SpineBench
收藏arXiv2025-10-14 更新2025-11-05 收录
下载链接:
https://hf-mirror.com/datasets/Silversorrow/SpineBench
下载链接
链接失效反馈官方服务:
资源简介:
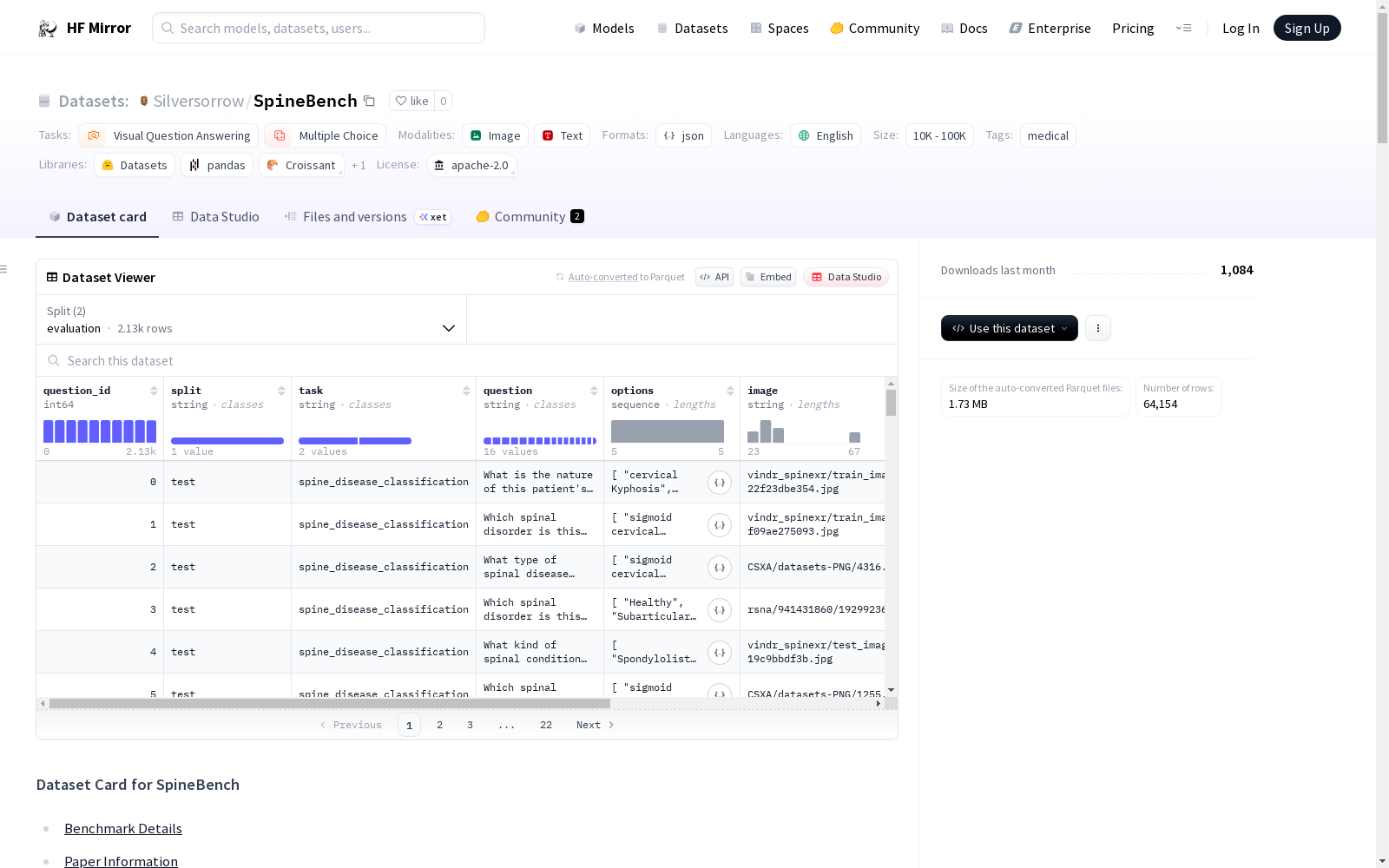
SpineBench是一个专为脊柱领域设计的视觉问答(VQA)数据集,包含40,263张脊柱图像,涵盖了11种脊柱疾病,并引入了两个关键的临床任务:脊柱疾病诊断和脊柱病变定位。该数据集通过整合和标准化来自开源脊柱疾病数据集的图像标签对构建而成,旨在为评估多模态大型语言模型(MLLMs)在脊柱领域的性能提供一个全面的基准。
SpineBench is a visual question answering (VQA) dataset specifically designed for the spinal domain. It contains 40,263 spinal images covering 11 types of spinal diseases, and introduces two key clinical tasks: spinal disease diagnosis and spinal lesion localization. This dataset is constructed by integrating and standardizing image-label pairs from open-source spinal disease datasets, aiming to provide a comprehensive benchmark for evaluating the performance of multimodal large language models (MLLMs) in the spinal field.
提供机构:
北京邮电大学
创建时间:
2025-10-14
搜集汇总
数据集介绍
构建方式
在脊柱医学影像分析领域,数据集的构建需兼顾多样性与临床相关性。SpineBench通过整合四个公开脊柱疾病数据集(BUU Spine Dataset、CSXA、RSNA和VinDr-SpineXR),涵盖X射线与MRI两种模态,构建了包含40,263张脊柱图像的标准化集合。采用严格的预处理流程,统一图像格式为2D RGB,并依据国际医学主题词表与临床专家指导,对原始疾病标签进行系统化修订与合并,确保11类脊柱疾病的标注一致性与临床有效性。在此基础上,进一步标注24,615张图像的病灶定位信息,覆盖五个腰椎节段,为后续视觉问答任务奠定结构化基础。
特点
脊柱病理分析任务对模型的细粒度感知能力提出极高要求。SpineBench的核心特征体现在其多维度挑战性设计:首先,数据集包含64,878个视觉问答对,覆盖疾病诊断与病灶定位两大临床核心任务,其中病灶定位支持多标签答案,真实反映脊柱病变可能涉及多个节段的临床实际;其次,通过基于视觉相似性的硬负例采样策略,为每个问题构建包含相似影像特征但不同病种的干扰选项,模拟临床中易混淆的鉴别诊断场景;此外,数据集涵盖颈椎、胸椎、腰椎和骶椎等多个脊柱区域,且疾病分布呈现长尾特性,有效考验模型对罕见病例的识别能力。
使用方法
面向多模态大语言模型在脊柱医学领域的评估需求,SpineBench提供了系统化的测评框架。使用时需遵循标准化的多选择题格式:对于脊柱疾病诊断任务,模型需从五个选项(含一个正确答案、三个视觉相似干扰项及“健康”选项)中识别具体病种;病灶定位任务则要求模型从五个固定腰椎节段中选出所有病变位置。评估过程采用零样本提示策略,鼓励模型在输出最终答案前展示推理过程。性能度量方面,疾病诊断采用准确率指标,病灶定位则综合考察精确率、召回率及完全匹配准确率,确保全面反映模型在定位任务中的完整性与精确性。数据集还提供经专家验证的2,128样本评估子集,支持高效且可靠的模型能力评估。
背景与挑战
背景概述
随着多模态大语言模型在医疗领域的深度融合,针对特定医学子领域的精细化评估需求日益凸显。2025年由北京邮电大学与加州大学圣塔芭芭拉分校联合团队发布的SpineBench基准,聚焦脊柱病理分析这一专业领域,通过整合BUU-LSPINE、VinDr-SpineXR等四大开源数据集,构建了包含64,878个视觉问答对的大规模评估体系。该数据集覆盖11类脊柱疾病与5个腰椎节段,创新性地将临床诊断流程解构为疾病分类与病灶定位双重任务,为脊柱医学领域的多模态模型能力评估建立了标准化范式。
当前挑战
在脊柱病理分析领域,模型需克服视觉相似疾病的精准鉴别难题,如椎体滑脱与椎间隙狭窄在影像学表现上的高度重叠。数据集构建过程中面临三大挑战:其一是多源数据标准化难题,需统一来自不同机构的异构标注体系;其二是硬负例采样策略的设计,需通过视觉特征相似度计算模拟真实诊断困境;其三是多标签标注的复杂性,病灶定位任务需同时处理单影像多节段病变的临床场景。这些挑战共同推动了脊柱医学影像分析向精细化、标准化方向发展。
常用场景
经典使用场景
在脊柱病理学分析领域,SpineBench作为首个专为多模态大语言模型设计的视觉问答基准,其经典应用场景聚焦于评估模型对脊柱影像的细粒度语义理解能力。该数据集通过构建涵盖11种脊柱疾病、5个腰椎节段的64878个视觉问答对,系统检验模型在疾病诊断与病灶定位任务中的表现,为脊柱医学影像分析提供了标准化的评估框架。
衍生相关工作
基于SpineBench构建的评估体系,衍生出多个脊柱医学AI研究的重要方向。在模型架构方面,催生了针对脊柱影像特点的专用网络设计;在算法优化领域,推动了基于视觉相似性的困难样本挖掘技术发展;在临床应用层面,则激发了多中心脊柱疾病智能诊断系统的联合研究,为脊柱医学影像分析建立了完整的技术生态。
数据集最近研究
最新研究方向
随着多模态大语言模型在医学领域的深度融合,脊柱病理分析作为依赖精细视觉语义理解的专业方向,正面临评估体系缺失的挑战。SpineBench通过构建涵盖11类脊柱疾病、64,878个视觉问答对的大规模基准,聚焦疾病诊断与病灶定位两大核心任务,其创新性在于引入基于视觉相似性的负样本采样策略,模拟临床中形态相似疾病的鉴别困境。当前前沿研究揭示,通用及医疗专用模型在此基准上表现接近随机猜测,凸显出现有模型对脊柱影像细粒度语义理解的严重不足,尤其在多标签病灶定位任务中,模型虽能识别部分病变区域,却难以完整捕捉多节段共现的病理特征。这一瓶颈推动了面向脊柱解剖结构与病理机制的特化视觉-语言联合建模研究,为下一代医疗多模态模型的领域适应性优化提供了关键方向。
相关研究论文
- 1通过北京邮电大学 · 2025年
以上内容由遇见数据集搜集并总结生成


