Lada Dataset
收藏github2021-12-26 更新2024-05-31 收录
下载链接:
https://github.com/ihamdi/Lada-Detectron
下载链接
链接失效反馈官方服务:
资源简介:
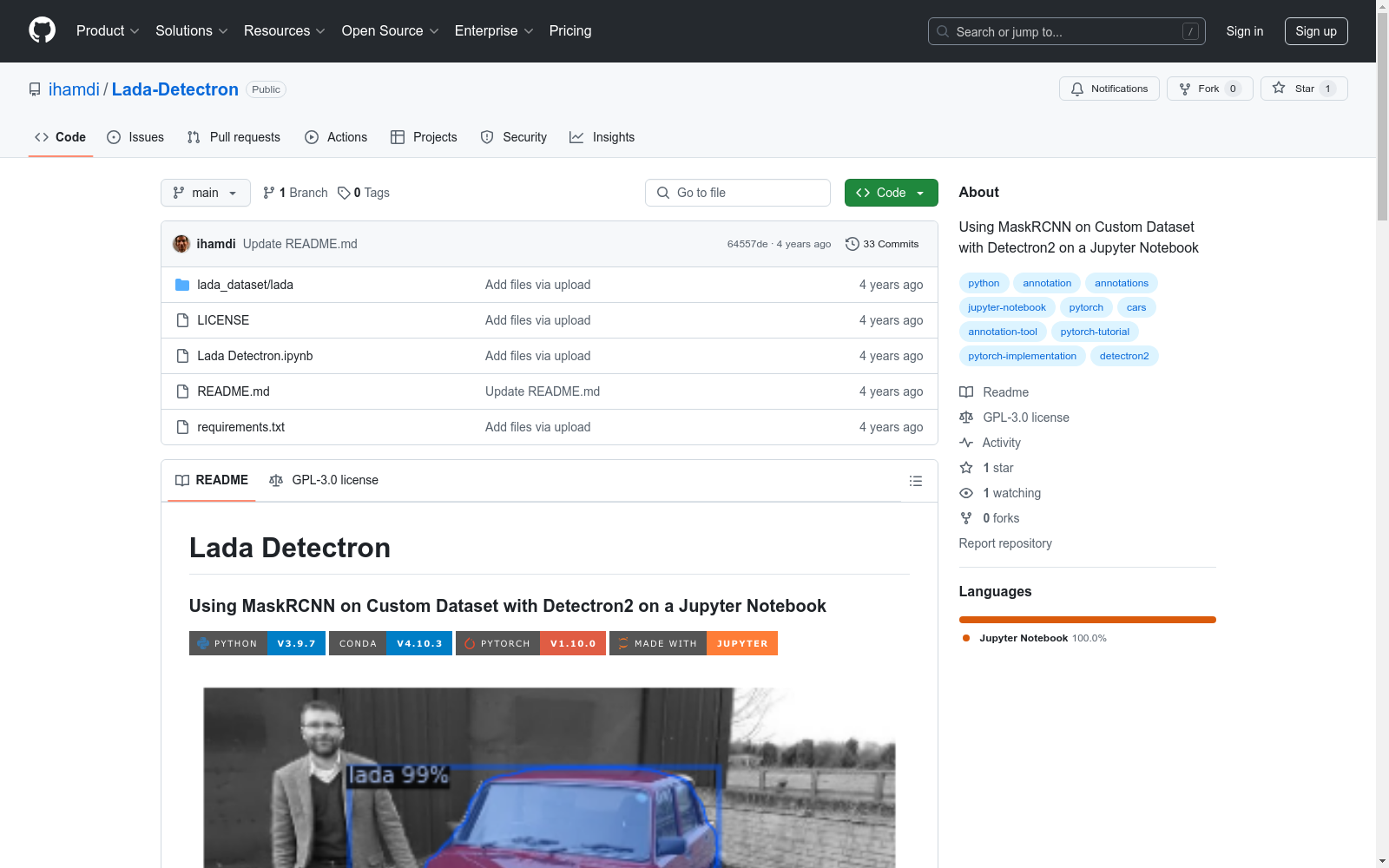
该数据集包含41张图像,其中29张用于训练,12张用于验证。图像从Google Images获取,并通过VGG Image Annotator创建和导出到json格式的标注。
This dataset comprises 41 images, with 29 designated for training and 12 for validation. The images were sourced from Google Images and annotated using the VGG Image Annotator, subsequently exported in JSON format.
创建时间:
2021-12-07
原始信息汇总
数据集概述
数据集名称
- Lada Detectron
数据集内容
- 图像来源:Google Images
- 标注工具:VGG Image Annotator
- 图像数量:总共41张,其中29张用于训练,12张用于验证
- 文件格式:JSON
数据集使用
- 使用环境:Jupyter Notebook
- 操作步骤:
- 在Jupyter Notebook中运行所有单元格以加载数据并训练模型。
- 若使用自定义数据集,需遵循相同的目录结构,并将VGG Image Annotator生成的JSON文件放置在相应文件夹中。
数据集性能
- 模型表现:在分割Ladas时表现良好,尤其是在车辆部分被遮挡的情况下。但在图像中存在多辆Lada时,模型可能会出现混淆。
数据集改进方向
- 未来工作:增加包含多辆车的训练图像,以提高模型在处理多车辆场景时的准确性。
搜集汇总
数据集介绍
构建方式
Lada数据集的构建过程主要依赖于从Google Images获取的图像资源,并通过VGG Image Annotator工具进行标注。该工具生成的标注数据以JSON格式导出,确保了数据的结构化和可扩展性。数据集共包含41张图像,其中29张用于训练,12张用于验证。这种构建方式不仅保证了数据的多样性和代表性,还为后续的模型训练提供了坚实的基础。
使用方法
使用Lada数据集时,用户需首先通过Jupyter Notebook加载数据,随后进行模型的训练和验证。数据集的结构设计使得用户能够轻松替换或扩展自定义数据集,只需遵循相同的目录结构并将VGG Image Annotator生成的JSON文件放置在相应文件夹中即可。这种灵活的使用方法不仅简化了数据集的集成过程,还为用户的个性化需求提供了便利。通过这种方式,用户可以在不同的应用场景中快速部署和验证模型,提升研究效率。
背景与挑战
背景概述
Lada数据集是一个基于Detectron2框架的自定义数据集,主要用于目标检测与实例分割任务。该数据集由研究人员Ibraheem Hamdi创建,旨在通过Mask R-CNN模型对Lada汽车进行精确的检测与分割。数据集包含41张图像,其中29张用于训练,12张用于验证。图像来源于Google Images,并通过VGG Image Annotator工具进行标注。该数据集的创建不仅为Detectron2的学习与实践提供了宝贵资源,也为目标检测领域的研究者提供了一个新的实验平台。尽管数据集规模较小,但其在特定目标(如Lada汽车)上的表现展示了深度学习模型在复杂场景中的潜力。
当前挑战
Lada数据集在构建与应用过程中面临多重挑战。首先,数据集的规模较小,仅包含41张图像,这可能导致模型在泛化能力上的不足,尤其是在处理多目标场景时表现欠佳。其次,数据集的标注依赖于手动操作,尽管使用了VGG Image Annotator工具,但标注的准确性与一致性仍需进一步提升。此外,数据集中缺乏多样化的场景与目标数量,限制了模型在实际应用中的鲁棒性。最后,Detectron2框架的复杂性也对数据集的训练与验证提出了较高的技术要求,尤其是在处理自定义数据集时,需要对框架进行深度定制与优化。这些挑战为未来的研究提供了改进方向,例如扩展数据集规模、引入自动化标注工具以及优化模型训练流程。
常用场景
经典使用场景
Lada数据集主要用于图像分割和目标检测领域的研究,尤其是在使用MaskRCNN和Detectron2框架进行自定义数据集训练时。该数据集通过Jupyter Notebook实现模型的训练与验证,展示了如何在特定对象(如Lada汽车)上进行实例分割。其经典使用场景包括在复杂背景中识别和分割目标对象,尤其是在目标部分遮挡的情况下,模型仍能保持较高的识别精度。
解决学术问题
Lada数据集解决了图像分割和目标检测领域中的多个学术问题,特别是在小样本数据集上的模型训练和验证。通过该数据集,研究者可以探索如何在有限数据条件下优化模型性能,尤其是在目标对象形状较为简单且易于标注的情况下。此外,该数据集还为研究多目标场景下的分割精度提供了实验基础,帮助改进模型在复杂场景中的表现。
实际应用
在实际应用中,Lada数据集可用于开发智能交通系统中的车辆识别模块,尤其是在特定车型的检测与分类任务中。例如,该数据集可以用于训练模型以识别特定品牌的车辆,进而应用于交通监控、停车场管理或自动驾驶系统中的车辆识别。此外,该数据集还可用于研究车牌检测与识别技术,为智能交通执法提供技术支持。
数据集最近研究
最新研究方向
在计算机视觉领域,Lada数据集的最新研究方向主要集中在基于MaskRCNN和Detectron2框架的自定义数据集训练与验证。该数据集通过VGG Image Annotator工具进行标注,包含41张图像,其中29张用于训练,12张用于验证。当前研究热点在于提升模型在多目标场景下的分割精度,特别是在图像中存在多个Lada汽车时的识别能力。未来研究方向可能包括对不同汽车模型的精确区分,以及车牌检测与识别技术的探索。这些研究不仅有助于提升自动驾驶和智能监控系统的性能,也为计算机视觉领域的算法优化提供了新的实验平台。
以上内容由遇见数据集搜集并总结生成


