NEWSROOM
收藏arXiv2020-05-18 更新2024-07-25 收录
下载链接:
https://lil.nlp.cornell.edu/newsroom/
下载链接
链接失效反馈官方服务:
资源简介:
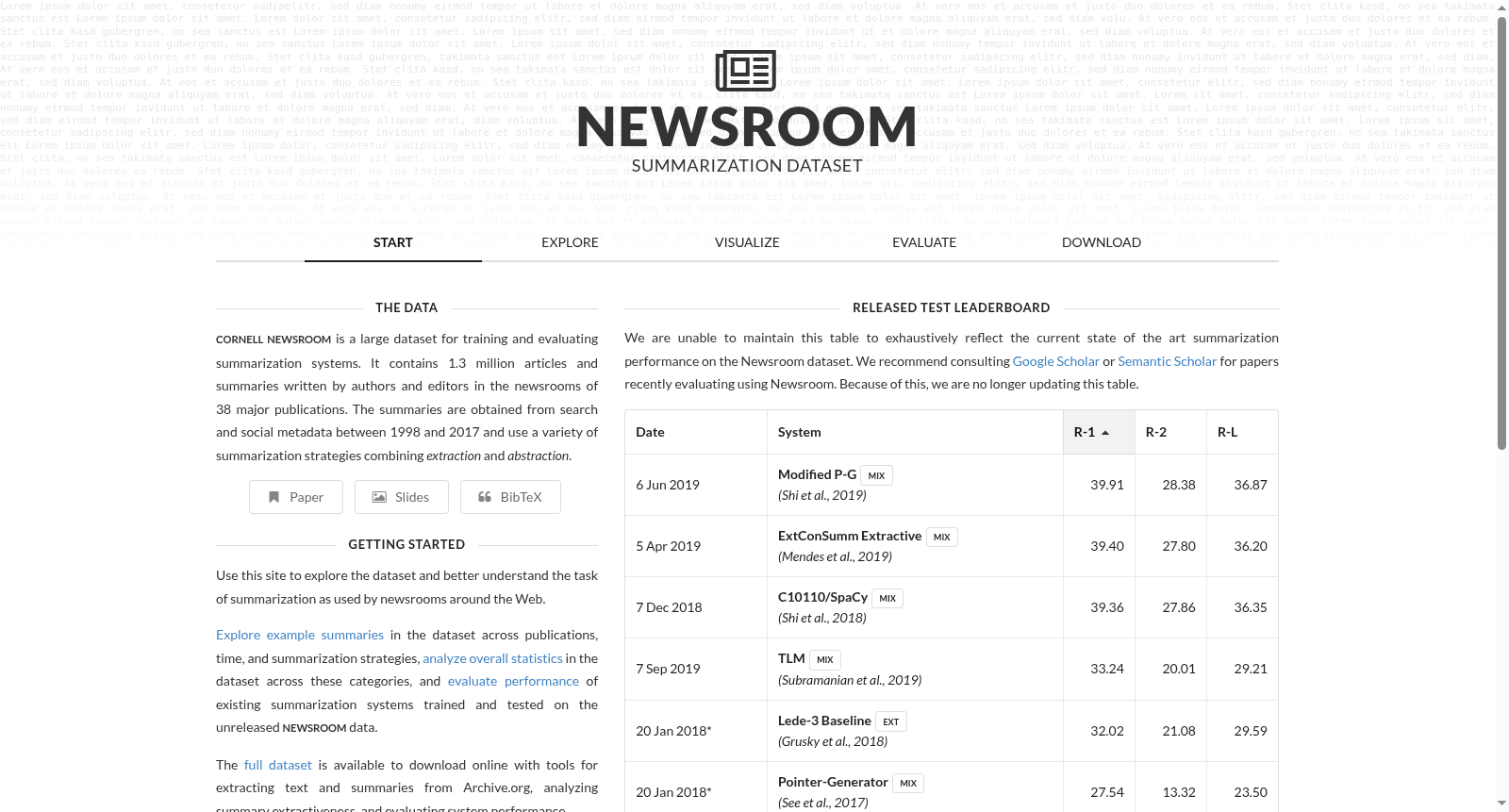
NEWSROOM是由康奈尔大学创建的一个包含130万条新闻文章和摘要的大型数据集,涵盖了38个主要新闻出版机构的内容。该数据集通过搜索和社交媒体元数据从1998年到2017年提取,展示了多样化的摘要风格,结合了抽象和提取策略。数据集的创建旨在通过提供大规模高质量数据,推动自动摘要技术的发展,解决长文本和多样化摘要策略带来的挑战。
NEWSROOM is a large-scale dataset comprising 1.3 million news articles and their corresponding summaries, developed by Cornell University. It covers content from 38 major news publishing institutions, and was extracted from 1998 to 2017 using search and social media metadata. The dataset features diverse summarization styles that integrate both abstractive and extractive strategies. Its creation aims to advance automatic summarization technologies by providing large-scale high-quality data, addressing the challenges posed by long-form texts and diverse summarization strategies.
提供机构:
康奈尔大学
创建时间:
2018-04-30
搜集汇总
数据集介绍
构建方式
在新闻摘要研究领域,高质量数据集的稀缺长期制约着自动摘要技术的发展。NEWSROOM数据集的构建采用了创新的网络爬取与元数据提取方法,其核心在于从互联网档案馆(Archive.org)系统性地收集了1998年至2017年间38家主流新闻出版机构的网页存档。研究团队通过结合Alexa顶级站点列表与历史流量数据,筛选出以原创英语新闻内容为主的出版商,并利用特定URL模式匹配与首页历史快照爬取两种技术,识别出超过百万篇新闻文章。随后,使用Readability算法精准提取文章正文,并从HTML页面的og:description、twitter:description等元数据字段中获取由新闻编辑撰写的高质量摘要。通过严格的去重、过滤与清洗流程,最终形成了包含1,321,995对文章-摘要的大规模语料库,并依据URL哈希划分为训练、开发与测试集。
特点
NEWSROOM数据集最显著的特点在于其摘要风格的极端多样性与真实世界代表性。该数据集囊括了新闻、体育、娱乐及金融等多个领域,时间跨度近二十年,充分捕捉了不同出版商、作者与时代背景下的摘要写作实践。通过提出的提取片段覆盖率、密度及压缩比等量化指标分析,数据集中的摘要呈现出从高度提取式到高度抽象式的连续分布,涵盖了直接借用原文短语、混合改写以及完全新颖表述等多种策略。这种多样性不仅超越了以往仅侧重单一风格的数据集,如偏向提取式的CNN/Daily Mail或纽约时报语料库,更真实地反映了实际应用中摘要任务的复杂性与挑战性,为模型泛化能力提供了 rigorous 的测试平台。
使用方法
NEWSROOM数据集为训练与评估自动摘要系统提供了 robust 的资源。研究者可将该数据集直接用于监督学习,训练如序列到序列、指针生成器等神经摘要模型,利用其大规模与多样性提升模型对不同摘要风格的适应能力。在评估层面,除了使用ROUGE等自动指标在标准划分的测试集上进行评测外,该数据集支持更具深度的分析:可依据提取片段覆盖率、密度或压缩比将数据划分为不同子集,从而细致评估模型在提取式、混合式或抽象式摘要上的性能差异。此外,数据集附带的基准人类评估协议(涵盖信息性、相关性、流畅性与连贯性四个维度)为超越n-gram匹配、进行语义层面的质量评估提供了标准化框架,助力全面衡量摘要系统的实际效用。
背景与挑战
背景概述
在自然语言生成领域,自动文本摘要技术的发展长期受限于高质量训练数据的稀缺性。为应对这一挑战,康奈尔大学的研究团队于2018年推出了NEWSROOM数据集,该数据集汇集了1998年至2017年间来自38家主流新闻机构的130万篇新闻文章及其人工撰写的摘要。这些摘要由新闻编辑室的作者和编辑创作,最初用于搜索引擎优化和社交媒体元数据,其核心研究目标在于捕捉真实场景下多样化的摘要生成策略——包括提取式、抽象式以及混合式方法。NEWSROOM以其规模之大和风格之广,显著推动了摘要生成模型从单一模式向多策略融合的演进,成为评估模型泛化能力的重要基准。
当前挑战
NEWSROOM数据集所应对的领域挑战在于解决自动文本摘要中源文本长度差异与摘要策略多样性之间的复杂映射关系。具体而言,模型需要同时处理高压缩比下的信息凝练任务,以及在不同提取率(从完全提取到完全抽象)之间灵活切换的语言生成能力。在构建过程中,研究团队面临两大挑战:一是从异构的网页元数据中精准提取文章主体与对应摘要,需克服HTML标签噪声与非标准化元数据字段的干扰;二是确保数据集的时序跨度与来源多样性,需通过大规模网络爬取与去重算法,从互联网档案馆中筛选出跨越二十年、涵盖多领域的高质量摘要对,同时避免自动化生成摘要的混入。
常用场景
经典使用场景
在自然语言处理领域,自动文本摘要技术旨在从冗长文档中提炼核心信息,生成简洁而准确的摘要。NEWSROOM数据集凭借其130万篇新闻文章与人工撰写的摘要对,为研究社区提供了大规模、高质量的基准资源。该数据集最经典的使用场景在于训练和评估混合式摘要生成模型,这些模型需要同时处理抽取式与生成式策略,模拟人类编辑在新闻写作中灵活运用原文片段与创新表达的能力。通过分析不同出版机构的摘要风格,研究者能够深入探索摘要的多样性,从而推动模型在真实世界应用中的适应性与鲁棒性。
衍生相关工作
NEWSROOM数据集的发布催生了一系列重要的后续研究工作,尤其在神经摘要生成模型的演进中发挥了关键作用。基于该数据集,研究者们开发了如指针生成网络等混合架构,这些模型能够动态选择从原文复制词汇或生成新词,显著提升了摘要的连贯性与信息密度。此外,该数据集也被广泛用于评估抽象式摘要系统的性能,推动了如BERTSUM等预训练模型在摘要任务上的适配与优化。这些衍生工作不仅丰富了摘要生成的技术路线,也为多文档摘要、跨语言摘要等拓展方向提供了宝贵的实验基础。
数据集最近研究
最新研究方向
在自然语言生成领域,NEWSROOM数据集凭借其大规模、高质量且风格多样的人类撰写摘要,已成为推动自动摘要技术发展的关键资源。该数据集涵盖了1998年至2017年间38家主流新闻机构的文章与摘要,其摘要策略融合了抽取式与生成式方法,展现出丰富的语言变化与压缩比分布。当前研究前沿聚焦于利用该数据集的多样性来训练混合策略模型,如指针生成网络,以提升模型在跨领域摘要任务中的泛化能力。同时,学者们正探索基于覆盖度、密度和压缩比等量化指标,深入分析摘要风格的差异,旨在开发更适应实际应用场景的摘要系统。这些研究不仅促进了摘要评估协议的发展,还为理解人类摘要行为提供了实证基础,对新闻自动化、信息检索等热点应用具有深远影响。
相关研究论文
- 1Newsroom: A Dataset of 1.3 Million Summaries with Diverse Extractive Strategies康奈尔大学 · 2020年
以上内容由遇见数据集搜集并总结生成


