FatimahEmadEldin/Arabic-Emotional-Audio-Dataset-Baved
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/FatimahEmadEldin/Arabic-Emotional-Audio-Dataset-Baved
下载链接
链接失效反馈官方服务:
资源简介:
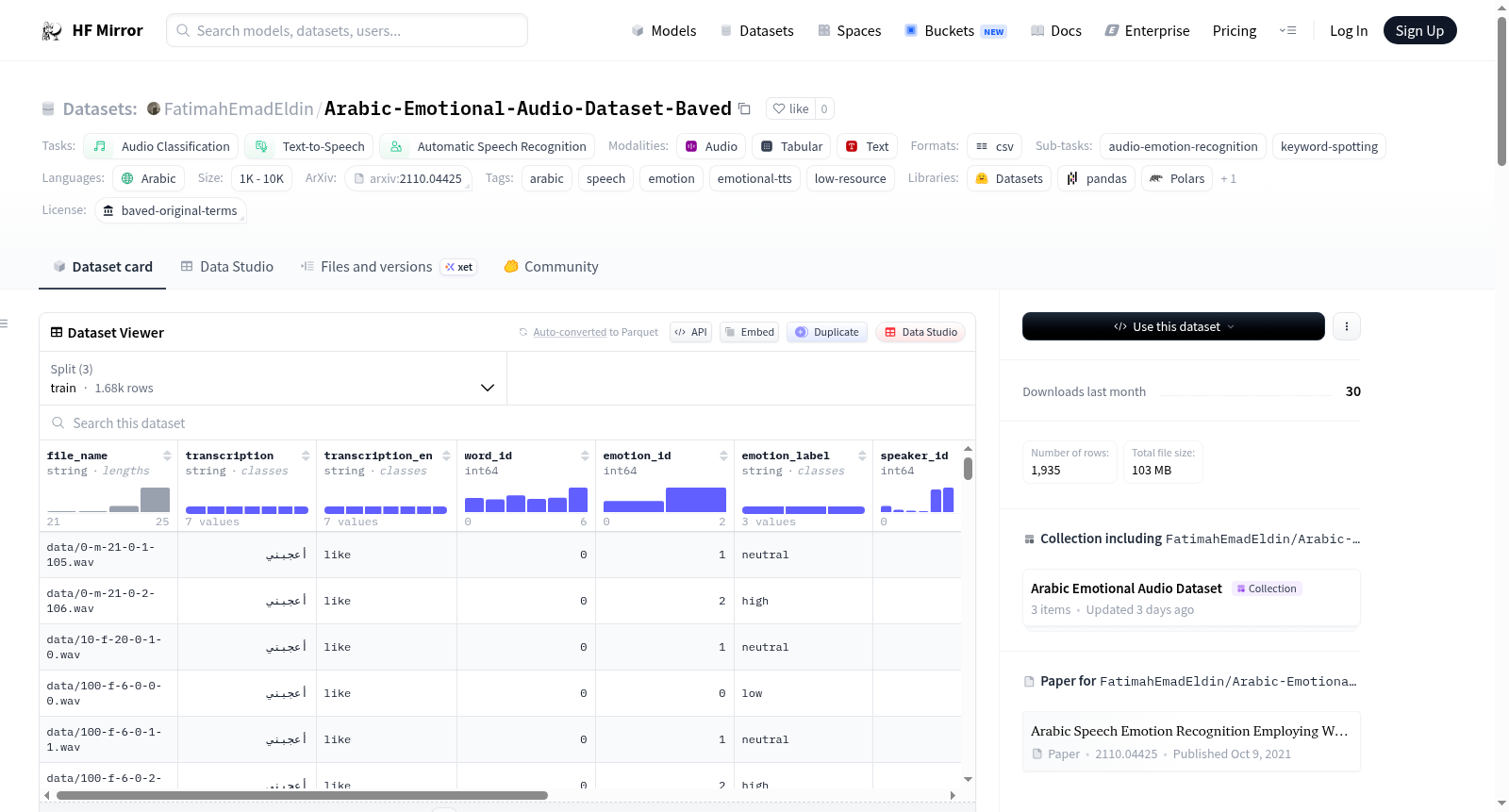
BAVED(基本阿拉伯语语音情感数据集)是一个重新打包的、转录对齐的阿拉伯语语音情感数据集,包含明确的阿拉伯语转录、英语注释、说话者元数据以及说话者不相交的训练/验证/测试分割。数据集包含1935个独特的录音,来自60个说话者(44名男性,16名女性),年龄在5至41岁之间。涵盖了7个阿拉伯语单词和3种情感强度级别,共21种独特的文本-情感对。录音以16 kHz单声道WAV格式提供。数据集适用于语音情感识别、情感/副语言TTS研究以及带情感调节的关键词识别。
BAVED — Basic Arabic Vocal Emotions Dataset (TTS-ready repackaging) is a re-packaged, transcript-aligned version of the Basic Arabic Vocal Emotions Dataset (BAVED) with explicit Arabic transcripts, English glosses, speaker metadata, and speaker-disjoint train/validation/test splits. It includes 1935 unique recordings from 60 speakers (44 male, 16 female), aged 5–41. The dataset covers 7 Arabic words and 3 emotion intensity levels, resulting in 21 unique text-emotion pairs. Recordings are provided in 16 kHz mono WAV format. The dataset is useful for speech-emotion recognition, emotional/paralinguistic TTS research, and keyword spotting with affective conditioning.
提供机构:
FatimahEmadEldin
搜集汇总
数据集介绍
构建方式
Arabic-Emotional-Audio-Dataset-Baved(BAVED)是一个面向阿拉伯语音情感识别与低资源情感语音合成任务的数据集。其构建基础源自Aouf Yacine发布的原始BAVED语料库,经过重新打包与元数据整合而成。数据集包含了1935条去重后的独有录音,由60位讲阿拉伯语的发音人(其中男性44人、女性16人,年龄覆盖5至41岁)在多种录制环境下采集。所有音频被统一转换为16 kHz单声道WAV格式。每个样本对应7个阿拉伯词语与3种情感强度(低、中性、高)的组合,共产生21种独特的文本-情感对。数据集按说话人非重叠原则划分为训练集(48人,1681条)、验证集(6人,213条)与测试集(6人,41条),以确保模型泛化能力的客观评估。
特点
该数据集的核心特点在于其专为低资源阿拉伯语情感研究而设计,词汇量虽小(仅7个词语),但情感维度的精细标注使其成为情感语音识别与封闭词汇情感合成研究的理想实验平台。每条录音均附带阿拉伯语原文转写、英文释义、说话人ID、性别、年龄以及情感标签等丰富元数据,便于多角度分析。值得注意的是,数据集存在一定的不平衡性:男性说话人数量约为女性的三倍,且多数说话人年龄集中在18至23岁之间。同时,录音采集设备与环境各异,虽经幅度归一化处理,但原始声学条件差异仍然存在,这一特点既构成了模型的挑战,也反映了真实场景的多样性。
使用方法
使用该数据集时,可通过HuggingFace的datasets库直接加载预划分的元数据文件(metadata_train.csv、metadata_validation.csv、metadata_test.csv)。用户只需调用load_dataset函数并指定数据集名称,即可便捷获取包含音频路径、转写文本、情感标签等字段的结构化数据。该数据集适合用于三方面研究:一是面向说话人泛化的语音情感识别,二是基于封闭词汇的情感参数可控的合成语音生成,三是带有情感条件的唤醒词或关键词检测任务。需注意,由于词汇量有限,该数据集不适用于通用阿拉伯语语音识别或合成任务,其设计初衷是作为情感与副语言学研究的可控实验平台。
背景与挑战
背景概述
阿拉伯语情感语音识别(Arabic Speech Emotion Recognition, SER)是低资源语音处理领域的重要研究方向,由于阿拉伯语方言多样性及情感标注数据匮乏,相关研究进展长期受限。Basic Arabic Vocal Emotions Dataset(BAVED)由Aouf Yacine于2019年创建,后经Omar Mohamed等研究者在2021年利用Wav2Vec2.0与HuBERT模型进行现代化深度学习应用推广,成为阿拉伯语情感识别领域的基础性资源。该数据集包含1935条由60位讲者录制的16kHz单声道WAV音频,覆盖7个阿拉伯语词汇在三种情感强度下的表达,并提供了文本转写、英文释义及讲者元数据。BAVED的出现填补了阿拉伯语情感语音数据集的空白,为低资源语言的情感计算与跨讲者泛化研究提供了关键基准。
当前挑战
该数据集所应对的核心领域挑战在于阿拉伯语情感语音识别中标注数据稀缺与讲者泛化能力不足的问题。通过设计讲者不相交的训练-验证-测试划分,BAVED旨在模拟真实场景中用户身份未知的识别需求。然而,数据集自身构建面临多重局限:词汇仅限定于7个单词,远不足以覆盖自然口语中的丰富语义;讲者性别比例严重失衡(男性44人、女性16人),且年龄集中于18至23岁,无法支撑人口统计学模型的公平训练;录音设备与环境的不统一虽经音量归一化处理,但仍引入声学域偏移。上述因素共同制约了数据集的通用性与模型在真实场景中的鲁棒性,使得其在TTS与情感识别研究中更适用于受控条件下的原理验证,而非产业级部署。
常用场景
经典使用场景
Arabic-Emotional-Audio-Dataset-Baved(BAVED)作为针对阿拉伯语音情感识别的经典数据集,其最核心的使用场景在于构建和评估面向低资源语言的语音情感分类模型。该数据集包含1935条由60位阿拉伯语使用者录制的语音样本,涵盖7个基础词汇,并以高中低三种情感强度进行标注。研究者常利用该数据集的说话人独立划分策略,训练端到端的情感识别系统,例如基于Wav2Vec2.0或HuBERT的深度神经网络,以验证模型在跨说话人泛化能力上的表现。由于词汇量有限且情感标注明确,BAVED为阿拉伯语情感计算领域提供了标杆性的基准测试平台。
解决学术问题
该数据集解决了阿拉伯语作为低资源语言在语音情感识别研究中缺乏标准化标注语料的关键难题。在BAVED出现之前,阿拉伯语情感语音数据集数量稀少且规模有限,严重制约了深度学习方法在该语言情感计算领域的应用。BAVED的发布使得研究者能够系统性地探索情感类别与声学特征之间的映射关系,并推动对比不同预训练模型(如Wav2Vec2.0与HuBERT)在弱资源情景下的迁移学习效果。其意义在于为阿拉伯语自然语言处理建立了可复现的实验基准,促进了多语言情感识别系统的公平性评估。
衍生相关工作
BAVED数据集衍生出一系列具有影响力的研究工作。Mohamed等人首次将Wav2Vec2.0与HuBERT预训练模型迁移至BAVED上,开创了阿拉伯语语音情感识别的最优实践路线。Aljuhani等人则在此基础上探索了数据增强技术对卷积神经网络情感分类性能的提升效果。该数据集还启发了面向低资源语言的跨语种情感识别框架设计,以及情感语音合成(E-TTS)中可控情感强度生成的探索。此外,BAVED被用于验证说话人解耦表征学习对情感鲁棒性的改善,推动了语音情感计算领域向更广泛的语种覆盖发展。
以上内容由遇见数据集搜集并总结生成


