embedded_969
收藏Hugging Face2026-04-29 更新2026-04-30 收录
下载链接:
https://huggingface.co/datasets/cepere/embedded_969
下载链接
链接失效反馈官方服务:
资源简介:
大型俄语嵌入式数据集是由Claude Opus 4.5生成并经ChatGPT 5.2过滤的高质量数据集,专为训练嵌入式系统开发模型而设计。数据集覆盖了嵌入式系统开发的多个方面,包括代码调试、问题诊断、架构决策和外围设备操作等。数据以ChatML格式呈现,包含372,000个问答对,总计15亿令牌,数据量达969MB。数据集分为九个层次,按任务复杂度和类型组织,从基础代码错误修复到生产代码问题处理,再到复杂代码解释和不完整信息处理等高级任务。每个层次针对不同的开发场景和技能水平,旨在全面提升模型在嵌入式系统领域的理解和问题解决能力。数据集生成耗费了60,000美元的API成本,使用了30亿令牌的Claude和ChatGPT资源。
The large Russian embedded dataset is a high-quality dataset generated by Claude Opus 4.5 and filtered by ChatGPT 5.2, specifically designed for training embedded system development models. The dataset covers various aspects of embedded system development, including code debugging, issue diagnosis, architectural decisions, and peripheral device operations. The data is presented in ChatML format, containing 372,000 question-answer pairs, totaling 1.5 billion tokens, with a data volume of 969MB. The dataset is divided into nine levels, organized by task complexity and type, ranging from basic code error fixes to production code issue handling, and further to advanced tasks such as complex code interpretation and incomplete information processing. Each level targets different development scenarios and skill levels, aiming to comprehensively improve the models understanding and problem-solving capabilities in the field of embedded systems. The dataset generation consumed $60,000 in API costs and utilized 3 billion tokens of Claude and ChatGPT resources.
创建时间:
2026-04-26
原始信息汇总
大型俄语嵌入式数据集 — Claude Opus 4.5
📋 数据集概述
该数据集是一个高质量的俄语嵌入式系统训练数据集,由 Claude Opus 4.5 生成,并经 ChatGPT 5.2 过滤优化。数据集涵盖嵌入式系统开发的多个方面,包括代码调试、问题诊断、架构设计、外设操作等。
- 数据规模: 372k 问答对,15亿 token,969MB
- 生成成本: $60,000 API 费用(30亿 token,Claude/ChatGPT 各占50%)
📦 数据格式
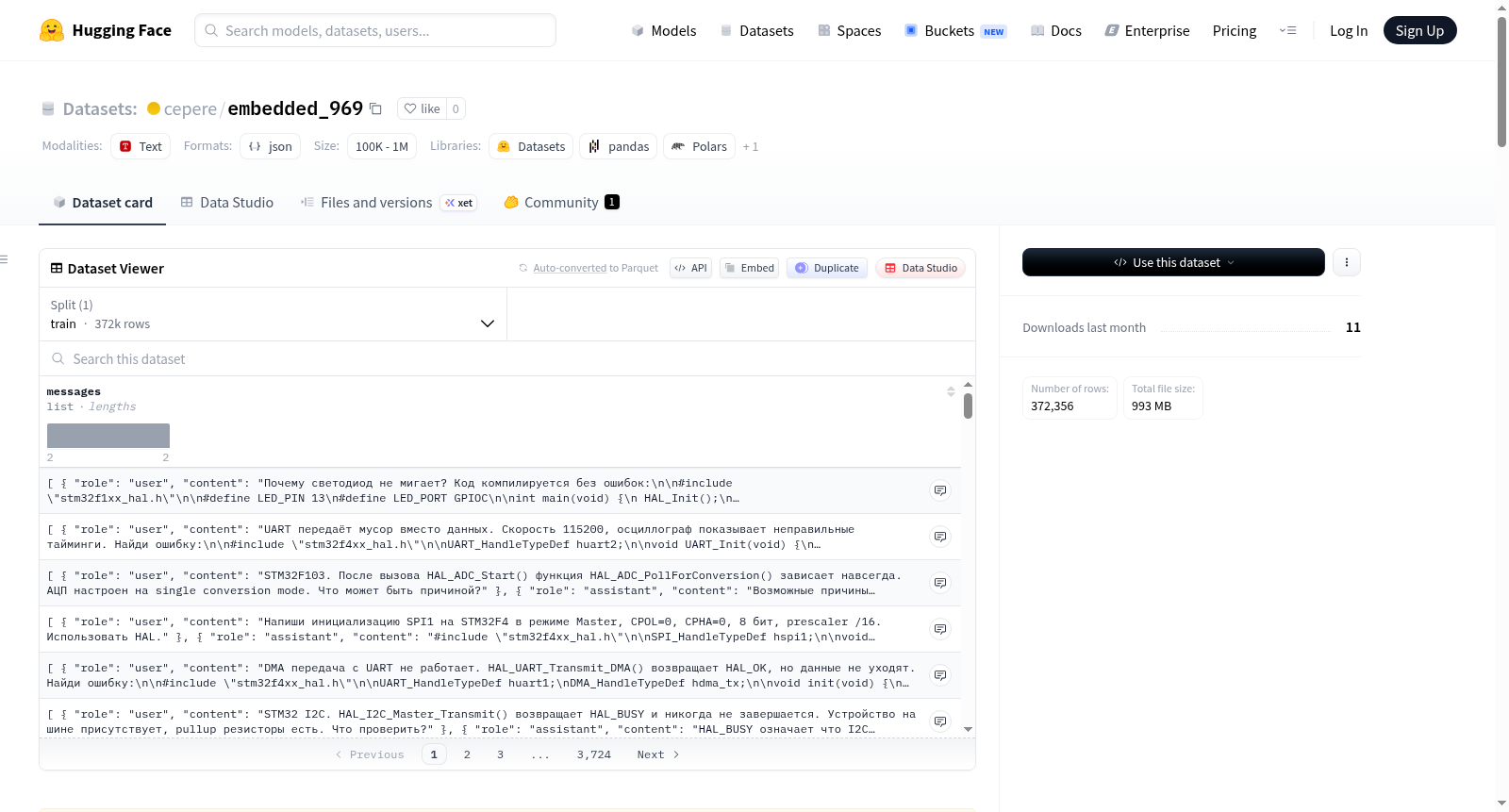
数据集采用 ChatML 格式存储,每个样本包含用户问题和助手回答的对话结构。示例中包含嵌入式代码调试场景(如STM32 LED不闪烁问题)及对应的诊断与修复建议。
🎯 数据集结构
数据集按难度层级和任务类型组织,共分为 9个主要层级 及若干附加层:
Layer 1 — 嵌入式开发问答
- 任务类型:
code_bug(代码缺陷)、symptom(症状分析)、code_gen(代码生成) - 包含可编译代码中的真实缺陷,回答附带验证标准和解释
Layer 2 — 单主题 QTA 示例
- 侧重推理与假设排序、问题诊断、最小化修复方案
- 重点覆盖:DMA、缓存、竞态条件、同步机制
- 基于规则对解决方案进行验证
Layer 3 — CoT 诊断任务
- 结构化推理流程:
constraints— 约束条件hypotheses— 假设elimination— 排除不可能选项selection— 选择解决方案verification— 验证
- 最终输出简洁答案
Layer 4 — 高级 STM32 代码缺陷分析
- 复杂可编译代码(HAL/LL/寄存器级)
- 查找所有运行时缺陷
- 按严重程度排序:
- 🔴 严重
- 🟠 危险
- 🟡 可疑
Layer 5 — 生产级代码任务
- 处理真实生产环境代码
- 任务类型:缺陷分析、代码审查、架构设计、并发处理、生命周期管理、性能优化、代码生成
Layer 6 — 复杂代码讲解
- 状态机与控制流分析
- 异步/回调模式
- 生命周期管理
- 架构设计决策
- 边界情况处理
- 目标: 训练代码阅读与理解能力(非代码审查)
Layer 7 — 不完整信息处理
- 处理不完整或模糊的嵌入式开发请求
- 策略包括:需求澄清、合理假设、等待关键信息、问题优先级排序
Layer 8 — 高风险任务
- 模型需识别风险及其原因
- 提供受控的工程回答
- 仅对真正危险的情况设置硬性限制
Layer 9 — 应对用户误解
- 处理用户争议或错误观点
- 非对抗性温和纠正
- 在用户假设框架内引导至正确解决方案
附加层
包含未公开的用于质量控制、垃圾过滤和回答微调的层。
📞 联系方式
- Telegram: @HiendFlac
搜集汇总
数据集介绍
构建方式
本数据集名为 embedded_969,由 Claude Opus 4.5 和 ChatGPT 5.2 联合生成,专为嵌入式系统开发领域设计。数据集构建过程中,通过大规模 API 调用,消耗了约 30 亿个 Token 和 6 万美元的计算资源,生成了 37.2 万组高质量的问答对,总文本量达 15 亿个 Token。所有数据均经过严格筛选与过滤,最终以 ChatML 格式存储,数据集大小约为 969 MB。构建时采用分层设计,涵盖从基础调试到生产级代码分析的九个核心层级,每个层级聚焦于不同的嵌入式开发技能,如错误定位、代码审查、架构决策及并发处理等,确保内容的系统性与专业性。
特点
该数据集的核心特点在于其精细的分层结构与高针对性的任务设计。从 Layer 1 的基础 bug 诊断到 Layer 9 的用户误解纠正,每一层都围绕嵌入式开发中的真实痛点展开,例如 Layer 4 专注于 STM32 代码的运行时错误分析,Layer 7 则训练模型处理不完整信息下的推理能力。数据集尤其强调质量控制,包含未公开的辅助层用于过滤低质内容与微调输出。此外,数据涵盖 DMA、缓存、竞态条件等高级主题,并提供从 hypotheses 到 verification 的结构化推理路径,适合用于训练具备深度逻辑与工程直觉的对话模型。
使用方法
使用方法上,该数据集以 ChatML 格式提供,可直接适配支持此格式的机器学习框架,如 Hugging Face Transformers 或 OpenAI 的微调接口。用户加载数据时,每条记录包含 role 为 user 和 assistant 的消息对,无需额外预处理即可用于监督微调。对于训练任务,建议按照层级顺序或按难度递进的方式组织训练流程,以逐步提升模型在嵌入式领域的诊断与生成能力。特别地,Layer 6 和 Layer 8 分别适用于增强代码阅读水平与风险控制意识,开发者可根据模型的实际表现灵活选择特定层级进行针对性训练或评测。
背景与挑战
背景概述
大语言模型在嵌入式系统开发领域的应用正逐步受到关注,然而高质量、专业化的俄语数据集仍属稀缺资源。由开发者@HiendFlac于近期构建的embedded_969数据集,依托Claude Opus 4.5和ChatGPT 5.2两款前沿模型,投入约6万美元的API消耗,生成了包含37万2千条问答对、总计15亿词元、体积达969兆字节的庞大数据资源。该数据集系统性地覆盖了嵌入式开发中的代码调试、故障诊断、架构设计及外设操作等核心议题,并通过九层精细的结构化设计,从基础问答至高级风险任务与用户错误纠正,为俄语大语言模型在嵌入式领域的微调与评估提供了高质量的训练基础与基准,显著推动了该领域的研究进展。
当前挑战
该数据集所面临的挑战主要体现在两个方面。其一,在领域问题层面,嵌入式系统开发涉及硬件与软件的紧密耦合,问题来源复杂多样,如代码运行时错误、竞态条件、缓存一致性、中断同步等,传统通用模型难以有效诊断与解决这些专业化、场景依赖性强的问题,构建能够应对此类复杂工程任务的数据集是核心挑战。其二,在构建过程中,数据生成高度依赖闭源商业模型的API,单次生成成本极高且受限于模型能力与输出质量,同时数据需经人工或多模型过滤以确保准确性;此外,数据集仅覆盖STM32等特定硬件平台与俄语语境,其领域覆盖广度与语言通用性有限,如何以可控成本扩展覆盖范围并保持数据质量是最主要的构建难点。
常用场景
经典使用场景
在嵌入式系统的研究与开发领域,高质量的数据集对于训练大型语言模型至关重要。embedded_969 数据集专为嵌入式系统设计,涵盖了从代码调试、问题诊断到架构决策与外围设备操作的广泛场景。其经典用法在于利用多达九层的复杂任务结构,包括代码漏洞检测、症状描述、代码生成、链式思维诊断、高级STM32代码分析、生产级代码审查、复杂代码解释、不完整信息处理以及风险任务应对。该数据集通过精心设计的ChatML格式,为模型提供了丰富的真实世界嵌入式开发案例,使其能够学习并掌握嵌入式环境下独特的编程范式与调试技巧。
解决学术问题
该数据集系统性地解决了嵌入式软件工程中多个长期存在的学术难题。首先,它填补了高质量俄语嵌入式领域训练数据的空白,推动了非英语环境下专用模型的研究。其次,通过多层结构设计,它攻克了模型在嵌入式代码中识别隐性漏洞、处理并发与同步问题、以及在资源受限环境下进行结构化推理的挑战。数据集中包含的‘风险任务’与‘错误观念纠正’层,使研究者能够探索模型如何安全地处理工程决策中的不确定性,以及对用户误判进行非对抗性引导。这些问题的解决极大地推动了大型语言模型在嵌入式系统这一高精度、高可靠性要求领域的适用性研究。
衍生相关工作
受 embedded_969 数据集启发,学术界与工业界涌现了一系列相关衍生工作。围绕该数据集的多层任务体系,研究者探索了基于链式思维的嵌入式诊断推理模型,提出了将结构化约束条件与假设排除机制相结合的代码修复框架。此外,针对数据集中的‘不完整信息’与‘风险任务’层,衍生出了关于不确定环境下工程决策模型的一系列研究,推动了模型在处理模糊需求与高风险操作时的可控性边界。在生产代码分析方面,该数据集的层级设计催生了针对并发bug、内存生命周期管理等细分领域的专项检测模型。这些工作共同构成了一个活跃的研究生态,持续拓展着大型语言模型在嵌入式系统工程中的能力边界。
以上内容由遇见数据集搜集并总结生成


