corporate-governance-reasoning
收藏官方服务:
资源简介:
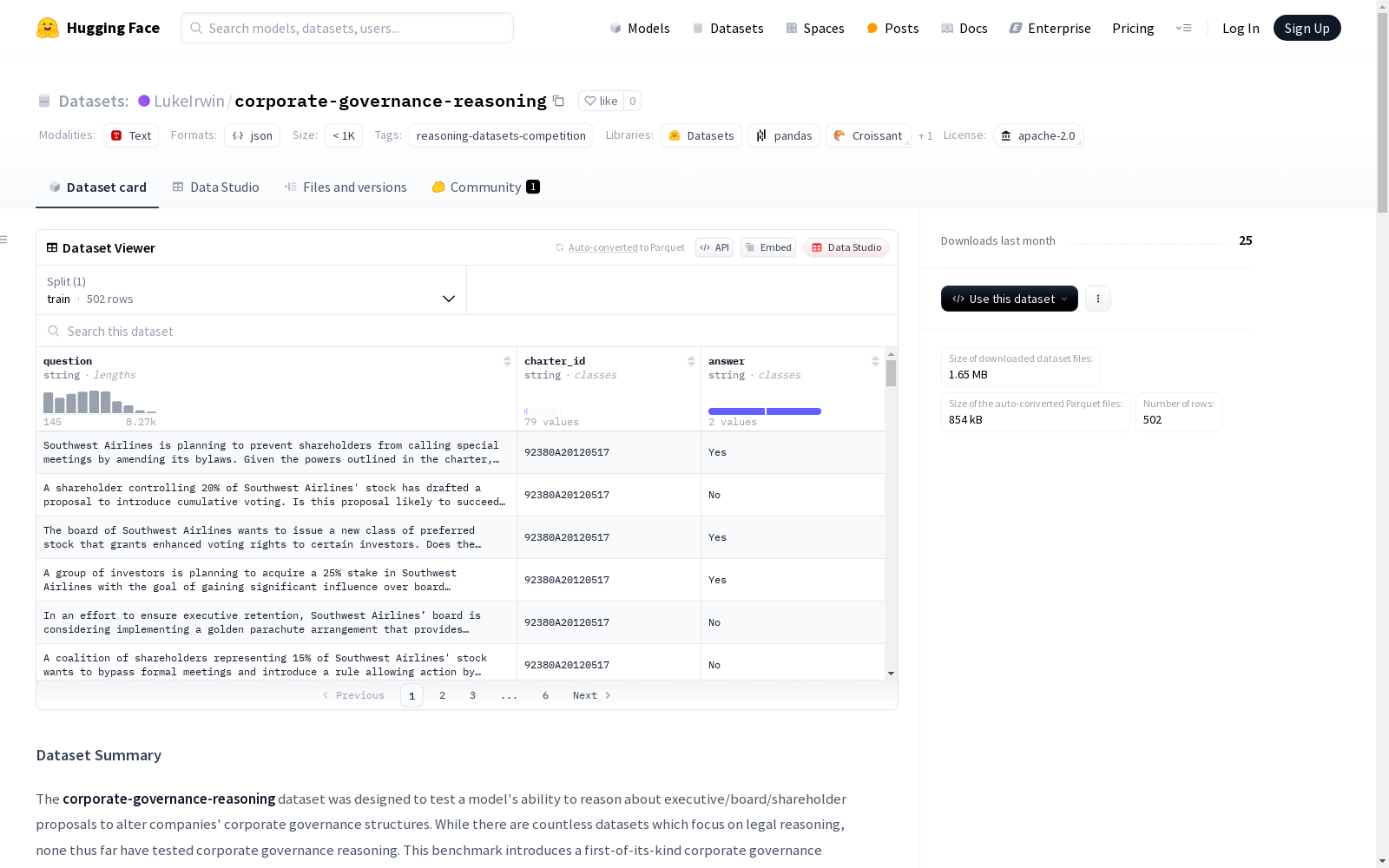
该数据集名为corporate-governance-reasoning,旨在测试语言模型对企业治理结构中的高管/董事会/股东提案进行推理的能力。数据集包含基于24个具体企业治理原则的提案,以及对应的公司章程和二元答案是或否。模型的任务是对比提案和公司章程,判断提案是否与章程一致。
创建时间:
2025-04-28
原始信息汇总
数据集概述:corporate-governance-reasoning
数据集摘要
- 目的:测试模型对公司治理结构变更提案的推理能力。
- 任务类型:二元分类任务(yes/no)。
- 结构:
- question:针对24项公司治理原则的政策变更提案。
- charter_id:对应公司治理章程的标识符。
- answer:二元目标答案(yes/no)。
数据来源与创建
- 基础数据:基于Gompers et al. (2003)的10,000份真实公司章程。
- 问题生成:
- 使用GPT-4o生成假设场景。
- 结合章程与通用法律(如DGCL)增加问题复杂度。
- 难度控制:通过矛盾信息、多章节引用和通用法律组件提升推理难度。
数据结构示例
python { "question": "股东提案示例文本...", "charter_id": "73309B20100908", "answer": "Yes" }
模型性能
| 模型 | 正确率 | 错误率 | 未回答率 |
|---|---|---|---|
| GPT-4o | 29.1% | 66.1% | 4.8% |
| Llama3.1-70B | 22.2% | 73.1% | 4.7% |
| DeepSeek-R1 | 58.6% | 25.1% | 16.3% |
| QwQ-32B | 55.4% | 22.2% | 22.4% |
高级推理模型
- ReAct模型:68.7%正确率(基于CoT和搜索工具)。
- CodeAct模型:70.1%正确率(章程代码化处理)。
使用方式
python from datasets import load_dataset dataset = load_dataset("LukeIrwin/corporate-governance-reasoning")
局限性
- 范围限制:仅涵盖24项公司治理原则(源自Gompers et al. (2003))。
- 扩展性:未包含区块链公司等新兴治理原则。
搜集汇总
数据集介绍
构建方式
该数据集的构建基于Gompers等人(2003)提供的10,000份真实公司章程,从中随机选取章程并深入分析,以生成符合24项公司治理原则的问题。通过GPT-4o生成假设性场景,并结合章程内容与通用法律条款(如特拉华州普通公司法),确保问题的复杂性与深度。每个问题均经过多次迭代,以增强其挑战性,涵盖矛盾的条款和复杂的法律逻辑,从而提升模型的推理能力。
特点
该数据集专注于公司治理领域的推理任务,通过二元分类形式评估模型对章程修正案的理解能力。其独特之处在于结合具体章程条款与通用法律,生成具有挑战性的问题,涵盖多重法律条款和矛盾信息。数据集的难度体现在领先模型的低准确率上,即使是表现最佳的模型也仅略高于随机猜测水平,突显其作为评估工具的高标准。
使用方法
使用该数据集时,可通过HuggingFace的`datasets`库直接加载,调用`load_dataset`函数即可获取结构化数据。每条数据包含问题描述、对应章程ID及二元答案,适用于训练或评估模型在公司治理场景下的推理能力。用户还可结合提供的评估框架,测试模型在复杂法律逻辑中的表现,或进一步扩展数据集以涵盖更多治理原则。
背景与挑战
背景概述
企业治理推理数据集(corporate-governance-reasoning)是专为评估语言模型在企业治理结构变更提案中的推理能力而设计的创新性基准。该数据集由研究团队基于Gompers等人(2003)提供的10,000份真实公司章程构建,聚焦24项核心治理原则,填补了法律推理领域中企业治理专项评估的空白。通过模拟董事会、高管及股东提出的政策变更场景,数据集以二元分类任务形式,要求模型结合公司章程判断提案的合规性。其创新性体现在首次系统性地将企业治理原则与法律条文理解相结合,为衡量AI在法律文本多层级推理能力提供了标准化测试平台。
当前挑战
该数据集面临双重挑战:在领域问题层面,企业治理决策需同时解析公司章程条款与通用公司法(如特拉华州普通公司法)的交互关系,模型必须处理法律文本中常见的模糊表述与矛盾条款;在构建过程中,研究人员通过引入对抗性设计增强难度,包括刻意构造信息冲突的提案场景、跨章程多章节引用,以及法律术语的复杂嵌套。现有测试表明,即使顶尖模型如DeepSeek-R1的正确率仅略高于随机基线,反映出法律推理中精确语义对齐与逻辑链条构建的严峻挑战。
常用场景
经典使用场景
在法学与商业管理交叉领域,corporate-governance-reasoning数据集为评估语言模型在公司治理结构推理能力方面设立了新标准。该数据集通过模拟董事会提案与公司章程条款的匹配性判断,构建了包含24项核心治理原则的二元分类任务。研究人员可借助该基准测试,系统考察模型在分析黄金降落伞条款、累积投票制等专业条款时的逻辑严密性,尤其擅长检验模型对矛盾信息的处理能力。
实际应用
在商业智能应用层面,该数据集支撑着自动化公司章程审查系统的开发。法律科技公司可基于此训练智能助手,快速评估股东提案的合规性。投资机构则利用其构建风险评估模型,预测企业治理结构变更对股权价值的影响。特别在并购尽职调查场景中,该系统能显著提升对目标公司治理条款的审查效率。
衍生相关工作
该数据集催生了多项创新性研究,包括DeepSeek团队开发的代码驱动推理框架。后续研究扩展出基于ReAct架构的动态推理模型,将准确率提升至68.7%。MIT团队进一步提出分层注意力机制,通过分离章程条款与地方法律的语义特征,使模型在矛盾信息场景下的判断准确率提高12%。这些工作共同推动了商业法律推理领域的方法论革新。
以上内容由遇见数据集搜集并总结生成


