colossal-oscar-1.0_urls
收藏Hugging Face2025-05-15 更新2025-05-16 收录
下载链接:
https://huggingface.co/datasets/nhagar/colossal-oscar-1.0_urls
下载链接
链接失效反馈官方服务:
资源简介:
colossal-oscar-1.0_urls数据集提供了从oscar-corpus/colossal-oscar-1.0数据集中下载的源数据中提取的URLs和顶级域名。该数据集允许研究人员和实践者在不处理数TB原始文本的情况下,分析大型语言模型(LLM)训练数据集的内容。
创建时间:
2025-05-13
原始信息汇总
colossal-oscar-1.0_urls 数据集概述
数据集基本信息
- 许可证: cc0-1.0
- 数据集名称: colossal-oscar-1.0_urls
- 关联数据集: oscar-corpus/colossal-oscar-1.0
- 数据集集合: LLM URLs NeurIPS Collection
数据集详情
数据集描述
- 创建方式: 通过下载源数据,提取URL和顶级域名,并仅保留这些记录标识符。
- 创建目的: 使研究人员和从业者能够在不处理大量原始文本的情况下探索训练数据集的内容。
- 创建工具: GitHub Pipeline
- 创建者: Nick Hagar 和 Jack Bandy
- 许可证: 与源数据集相同
数据来源
数据集用途
直接用途
- 探索大规模LLM训练数据集的内容
- 识别最常用的网站
- 对URL进行分类以了解数据集在域或主题层面的组成
- 比较不同数据集中的URL
- 研究特定网站的包含/排除模式
非适用范围
- 不用于复制或替代源数据
- 不用于大规模爬取所列URL
数据集结构
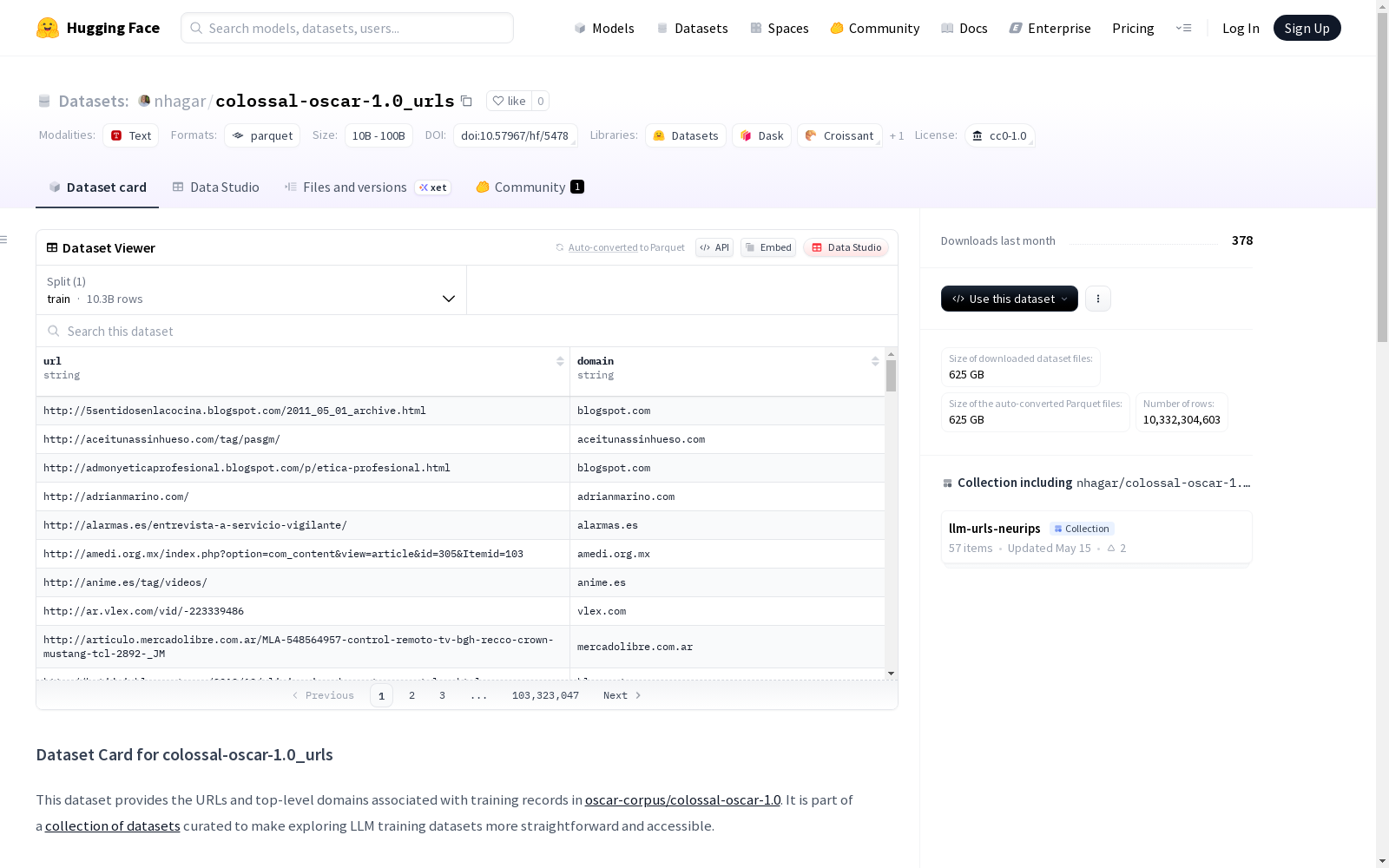
- 包含字段:
url: 与每条记录关联的原始URLdomain: 使用tldextract提取的每个URL的顶级域名
引用信息
- BibTeX: [More Information Needed]
- APA: [More Information Needed]
搜集汇总
数据集介绍
构建方式
在构建colossal-oscar-1.0_urls数据集的过程中,研究团队通过下载原始数据源并运用自动化流程提取其中的URL信息与顶级域名,同时仅保留记录标识符以优化存储结构。这一方法基于GitHub公开的管道工具实现,有效剥离了原始文本的庞大体量,为后续分析提供了轻量化的数据基础。
使用方法
研究人员可通过该数据集对语言模型训练数据的网络来源进行多维度分析,例如统计高频域名分布、探究特定领域的内容构成比例,或跨数据集比较URL收录模式。使用时需注意该数据集仅提供元数据参考,不可直接用于大规模网络爬取,原始文本仍需回溯至oscar-corpus/colossal-oscar-1.0主体数据集获取。
背景与挑战
背景概述
在自然语言处理领域,大规模语料库的构建对大型语言模型的训练至关重要。colossal-oscar-1.0_urls数据集由研究人员Nick Hagar与Jack Bandy共同创建,作为OSCAR多语言语料库体系的衍生产物,其核心价值在于通过提取原始文本中的URL与顶级域名信息,为研究者提供轻量化的数据探索接口。该数据集通过结构化处理海量网络文本的元数据,显著降低了分析数十亿级训练样本的门槛,为研究语言模型的训练数据分布、内容溯源及伦理审查建立了重要基础设施。
当前挑战
该数据集致力于解决网络文本语料溯源分析中的核心难题:如何在保留关键元数据的前提下实现数据轻量化。构建过程中面临原始数据规模达TB级的存储压力,需开发高效的URL提取与域名解析流水线。领域层面需应对多语言网站域名体系的复杂性,以及动态网页内容与静态文本记录的映射关系。此外,保持与源数据集许可协议的一致性,并防范第三方通过数据集进行大规模网络爬取,均是构建过程中需要严格把控的技术与伦理挑战。
常用场景
经典使用场景
在大规模语言模型训练数据日益重要的背景下,colossal-oscar-1.0_urls数据集为研究者提供了高效分析语料来源的途径。通过提取原始语料中的URL与顶级域名信息,该数据集支持对训练数据组成结构的宏观探索,例如识别高频网站分布特征或进行跨数据集的来源对比分析,显著降低了处理海量文本数据的计算门槛。
解决学术问题
该数据集主要解决了语言模型训练数据溯源领域的核心难题。通过结构化呈现网络语料来源,研究者能够系统评估训练数据的领域平衡性、文化偏向性及内容质量,为理解模型表现偏差提供数据支撑。这种元数据分析方法对促进语言模型训练的透明度和可解释性具有重要学术价值。
实际应用
在人工智能伦理治理实践中,该数据集可作为评估训练数据合规性的重要工具。监管机构通过分析域名分布特征,能够追溯训练数据中可能存在的版权争议内容或敏感信息来源。企业研发团队亦可借此优化数据清洗流程,建立符合地域法规的语料筛选机制。
数据集最近研究
最新研究方向
在大规模语言模型训练数据溯源领域,colossal-oscar-1.0_urls数据集通过提取原始语料中的URL与顶级域名信息,为研究者提供了探索网络文本构成的新维度。当前研究聚焦于通过域名分布分析揭示训练数据的来源特征,结合数字伦理视角探讨数据采集的合规性边界。随着全球对人工智能训练数据透明性要求的提升,该数据集成为评估多语言内容覆盖率、检测潜在偏见来源的重要工具,推动构建可追溯、可解释的预训练数据治理框架。
以上内容由遇见数据集搜集并总结生成


