lukaemon/bbh
收藏Hugging Face2023-02-02 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/lukaemon/bbh
下载链接
链接失效反馈官方服务:
资源简介:
---
dataset_info:
- config_name: boolean_expressions
features:
- name: input
dtype: string
- name: target
dtype: string
splits:
- name: test
num_bytes: 11790
num_examples: 250
download_size: 17172
dataset_size: 11790
- config_name: causal_judgement
features:
- name: input
dtype: string
- name: target
dtype: string
splits:
- name: test
num_bytes: 198021
num_examples: 187
download_size: 202943
dataset_size: 198021
- config_name: date_understanding
features:
- name: input
dtype: string
- name: target
dtype: string
splits:
- name: test
num_bytes: 54666
num_examples: 250
download_size: 61760
dataset_size: 54666
- config_name: disambiguation_qa
features:
- name: input
dtype: string
- name: target
dtype: string
splits:
- name: test
num_bytes: 78620
num_examples: 250
download_size: 85255
dataset_size: 78620
- config_name: dyck_languages
features:
- name: input
dtype: string
- name: target
dtype: string
splits:
- name: test
num_bytes: 38432
num_examples: 250
download_size: 43814
dataset_size: 38432
- config_name: formal_fallacies
features:
- name: input
dtype: string
- name: target
dtype: string
splits:
- name: test
num_bytes: 138224
num_examples: 250
download_size: 145562
dataset_size: 138224
- config_name: geometric_shapes
features:
- name: input
dtype: string
- name: target
dtype: string
splits:
- name: test
num_bytes: 68560
num_examples: 250
download_size: 77242
dataset_size: 68560
- config_name: hyperbaton
features:
- name: input
dtype: string
- name: target
dtype: string
splits:
- name: test
num_bytes: 38574
num_examples: 250
download_size: 44706
dataset_size: 38574
- config_name: logical_deduction_five_objects
features:
- name: input
dtype: string
- name: target
dtype: string
splits:
- name: test
num_bytes: 148595
num_examples: 250
download_size: 155477
dataset_size: 148595
- config_name: logical_deduction_seven_objects
features:
- name: input
dtype: string
- name: target
dtype: string
splits:
- name: test
num_bytes: 191022
num_examples: 250
download_size: 198404
dataset_size: 191022
- config_name: logical_deduction_three_objects
features:
- name: input
dtype: string
- name: target
dtype: string
splits:
- name: test
num_bytes: 105831
num_examples: 250
download_size: 112213
dataset_size: 105831
- config_name: movie_recommendation
features:
- name: input
dtype: string
- name: target
dtype: string
splits:
- name: test
num_bytes: 50985
num_examples: 250
download_size: 57684
dataset_size: 50985
- config_name: multistep_arithmetic_two
features:
- name: input
dtype: string
- name: target
dtype: string
splits:
- name: test
num_bytes: 12943
num_examples: 250
download_size: 18325
dataset_size: 12943
- config_name: navigate
features:
- name: input
dtype: string
- name: target
dtype: string
splits:
- name: test
num_bytes: 49031
num_examples: 250
download_size: 55163
dataset_size: 49031
- config_name: object_counting
features:
- name: input
dtype: string
- name: target
dtype: string
splits:
- name: test
num_bytes: 30508
num_examples: 250
download_size: 35890
dataset_size: 30508
- config_name: penguins_in_a_table
features:
- name: input
dtype: string
- name: target
dtype: string
splits:
- name: test
num_bytes: 70062
num_examples: 146
download_size: 74516
dataset_size: 70062
- config_name: reasoning_about_colored_objects
features:
- name: input
dtype: string
- name: target
dtype: string
splits:
- name: test
num_bytes: 89579
num_examples: 250
download_size: 98694
dataset_size: 89579
- config_name: ruin_names
features:
- name: input
dtype: string
- name: target
dtype: string
splits:
- name: test
num_bytes: 46537
num_examples: 250
download_size: 53178
dataset_size: 46537
- config_name: salient_translation_error_detection
features:
- name: input
dtype: string
- name: target
dtype: string
splits:
- name: test
num_bytes: 277110
num_examples: 250
download_size: 286443
dataset_size: 277110
- config_name: snarks
features:
- name: input
dtype: string
- name: target
dtype: string
splits:
- name: test
num_bytes: 38223
num_examples: 178
download_size: 42646
dataset_size: 38223
- config_name: sports_understanding
features:
- name: input
dtype: string
- name: target
dtype: string
splits:
- name: test
num_bytes: 22723
num_examples: 250
download_size: 28617
dataset_size: 22723
- config_name: temporal_sequences
features:
- name: input
dtype: string
- name: target
dtype: string
splits:
- name: test
num_bytes: 139546
num_examples: 250
download_size: 148176
dataset_size: 139546
- config_name: tracking_shuffled_objects_five_objects
features:
- name: input
dtype: string
- name: target
dtype: string
splits:
- name: test
num_bytes: 162590
num_examples: 250
download_size: 169722
dataset_size: 162590
- config_name: tracking_shuffled_objects_seven_objects
features:
- name: input
dtype: string
- name: target
dtype: string
splits:
- name: test
num_bytes: 207274
num_examples: 250
download_size: 214906
dataset_size: 207274
- config_name: tracking_shuffled_objects_three_objects
features:
- name: input
dtype: string
- name: target
dtype: string
splits:
- name: test
num_bytes: 122104
num_examples: 250
download_size: 128736
dataset_size: 122104
- config_name: web_of_lies
features:
- name: input
dtype: string
- name: target
dtype: string
splits:
- name: test
num_bytes: 47582
num_examples: 250
download_size: 52964
dataset_size: 47582
- config_name: word_sorting
features:
- name: input
dtype: string
- name: target
dtype: string
splits:
- name: test
num_bytes: 60918
num_examples: 250
download_size: 66300
dataset_size: 60918
---
# BIG-bench Hard dataset
homepage: https://github.com/suzgunmirac/BIG-Bench-Hard
```
@article{suzgun2022challenging,
title={Challenging BIG-Bench Tasks and Whether Chain-of-Thought Can Solve Them},
author={Suzgun, Mirac and Scales, Nathan and Sch{\"a}rli, Nathanael and Gehrmann, Sebastian and Tay, Yi and Chung, Hyung Won and Chowdhery, Aakanksha and Le, Quoc V and Chi, Ed H and Zhou, Denny and and Wei, Jason},
journal={arXiv preprint arXiv:2210.09261},
year={2022}
}
```
数据集信息:
- 配置名称:布尔表达式(boolean_expressions)
特征项:
- 名称:输入(input),数据类型(dtype):字符串(string)
- 名称:目标(target),数据类型(dtype):字符串(string)
数据划分:
- 名称:测试集(test),字节数:11790,样本数:250
下载大小:17172,数据集总大小:11790
- 配置名称:因果判断(causal_judgement)
特征项:
- 名称:输入(input),数据类型(dtype):字符串(string)
- 名称:目标(target),数据类型(dtype):字符串(string)
数据划分:
- 名称:测试集(test),字节数:198021,样本数:187
下载大小:202943,数据集总大小:198021
- 配置名称:日期理解(date_understanding)
特征项:
- 名称:输入(input),数据类型(dtype):字符串(string)
- 名称:目标(target),数据类型(dtype):字符串(string)
数据划分:
- 名称:测试集(test),字节数:54666,样本数:250
下载大小:61760,数据集总大小:54666
- 配置名称:消歧问答(disambiguation_qa)
特征项:
- 名称:输入(input),数据类型(dtype):字符串(string)
- 名称:目标(target),数据类型(dtype):字符串(string)
数据划分:
- 名称:测试集(test),字节数:78620,样本数:250
下载大小:85255,数据集总大小:78620
- 配置名称:Dyck语言(dyck_languages)
特征项:
- 名称:输入(input),数据类型(dtype):字符串(string)
- 名称:目标(target),数据类型(dtype):字符串(string)
数据划分:
- 名称:测试集(test),字节数:38432,样本数:250
下载大小:43814,数据集总大小:38432
- 配置名称:形式谬误(formal_fallacies)
特征项:
- 名称:输入(input),数据类型(dtype):字符串(string)
- 名称:目标(target),数据类型(dtype):字符串(string)
数据划分:
- 名称:测试集(test),字节数:138224,样本数:250
下载大小:145562,数据集总大小:138224
- 配置名称:几何形状(geometric_shapes)
特征项:
- 名称:输入(input),数据类型(dtype):字符串(string)
- 名称:目标(target),数据类型(dtype):字符串(string)
数据划分:
- 名称:测试集(test),字节数:68560,样本数:250
下载大小:77242,数据集总大小:68560
- 配置名称:语序倒装(hyperbaton)
特征项:
- 名称:输入(input),数据类型(dtype):字符串(string)
- 名称:目标(target),数据类型(dtype):字符串(string)
数据划分:
- 名称:测试集(test),字节数:38574,样本数:250
下载大小:44706,数据集总大小:38574
- 配置名称:五对象逻辑演绎(logical_deduction_five_objects)
特征项:
- 名称:输入(input),数据类型(dtype):字符串(string)
- 名称:目标(target),数据类型(dtype):字符串(string)
数据划分:
- 名称:测试集(test),字节数:148595,样本数:250
下载大小:155477,数据集总大小:148595
- 配置名称:七对象逻辑演绎(logical_deduction_seven_objects)
特征项:
- 名称:输入(input),数据类型(dtype):字符串(string)
- 名称:目标(target),数据类型(dtype):字符串(string)
数据划分:
- 名称:测试集(test),字节数:191022,样本数:250
下载大小:198404,数据集总大小:191022
- 配置名称:三对象逻辑演绎(logical_deduction_three_objects)
特征项:
- 名称:输入(input),数据类型(dtype):字符串(string)
- 名称:目标(target),数据类型(dtype):字符串(string)
数据划分:
- 名称:测试集(test),字节数:105831,样本数:250
下载大小:112213,数据集总大小:105831
- 配置名称:电影推荐(movie_recommendation)
特征项:
- 名称:输入(input),数据类型(dtype):字符串(string)
- 名称:目标(target),数据类型(dtype):字符串(string)
数据划分:
- 名称:测试集(test),字节数:50985,样本数:250
下载大小:57684,数据集总大小:50985
- 配置名称:两步多步算术(multistep_arithmetic_two)
特征项:
- 名称:输入(input),数据类型(dtype):字符串(string)
- 名称:目标(target),数据类型(dtype):字符串(string)
数据划分:
- 名称:测试集(test),字节数:12943,样本数:250
下载大小:18325,数据集总大小:12943
- 配置名称:路径导航(navigate)
特征项:
- 名称:输入(input),数据类型(dtype):字符串(string)
- 名称:目标(target),数据类型(dtype):字符串(string)
数据划分:
- 名称:测试集(test),字节数:49031,样本数:250
下载大小:55163,数据集总大小:49031
- 配置名称:物体计数(object_counting)
特征项:
- 名称:输入(input),数据类型(dtype):字符串(string)
- 名称:目标(target),数据类型(dtype):字符串(string)
数据划分:
- 名称:测试集(test),字节数:30508,样本数:250
下载大小:35890,数据集总大小:30508
- 配置名称:餐桌企鹅(penguins_in_a_table)
特征项:
- 名称:输入(input),数据类型(dtype):字符串(string)
- 名称:目标(target),数据类型(dtype):字符串(string)
数据划分:
- 名称:测试集(test),字节数:70062,样本数:146
下载大小:74516,数据集总大小:70062
- 配置名称:彩色物体推理(reasoning_about_colored_objects)
特征项:
- 名称:输入(input),数据类型(dtype):字符串(string)
- 名称:目标(target),数据类型(dtype):字符串(string)
数据划分:
- 名称:测试集(test),字节数:89579,样本数:250
下载大小:98694,数据集总大小:89579
- 配置名称:毁誉命名(ruin_names)
特征项:
- 名称:输入(input),数据类型(dtype):字符串(string)
- 名称:目标(target),数据类型(dtype):字符串(string)
数据划分:
- 名称:测试集(test),字节数:46537,样本数:250
下载大小:53178,数据集总大小:46537
- 配置名称:显著翻译错误检测(salient_translation_error_detection)
特征项:
- 名称:输入(input),数据类型(dtype):字符串(string)
- 名称:目标(target),数据类型(dtype):字符串(string)
数据划分:
- 名称:测试集(test),字节数:277110,样本数:250
下载大小:286443,数据集总大小:277110
- 配置名称:反讽(snarks)
特征项:
- 名称:输入(input),数据类型(dtype):字符串(string)
- 名称:目标(target),数据类型(dtype):字符串(string)
数据划分:
- 名称:测试集(test),字节数:38223,样本数:178
下载大小:42646,数据集总大小:38223
- 配置名称:体育理解(sports_understanding)
特征项:
- 名称:输入(input),数据类型(dtype):字符串(string)
- 名称:目标(target),数据类型(dtype):字符串(string)
数据划分:
- 名称:测试集(test),字节数:22723,样本数:250
下载大小:28617,数据集总大小:22723
- 配置名称:时间序列推理(temporal_sequences)
特征项:
- 名称:输入(input),数据类型(dtype):字符串(string)
- 名称:目标(target),数据类型(dtype):字符串(string)
数据划分:
- 名称:测试集(test),字节数:139546,样本数:250
下载大小:148176,数据集总大小:139546
- 配置名称:五物体乱序追踪(tracking_shuffled_objects_five_objects)
特征项:
- 名称:输入(input),数据类型(dtype):字符串(string)
- 名称:目标(target),数据类型(dtype):字符串(string)
数据划分:
- 名称:测试集(test),字节数:162590,样本数:250
下载大小:169722,数据集总大小:162590
- 配置名称:七物体乱序追踪(tracking_shuffled_objects_seven_objects)
特征项:
- 名称:输入(input),数据类型(dtype):字符串(string)
- 名称:目标(target),数据类型(dtype):字符串(string)
数据划分:
- 名称:测试集(test),字节数:207274,样本数:250
下载大小:214906,数据集总大小:207274
- 配置名称:三物体乱序追踪(tracking_shuffled_objects_three_objects)
特征项:
- 名称:输入(input),数据类型(dtype):字符串(string)
- 名称:目标(target),数据类型(dtype):字符串(string)
数据划分:
- 名称:测试集(test),字节数:122104,样本数:250
下载大小:128736,数据集总大小:122104
- 配置名称:谎言网络(web_of_lies)
特征项:
- 名称:输入(input),数据类型(dtype):字符串(string)
- 名称:目标(target),数据类型(dtype):字符串(string)
数据划分:
- 名称:测试集(test),字节数:47582,样本数:250
下载大小:52964,数据集总大小:47582
- 配置名称:词语排序(word_sorting)
特征项:
- 名称:输入(input),数据类型(dtype):字符串(string)
- 名称:目标(target),数据类型(dtype):字符串(string)
数据划分:
- 名称:测试集(test),字节数:60918,样本数:250
下载大小:66300,数据集总大小:60918
# BIG-bench Hard 数据集
项目主页:https://github.com/suzgunmirac/BIG-Bench-Hard
@article{suzgun2022challenging,
标题={极具挑战性的BIG-Bench任务及思维链能否解决此类任务},
作者={Suzgun, Mirac 与 Scales, Nathan 与 Schärli, Nathanael 与 Gehrmann, Sebastian 与 Tay, Yi 与 Chung, Hyung Won 与 Chowdhery, Aakanksha 与 Le, Quoc V 与 Chi, Ed H 与 Zhou, Denny 与 与 Wei, Jason},
期刊={arXiv预印本 arXiv:2210.09261},
年份={2022}
}
提供机构:
lukaemon
原始信息汇总
BIG-Bench Hard 数据集概述
数据集列表
1. boolean_expressions
- 特征:
- input: 字符串
- target: 字符串
- 测试集:
- 字节数: 11790
- 示例数: 250
2. causal_judgement
- 特征:
- input: 字符串
- target: 字符串
- 测试集:
- 字节数: 198021
- 示例数: 187
3. date_understanding
- 特征:
- input: 字符串
- target: 字符串
- 测试集:
- 字节数: 54666
- 示例数: 250
4. disambiguation_qa
- 特征:
- input: 字符串
- target: 字符串
- 测试集:
- 字节数: 78620
- 示例数: 250
5. dyck_languages
- 特征:
- input: 字符串
- target: 字符串
- 测试集:
- 字节数: 38432
- 示例数: 250
6. formal_fallacies
- 特征:
- input: 字符串
- target: 字符串
- 测试集:
- 字节数: 138224
- 示例数: 250
7. geometric_shapes
- 特征:
- input: 字符串
- target: 字符串
- 测试集:
- 字节数: 68560
- 示例数: 250
8. hyperbaton
- 特征:
- input: 字符串
- target: 字符串
- 测试集:
- 字节数: 38574
- 示例数: 250
9. logical_deduction_five_objects
- 特征:
- input: 字符串
- target: 字符串
- 测试集:
- 字节数: 148595
- 示例数: 250
10. logical_deduction_seven_objects
- 特征:
- input: 字符串
- target: 字符串
- 测试集:
- 字节数: 191022
- 示例数: 250
11. logical_deduction_three_objects
- 特征:
- input: 字符串
- target: 字符串
- 测试集:
- 字节数: 105831
- 示例数: 250
12. movie_recommendation
- 特征:
- input: 字符串
- target: 字符串
- 测试集:
- 字节数: 50985
- 示例数: 250
13. multistep_arithmetic_two
- 特征:
- input: 字符串
- target: 字符串
- 测试集:
- 字节数: 12943
- 示例数: 250
14. navigate
- 特征:
- input: 字符串
- target: 字符串
- 测试集:
- 字节数: 49031
- 示例数: 250
15. object_counting
- 特征:
- input: 字符串
- target: 字符串
- 测试集:
- 字节数: 30508
- 示例数: 250
16. penguins_in_a_table
- 特征:
- input: 字符串
- target: 字符串
- 测试集:
- 字节数: 70062
- 示例数: 146
17. reasoning_about_colored_objects
- 特征:
- input: 字符串
- target: 字符串
- 测试集:
- 字节数: 89579
- 示例数: 250
18. ruin_names
- 特征:
- input: 字符串
- target: 字符串
- 测试集:
- 字节数: 46537
- 示例数: 250
19. salient_translation_error_detection
- 特征:
- input: 字符串
- target: 字符串
- 测试集:
- 字节数: 277110
- 示例数: 250
20. snarks
- 特征:
- input: 字符串
- target: 字符串
- 测试集:
- 字节数: 38223
- 示例数: 178
21. sports_understanding
- 特征:
- input: 字符串
- target: 字符串
- 测试集:
- 字节数: 22723
- 示例数: 250
22. temporal_sequences
- 特征:
- input: 字符串
- target: 字符串
- 测试集:
- 字节数: 139546
- 示例数: 250
23. tracking_shuffled_objects_five_objects
- 特征:
- input: 字符串
- target: 字符串
- 测试集:
- 字节数: 162590
- 示例数: 250
24. tracking_shuffled_objects_seven_objects
- 特征:
- input: 字符串
- target: 字符串
- 测试集:
- 字节数: 207274
- 示例数: 250
25. tracking_shuffled_objects_three_objects
- 特征:
- input: 字符串
- target: 字符串
- 测试集:
- 字节数: 122104
- 示例数: 250
26. web_of_lies
- 特征:
- input: 字符串
- target: 字符串
- 测试集:
- 字节数: 47582
- 示例数: 250
27. word_sorting
- 特征:
- input: 字符串
- target: 字符串
- 测试集:
- 字节数: 60918
- 示例数: 250
搜集汇总
数据集介绍
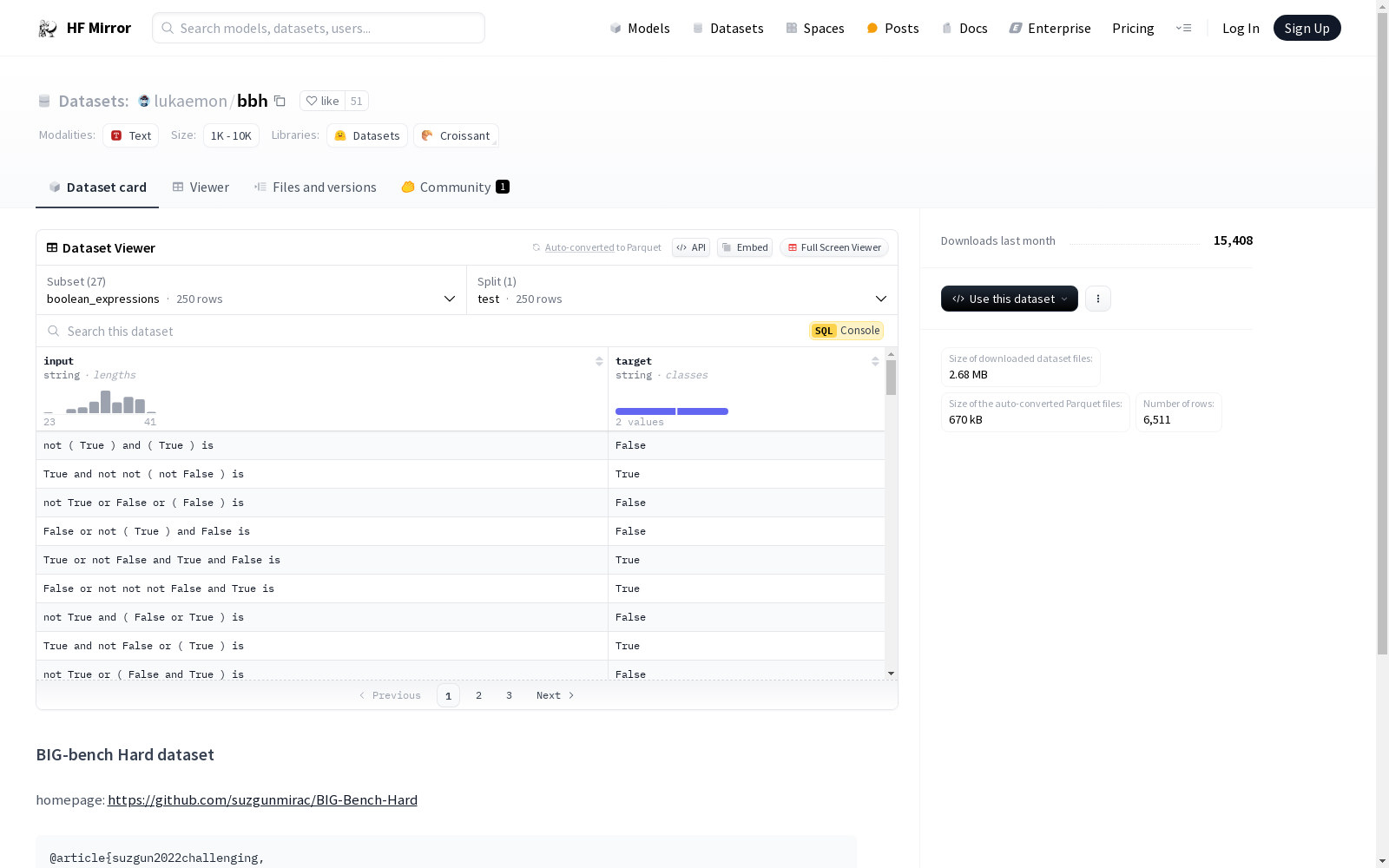
构建方式
该数据集名为lukaemon/bbh,源自BIG-bench Hard项目,旨在通过一系列复杂的任务挑战模型的推理能力。数据集的构建方式涵盖了多个领域,包括逻辑推理、数学运算、自然语言理解等,每个任务均包含输入和目标两个字段,分别以字符串形式呈现。数据集通过精心设计的测试集来评估模型的表现,确保每个任务的难度和复杂性符合预期。
使用方法
使用该数据集时,用户可以通过HuggingFace的datasets库进行加载,选择特定的配置(如boolean_expressions、causal_judgement等)进行模型评估。每个任务的输入和目标字段均为字符串格式,用户可以根据需要进行预处理或直接用于模型训练和测试。数据集的多样性使其适用于多种自然语言处理和推理任务的研究,尤其适合评估模型在复杂场景下的表现。
背景与挑战
背景概述
lukaemon/bbh数据集,全称为BIG-bench Hard dataset,由Suzgun等人于2022年创建,旨在为自然语言处理领域提供一系列具有挑战性的任务。该数据集的核心研究问题是如何评估和提升语言模型在复杂任务中的表现,特别是通过引入链式思维(Chain-of-Thought)方法来解决这些难题。主要研究人员包括Mirac Suzgun、Nathan Scales等,他们通过精心设计的任务集,推动了语言模型在推理、逻辑和多步骤问题解决能力上的发展,对自然语言处理领域的研究具有重要影响。
当前挑战
该数据集面临的挑战主要集中在任务的复杂性和多样性上。首先,任务涉及逻辑推理、时间序列理解、几何形状识别等多个领域,要求模型具备跨领域的综合能力。其次,构建过程中,研究人员需要确保每个任务的难度适中,既能有效评估模型的性能,又不至于过于简单或复杂。此外,数据集的多样性也带来了标注和验证的挑战,确保每个任务的输入和目标标签的准确性和一致性是构建过程中的关键难题。
常用场景
经典使用场景
在自然语言处理领域,lukaemon/bbh数据集主要用于评估和提升模型在复杂推理任务中的表现。该数据集涵盖了多种推理任务,如逻辑推理、因果判断、日期理解等,为研究者提供了一个全面的测试平台。通过这些任务,模型能够展示其在处理复杂语言结构和多步骤推理中的能力,从而为开发更智能的AI系统奠定基础。
解决学术问题
该数据集解决了自然语言处理领域中复杂推理任务的评估难题。传统的基准测试往往难以覆盖复杂的推理场景,而lukaemon/bbh数据集通过引入多样化的推理任务,填补了这一空白。这不仅有助于推动模型在复杂任务上的性能提升,还为研究者提供了一个标准化的评估工具,促进了学术界对推理能力的深入研究。
实际应用
在实际应用中,lukaemon/bbh数据集的推理任务可以广泛应用于智能助手、自动化客服、法律文本分析等领域。例如,在法律文本分析中,模型需要理解复杂的法律条文并进行逻辑推理,以辅助法律从业者进行案件分析。此外,在智能助手中,模型通过处理多步骤的指令和问题,能够为用户提供更加精准和高效的服务。
数据集最近研究
最新研究方向
在自然语言处理领域,lukaemon/bbh数据集因其多样化的任务配置而备受关注。该数据集涵盖了从逻辑推理到时间序列分析等多个复杂任务,为研究者提供了丰富的实验场景。近期,研究者们聚焦于如何利用该数据集提升模型的推理能力和多步任务处理能力。特别是,结合链式思维(Chain-of-Thought)方法,研究者们试图解决数据集中包含的复杂推理任务,如逻辑演绎和因果判断,这不仅推动了模型在复杂任务上的表现,也为人工智能在实际应用中的决策能力提供了新的视角。
以上内容由遇见数据集搜集并总结生成


