PiSA-Engine
收藏arXiv2025-03-14 更新2025-03-18 收录
下载链接:
http://arxiv.org/abs/2503.10529v1
下载链接
链接失效反馈官方服务:
资源简介:
PiSA-Engine是由香港中文大学(深圳)和新加坡国立高性能计算中心开发的一种数据生成引擎。该引擎通过三个阶段的训练策略,即3D空间数据标注、2D空间数据精炼和迭代3D数据引导,利用3D和2D多模态大语言模型的优势,生成高质量的点语言数据集。这些数据集可用于评估下游任务,如3D对象字幕和生成分类,解决现有3D数据集数量有限、质量不佳的问题。
PiSA-Engine is a data generation engine developed by The Chinese University of Hong Kong, Shenzhen and the National High Performance Computing Center of Singapore. This engine adopts a three-stage training strategy, namely 3D spatial data annotation, 2D spatial data refinement and iterative 3D data guidance, to generate high-quality point-language datasets by leveraging the strengths of 3D and 2D multimodal large language models. These datasets can be used to evaluate downstream tasks such as 3D object captioning and generative classification, addressing the issues of limited quantity and substandard quality of existing 3D datasets.
提供机构:
香港中文大学(深圳)、新加坡国立高性能计算中心
创建时间:
2025-03-14
搜集汇总
数据集介绍
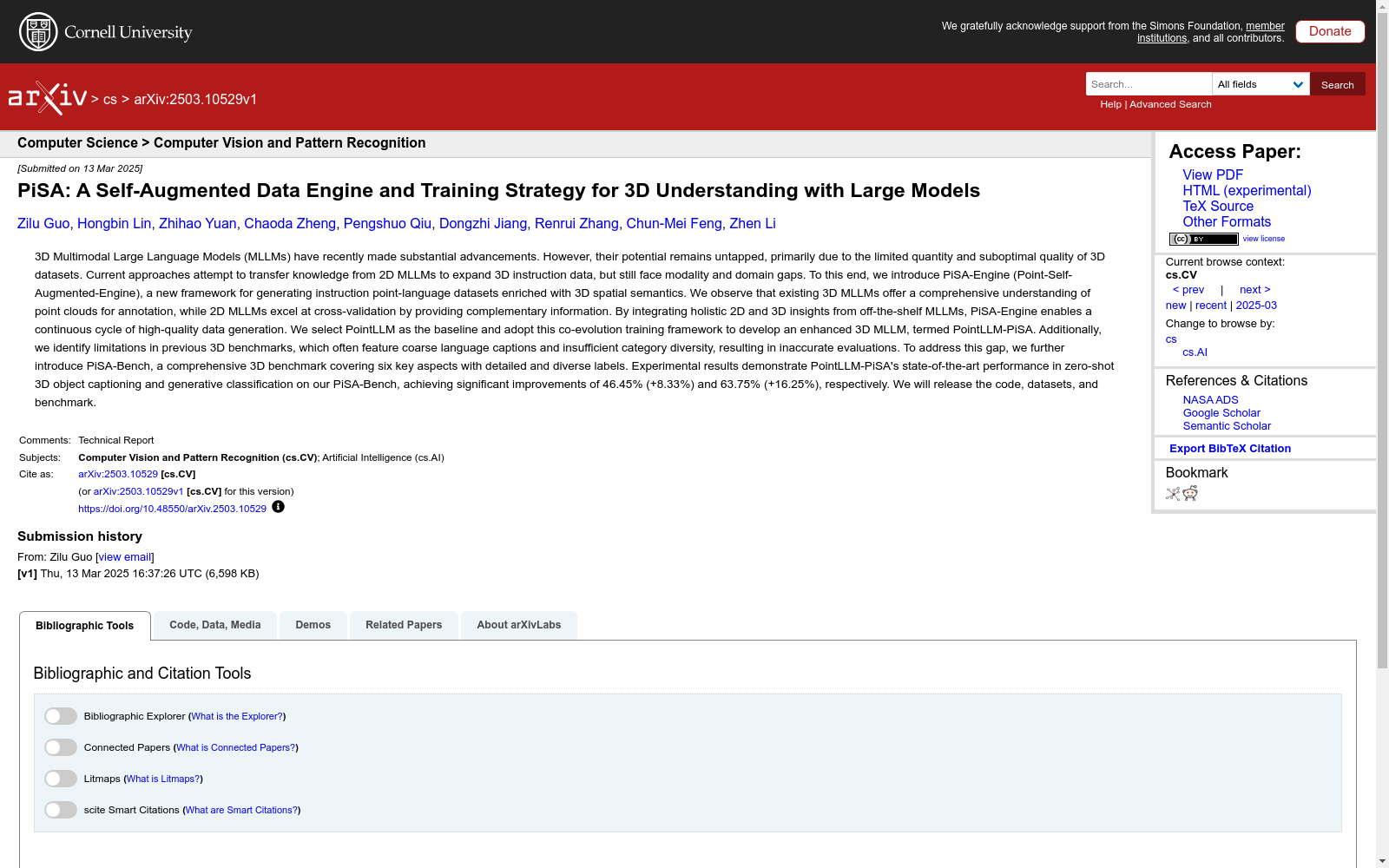
构建方式
PiSA-Engine 数据集的构建过程分为三个阶段:3D空间数据标注、2D空间数据精炼和迭代3D数据自举。首先,利用3D多模态大语言模型(MLLMs)从点云中提取深度、空间关系和几何属性等关键3D特征。随后,引入2D MLLMs作为验证模块,通过12个渲染视图对点云的视觉属性进行精炼,确保描述的准确性,同时保留原始的3D空间信息。最后,采用协同进化训练策略,利用前一阶段生成的模型为下一阶段生成训练数据,形成数据与模型的正反馈循环。
特点
PiSA-Engine 数据集的特点在于其结合了2D和3D多模态大语言模型的优势,生成了富含3D空间语义的指令数据。数据集通过3D MLLMs提取点云的深度和几何信息,并通过2D MLLMs进行跨模态验证,确保了数据的高质量和多样性。此外,PiSA-Engine 还引入了PiSA-Bench,一个涵盖描述、颜色、形状、数量、空间关系和用途六个方面的全面3D基准测试,能够更准确地评估下游任务。
使用方法
PiSA-Engine 数据集的使用方法主要围绕3D多模态大语言模型的训练和评估展开。首先,数据集可用于训练增强版的3D MLLMs,如PointLLM-PiSA,通过结合2D和3D语义知识提升模型性能。其次,PiSA-Bench 可用于评估3D对象描述和生成分类任务,涵盖多个关键方面,确保评估的全面性和准确性。此外,数据集还可用于传统3D下游任务,如零样本分类,通过模板化提示工程提升模型的表现。
背景与挑战
背景概述
PiSA-Engine是由Zilu Guo等研究人员于2025年提出的一种自增强数据引擎,旨在解决3D多模态大语言模型(MLLMs)在3D理解任务中的数据集限制问题。该数据集通过结合2D和3D MLLMs的优势,生成富含3D空间语义的指令数据集,显著提升了3D模型的性能。PiSA-Engine的核心研究问题在于如何通过自动化的数据生成和迭代训练策略,克服现有3D数据集在数量和质量上的不足。该数据集的提出为3D对象描述、生成分类等任务提供了新的基准,推动了3D多模态理解领域的发展。
当前挑战
PiSA-Engine面临的挑战主要包括两个方面。首先,3D多模态理解领域的数据集通常规模较小且质量参差不齐,导致模型训练效果受限。其次,数据生成过程中,如何有效结合2D和3D信息以避免模态间的差异和领域鸿沟,是一个关键难题。PiSA-Engine通过3D空间数据标注、2D空间数据精炼和迭代3D数据引导三个阶段,逐步解决了这些问题。然而,如何在保持3D空间信息完整性的同时,确保2D描述的准确性,仍然是一个复杂的挑战。此外,现有3D基准测试的粗糙性和细节不足,也使得数据集的构建和评估过程更加复杂。
常用场景
经典使用场景
PiSA-Engine 数据集在3D多模态大语言模型(MLLMs)领域中被广泛用于生成高质量的3D点云-语言指令数据集。通过结合2D和3D MLLMs的优势,PiSA-Engine能够生成包含丰富3D空间语义的指令数据,显著提升了3D理解任务的性能。该数据集在3D对象描述生成、零样本分类等任务中表现出色,尤其是在3D点云的跨模态理解和生成任务中,PiSA-Engine通过迭代训练策略,持续优化数据质量,推动了3D MLLMs的发展。
衍生相关工作
PiSA-Engine 数据集衍生了一系列经典工作,尤其是在3D多模态大语言模型领域。基于PiSA-Engine生成的指令数据,研究人员开发了增强版的3D MLLMs,如PointLLM-PiSA,该模型在零样本3D对象描述生成和生成式分类任务中取得了显著的性能提升。此外,PiSA-Engine还推动了3D基准测试的发展,如PiSA-Bench,该基准测试涵盖了6个关键方面的详细标注,能够更全面、准确地评估3D理解任务的性能。这些衍生工作进一步推动了3D多模态大语言模型的研究和应用。
数据集最近研究
最新研究方向
近年来,3D多模态大语言模型(MLLMs)在理解和生成3D点云的文本描述方面取得了显著进展,然而,3D数据集的稀缺和质量问题仍然限制了其潜力。PiSA-Engine作为一种自增强数据引擎,通过整合2D和3D MLLMs的优势,提出了一种新的框架,用于生成富含3D空间语义的指令数据集。该框架通过三个阶段——3D空间数据标注、2D空间数据精炼和迭代3D数据引导——实现了高质量数据的持续生成。PiSA-Engine不仅提升了数据质量,还通过增强的3D MLLM模型PointLLM-PiSA在零样本3D对象描述和生成分类任务中取得了显著的性能提升。此外,PiSA-Bench作为一种全面的3D基准测试,覆盖了六个关键方面,能够更准确、更全面地评估下游任务。这一研究为3D理解领域提供了新的数据生成和模型训练策略,推动了3D MLLMs在实际应用中的进一步发展。
相关研究论文
- 1PiSA: A Self-Augmented Data Engine and Training Strategy for 3D Understanding with Large Models香港中文大学(深圳)、新加坡国立高性能计算中心 · 2025年
以上内容由遇见数据集搜集并总结生成


