MT-Nemotron-CC
收藏Hugging Face2025-11-27 更新2025-11-28 收录
下载链接:
https://huggingface.co/datasets/MultiSynt/MT-Nemotron-CC
下载链接
链接失效反馈官方服务:
资源简介:
该数据集包含多种语言的翻译数据,使用Unbabel/Tower-Plus-9B和Unbabel/Tower-Plus-72B模型生成。数据被分为三个部分:完整数据集(all),平行数据集(parallel),和额外数据集(additional)。每个语言都有相应的数据集,并且每个数据集都包含平行和额外数据。数据集的统计数据包括行数和令牌数。数据集遵循开放数据共享许可协议(ODC-By)。
创建时间:
2025-11-22
原始信息汇总
MT-Nemotron-CC 数据集概述
数据集基本信息
- 数据集名称:MT-Nemotron-CC: Large-Scale Machine-Translated High Quality Web Text
- 许可证:Open Data Commons Attribution License (ODC-By) v1.0
- 任务类别:文本生成
- 支持语言:丹麦语、德语、芬兰语、法语、匈牙利语、冰岛语、意大利语、荷兰语、挪威语、波兰语、葡萄牙语、罗马尼亚语、西班牙语、瑞典语、乌克兰语
数据配置结构
主要配置
- all配置:默认配置,包含所有语言数据
- 语言特定配置:eng_Latn、dan_Latn、deu_Latn、fin_Latn、fra_Latn、hun_Latn、isl_Latn、ita_Latn、nld_Latn、nno_Latn、nob_Latn、pol_Latn、por_Latn、ron_Latn、spa_Latn、swe_Latn、ukr_Cyrl
数据分割类型
- all:完整数据集
- parallel:140,359,346个对齐文档,确保所有语言的索引i对应同一源文档
- additional:平行ID集之外的额外文档,可能存在于多个语言但非所有语言
翻译模型
- Unbabel/Tower-Plus-9B
- Unbabel/Tower-Plus-72B
数据统计
Tower-9B模型数据规模
| 语言 | 平行文档行数 | 平行文档词元数 | 额外文档行数 | 额外文档词元数 | 总行数 | 总词元数 |
|---|---|---|---|---|---|---|
| dan_Latn | 140,359,346 | 93,720,119,985 | 11,679,922 | 8,167,771,357 | 152,039,268 | 101,887,891,342 |
| deu_Latn | 140,359,346 | 86,224,287,652 | 12,114,249 | 7,760,598,781 | 152,473,595 | 93,984,886,433 |
| fin_Latn | 140,359,346 | 107,810,456,180 | 10,842,327 | 8,562,451,901 | 151,201,673 | 116,372,908,081 |
| fra_Latn | 140,359,346 | 91,918,898,830 | 10,828,162 | 7,435,088,340 | 151,187,508 | 99,353,987,170 |
| hun_Latn | 140,359,346 | 111,303,976,836 | 12,067,061 | 9,922,218,067 | 152,426,407 | 121,226,194,903 |
| isl_Latn | 140,359,346 | 125,939,627,306 | 12,020,892 | 11,163,989,062 | 152,380,238 | 137,103,616,368 |
| ita_Latn | 140,359,346 | 87,448,433,259 | 11,846,597 | 7,695,143,274 | 152,205,943 | 95,143,576,533 |
| nld_Latn | 140,359,346 | 90,727,492,728 | 11,828,269 | 8,003,369,583 | 152,187,615 | 98,730,862,311 |
| nno_Latn | 140,359,346 | 94,984,919,578 | 11,254,476 | 7,968,375,323 | 151,613,822 | 102,953,294,901 |
| nob_Latn | 140,359,346 | 91,160,503,742 | 11,946,935 | 8,065,898,773 | 152,306,281 | 99,226,402,515 |
| pol_Latn | 140,359,346 | 98,228,263,898 | 12,158,279 | 8,853,867,436 | 152,517,625 | 107,082,131,334 |
| por_Latn | 140,359,346 | 84,319,834,846 | 11,970,113 | 7,501,203,315 | 152,329,459 | 91,821,038,161 |
| ron_Latn | 140,359,346 | 102,319,320,989 | 11,524,067 | 8,760,695,533 | 151,883,413 | 111,080,016,522 |
| spa_Latn | 140,359,346 | 82,112,432,579 | 11,583,567 | 7,071,807,888 | 151,942,913 | 89,184,240,467 |
| swe_Latn | 140,359,346 | 90,313,282,296 | 12,085,093 | 8,116,468,953 | 152,444,439 | 98,429,751,249 |
| ukr_Cyrl | 140,359,346 | 109,801,774,415 | 10,788,799 | 8,827,872,053 | 151,148,145 | 118,629,646,468 |
| 总计 | 2,245,749,536 | 1,548,333,625,119 | 186,538,808 | 133,876,819,639 | 2,432,288,344 | 1,682,210,444,758 |
Tower-72B模型数据规模
| 语言 | 平行文档行数 | 平行文档词元数 | 额外文档行数 | 额外文档词元数 | 总行数 | 总词元数 |
|---|---|---|---|---|---|---|
| deu_Latn | 140,359,346 | 104,119,301,465 | 14,430,137 | 12,981,081,999 | 154,789,483 | 117,100,383,464 |
| fin_Latn | 140,359,346 | 130,009,031,289 | 13,530,558 | 14,443,444,754 | 153,889,904 | 144,452,476,043 |
| ita_Latn | 140,359,346 | 106,816,755,230 | 12,677,053 | 13,739,166,677 | 153,036,399 | 120,555,921,907 |
| spa_Latn | 140,359,346 | 98,986,459,207 | 14,429,723 | 14,539,782,779 | 154,789,069 | 113,526,241,986 |
| swe_Latn | 140,359,346 | 110,585,594,631 | 11,198,643 | 13,543,437,965 | 151,557,989 | 124,129,032,596 |
| 总计 | 701,796,730 | 550,517,141,822 | 66,266,114 | 69,246,914,174 | 768,062,844 | 619,764,055,996 |
数据来源
- 基于Common Crawl网络数据
- 遵循CommonCrawl使用条款
引用要求
使用本数据集时需引用此仓库和Nemotron-CC
搜集汇总
数据集介绍
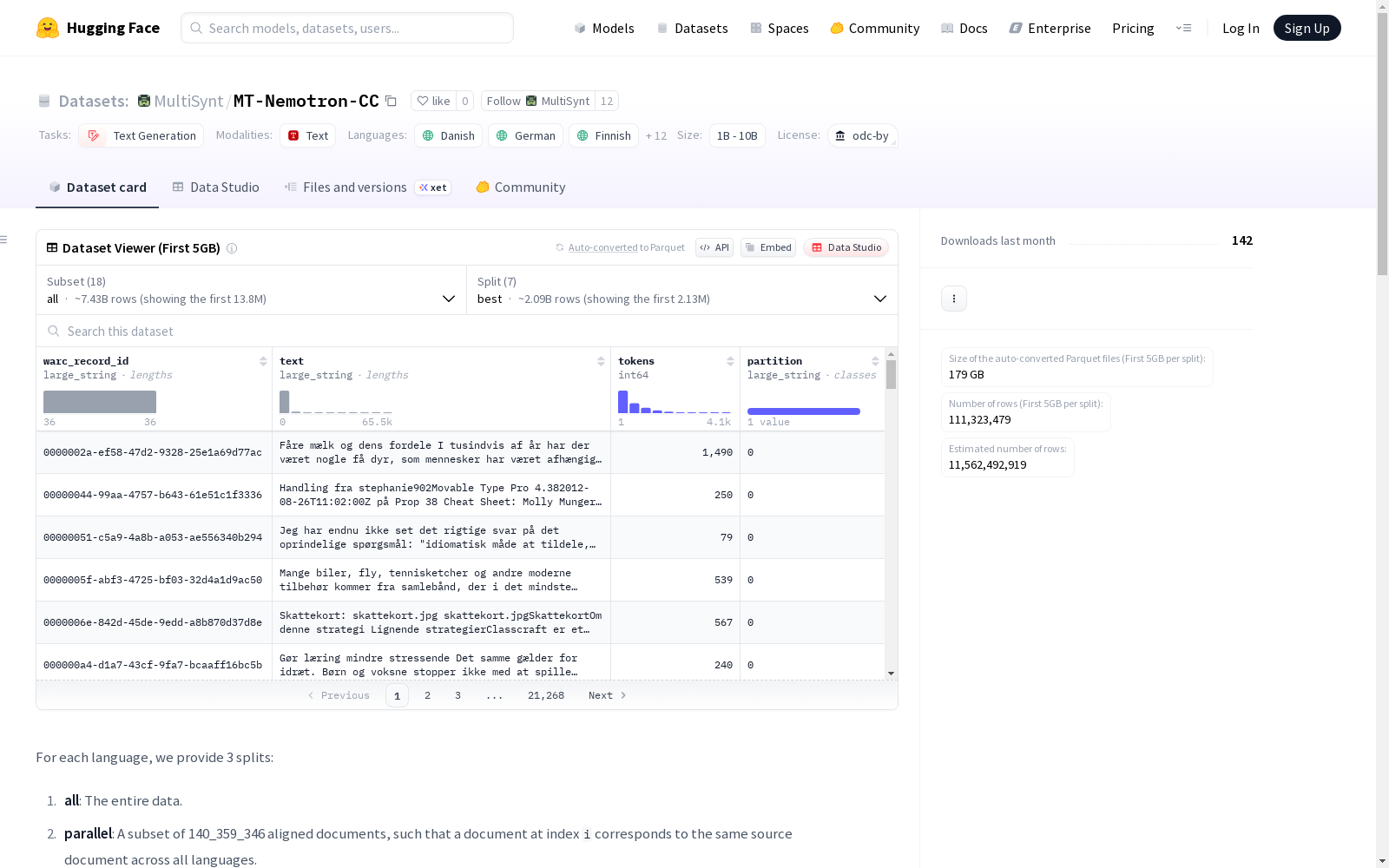
构建方式
在机器翻译研究领域,MT-Nemotron-CC数据集通过先进的神经机器翻译模型实现了大规模多语言文本的构建。该数据集基于Nemotron-CC高质量网络文本,采用Tower-Plus-9B和Tower-Plus-72B模型对原始英语语料进行精准翻译,涵盖丹麦语、德语、芬兰语等15种语言。构建过程严格遵循平行语料对齐原则,确保每个语言对在相同索引位置保持文档级对应关系,同时通过附加语料扩展了语言覆盖的多样性。
特点
该数据集呈现出显著的多维度特征,其核心优势在于覆盖了拉丁字母与西里尔字母书写的多种语言体系。通过统计表可见,tower9b模型生成的平行语料达2.25亿文档,总词元数量突破1.5万亿,而tower72b模型在德语等语言上展现出更高的词元密度。数据集采用分片存储架构,提供全量集、平行语料子集和附加语料子集三种划分方式,每种语言还细分为不同模型版本的数据切片,为研究者提供了灵活的语料选择空间。
使用方法
研究者可通过HuggingFace平台直接加载该数据集,利用config配置参数选择特定语言或模型版本。数据以parquet格式存储,支持按‘all’、‘parallel’、‘additional’三种分割方式加载,其中平行语料适用于机器翻译模型训练,附加语料可用于语言模型预训练。使用时应遵循ODC-By许可协议,并按规定引用原始论文及数据集仓库,确保符合CommonCrawl使用条款的规范要求。
背景与挑战
背景概述
多语言自然语言处理领域长期面临高质量训练数据稀缺的挑战,MT-Nemotron-CC数据集应运而生。该数据集由MultiSynt团队于2025年构建,基于Nemotron-CC原始语料,采用Tower-Plus系列翻译模型对15种欧洲语言进行大规模机器翻译。其核心研究目标在于突破单语语料局限,通过构建平行语料与补充语料的双重架构,为跨语言预训练模型提供数万亿token级别的多语言文本资源。该数据集通过精细的语料对齐机制与分层数据组织,显著提升了低资源语言的模型表现,对推动多模态语言理解与生成任务具有里程碑意义。
当前挑战
在机器翻译质量优化层面,需解决低资源语言如冰岛语与乌克兰语的语义保真度问题,同时应对多语言平行语料对齐中的词汇歧义与文化特定表达转换难题。数据构建过程中面临双重挑战:其一是从Common Crawl原始数据中提取高质量源文本时,需克服网页噪声过滤与文本结构规范化的技术瓶颈;其二是维持超大规模语料库跨语言版本一致性时,需设计高效的分布式校验机制以应对万亿级token的质控压力。
常用场景
衍生相关工作
基于该数据集衍生的经典研究包括多语言掩码语言模型预训练范式的优化,以及跨语言提示学习方法的创新。研究者利用其平行语料特性开发了XLM-RoBERTa的增强版本,在XTREME基准测试中取得显著提升。同时催生了针对低资源语言的课程学习策略,通过渐进式训练有效改善了小语种的语言理解能力。
数据集最近研究
最新研究方向
在机器翻译与多语言预训练领域,MT-Nemotron-CC数据集凭借其大规模平行语料与补充文档的独特结构,正推动多语言大模型的前沿探索。当前研究聚焦于利用该数据集构建跨语言对齐表示,通过Tower-Plus系列翻译模型生成的数十亿级高质量译文,显著提升了低资源语言的语义建模能力。随着全球多语言应用需求的激增,该数据集在促进语言技术普惠、消除数字鸿沟方面展现出深远影响,为构建包容性人工智能系统奠定了数据基石。
以上内容由遇见数据集搜集并总结生成


