nielsr/breast-cancer
收藏Hugging Face2023-12-14 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/nielsr/breast-cancer
下载链接
链接失效反馈官方服务:
资源简介:
---
dataset_info:
features:
- name: image
dtype: image
- name: label
dtype: image
splits:
- name: train
num_bytes: 42431652.0
num_examples: 130
download_size: 0
dataset_size: 42431652.0
---
# Dataset Card for "breast-cancer"
Dataset was taken from the MedSAM project and used in [this notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/SAM/Fine_tune_SAM_(segment_anything)_on_a_custom_dataset.ipynb) which fine-tunes Meta's SAM model on the dataset.
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
提供机构:
nielsr
原始信息汇总
数据集概述
数据集名称
- 名称: breast-cancer
数据集特征
- 特征1: image
- 数据类型: image
- 特征2: label
- 数据类型: image
数据集分割
- 分割类型: train
- 示例数量: 130
- 数据大小: 42431652.0字节
数据集大小
- 下载大小: 0字节
- 数据集总大小: 42431652.0字节
搜集汇总
数据集介绍
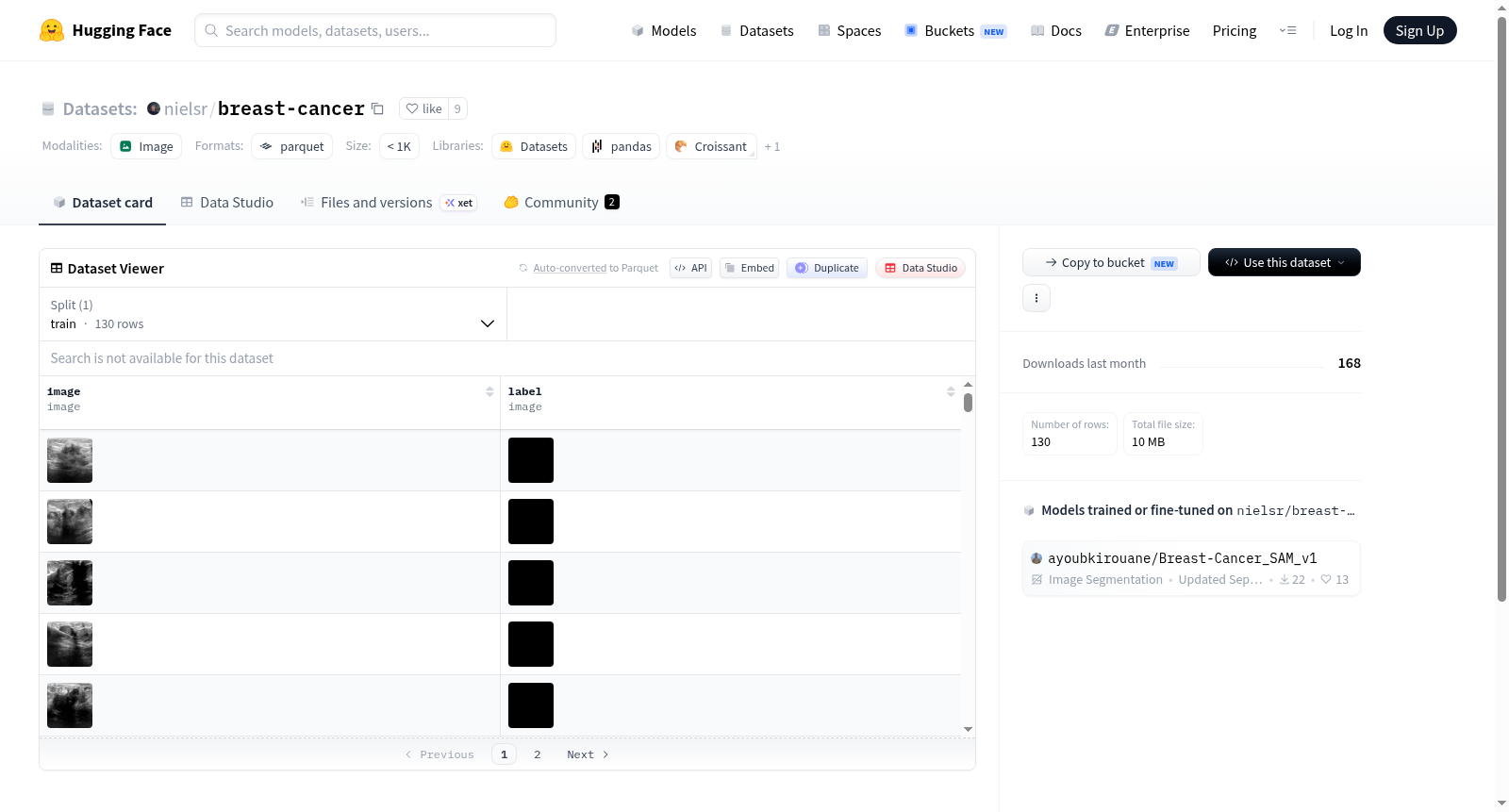
构建方式
该数据集源自MedSAM项目,旨在为乳腺超声图像提供语义分割标注。原始图像与对应的掩膜标签均以图像格式存储,共包含130个训练样本。数据集被划分为单一的训练集,其总大小约为42.4兆字节,确保了数据加载的高效性。构建过程中,图像与标签严格配对,以便于监督学习任务的开展。
特点
数据集的核心特点在于其专注于医学图像分割任务,特别是乳腺癌症区域的识别。所有样本均经过专业标注,提供像素级的分割掩膜,这为训练高精度的分割模型奠定了坚实基础。尽管样本数量相对有限,但数据质量较高,且尺寸统一,便于直接用于深度学习框架的预处理流水线。
使用方法
该数据集主要用于微调Meta的SAM(Segment Anything)模型,相关教程与代码实现已在GitHub仓库中公开。用户可通过HuggingFace的datasets库直接加载,利用其内置的image特征类型无缝集成至PyTorch或TensorFlow训练流程。典型应用包括加载图像与标签对,构建数据加载器,并基于SAM模型进行迁移学习,最终实现乳腺超声图像的自动分割。
背景与挑战
背景概述
乳腺癌作为全球女性最常见的恶性肿瘤之一,其早期诊断与精准治疗依赖于医学影像分析技术的持续突破。该数据集由Niels Rogge基于MedSAM项目整理,并于2023年发布,旨在支持医学图像分割模型的微调研究。核心研究问题聚焦于如何利用有限的标注数据(仅130张训练图像)高效适配Meta提出的SAM(Segment Anything Model)基础模型,以提升其在乳腺影像分割任务中的泛化能力。该数据集虽规模较小,却为探索预训练大模型在医学领域的迁移学习提供了关键基准,推动了SAM在医疗影像分析中的应用边界。
当前挑战
当前数据集面临多重挑战:其一,领域问题层面,乳腺影像中病灶形态多样、边界模糊且与正常组织对比度低,导致传统分割模型难以达到临床级精度,而SAM等通用模型在医学场景中常因缺乏领域特异性知识而性能受限。其二,构建过程中,该数据集仅包含130例训练样本,远低于深度学习模型对大规模标注数据的需求,且标签为图像级而非像素级掩膜,增加了分割任务的不确定性。此外,数据来源单一可能引入采样偏差,限制模型在跨设备、跨人群场景中的鲁棒性。这些挑战共同制约了模型在真实临床环境中的可部署性。
常用场景
经典使用场景
在医学影像分析领域,乳腺癌的精准分割是辅助诊断与治疗规划的关键环节。该数据集源自MedSAM项目,专为微调Meta提出的Segment Anything Model(SAM)而设计,其经典使用场景在于利用少量标注样本(仅130张训练图像)实现医学图像中乳腺病变区域的语义分割。通过将通用视觉大模型适配至特定医学任务,研究者能够探索小样本学习与迁移学习在医疗影像中的潜力,从而在不依赖大规模人工标注的前提下提升分割精度。
衍生相关工作
基于该数据集,NielsRogge等人发布了公开教程,系统展示了如何利用Transformers库微调SAM模型,催生了多项后续工作。研究者进一步探索了提示工程、多模态融合(如结合临床文本报告)以及跨数据集迁移策略,衍生出诸如MedSAM-Adapter、SAM-Med2D等改进架构。这些工作不仅拓展了基础模型在医学图像分割中的适用边界,还推动了高效微调技术(如LoRA、Adapter)在医疗领域的普及,形成了从算法验证到临床部署的完整研究链条。
数据集最近研究
最新研究方向
在医学影像分析领域,乳腺癌的早期诊断与精准分割始终是研究热点。该数据集源自MedSAM项目,专门用于微调Meta提出的SAM(Segment Anything Model)模型,代表了将通用视觉大模型迁移至特定医学任务的创新方向。当前前沿研究聚焦于如何利用少量标注样本(本数据集仅含130张训练图像)实现高精度肿瘤区域分割,这呼应了医疗场景中标注成本高昂的现实挑战。通过结合SAM的零样本能力与领域微调策略,研究者正探索在乳腺钼靶或超声图像上实现肿瘤边界自动化描绘,其成果有望提升临床诊断效率与一致性。该数据集的发布推动了基础模型在垂直医疗领域的落地,为构建可泛化的医学影像分析工具提供了关键验证平台。
以上内容由遇见数据集搜集并总结生成


