 |
| pro_seq.木薯(Manihot esculenta) | 16852 | 1229 | 812 |
需要特别说明的是,长链非编码RNA(LncRNA)任务的微调采用单轮训练整合所有数据集完成。由于各数据集规模较小,合并训练有助于提升学习效果。
# 示例用法
python
from datasets import load_dataset
task_name='terminator_strength.protoplast' # 上述表格中的任意任务名称
dataset = load_dataset("InstaDeepAI/plant-genomic-benchmark",task_name=task_name)
# 计算机饱和诱变(in silico saturation mutagenesis)
## 文件结构:ISM_Tables/Mesculenta_305_v6_PROseq_ISM_LOG2FC.txt.gz
基于Lozano等人2021年的研究(https://pubmed.ncbi.nlm.nih.gov/34499719/)获取的基因间增强子区域<br>
基因组版本:来自Phytozome的木薯参考基因组v6.1<br>
CHR:染色体(Chromosome)<br>
POS:物理位置(碱基对,bp)<br>
REF:参考等位基因<br>
ALT:替代等位基因<br>
LOG2FC:基因间增强子概率的对数倍数变化(log2(突变序列的增强子概率 / 原始序列的增强子概率))<br>
## 文件结构:ISM_Tables/Mesculenta_v6_GeneExpression_ISM_LOG2FC.txt.gz
基于Wilson等人2016年的研究(https://pubmed.ncbi.nlm.nih.gov/28116755/)的基因表达预测结果<br>
基因组版本:来自Ensembl 56的木薯参考基因组v6<br>
CHR:染色体(Chromosome)<br>
POS:物理位置(碱基对,bp)<br>
REF:参考等位基因<br>
ALT:替代等位基因<br>
GENE:基因ID<br>
STRAND:基因链<br>
TISSUE:组织类型(缩写详见Wilson等人论文图1)<br>
LOG2FC:基因表达对数倍数变化(log2(突变序列的基因表达水平 / 原始序列的基因表达水平))<br>
# 图2至图8的数据源
## 文件结构:Figures/Figure[FIGURE_NUMBER]_panel[PANEL_LETTER].txt
该文本文件包含用于绘制Mendoza-Revilla与Trop等人2024年研究中图2至图8的数据。文件命名格式如下:`Figure[FIGURE_NUMBER]_panel[PANEL_LETTER].txt`
- [FIGURE_NUMBER]:对应论文中的图号,例如若数据对应图3,则该部分文件名为`Figure3`
- [PANEL_LETTER]:对应图内特定子图的字母标识,图表通常包含多个以字母(如a、b、c)标注的子图,例如若数据对应图3的子图b,则该部分文件名为`panelb`
提供机构:
maas创建时间:
2025-08-13
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集包含AgroNT论文中的8个评估任务,涵盖单输出回归、多输出回归、二分类和多标签分类,旨在提供全面的植物基因组学基准。此外,它还包括木薯基因组的计算机饱和诱变分析数据,用于评估突变对基因表达和增强子元素的影响。
以上内容由遇见数据集搜集并总结生成


