lance-format/librispeech-clean-lance
收藏Hugging Face2026-05-08 更新2026-05-10 收录
下载链接:
https://hf-mirror.com/datasets/lance-format/librispeech-clean-lance
下载链接
链接失效反馈官方服务:
资源简介:
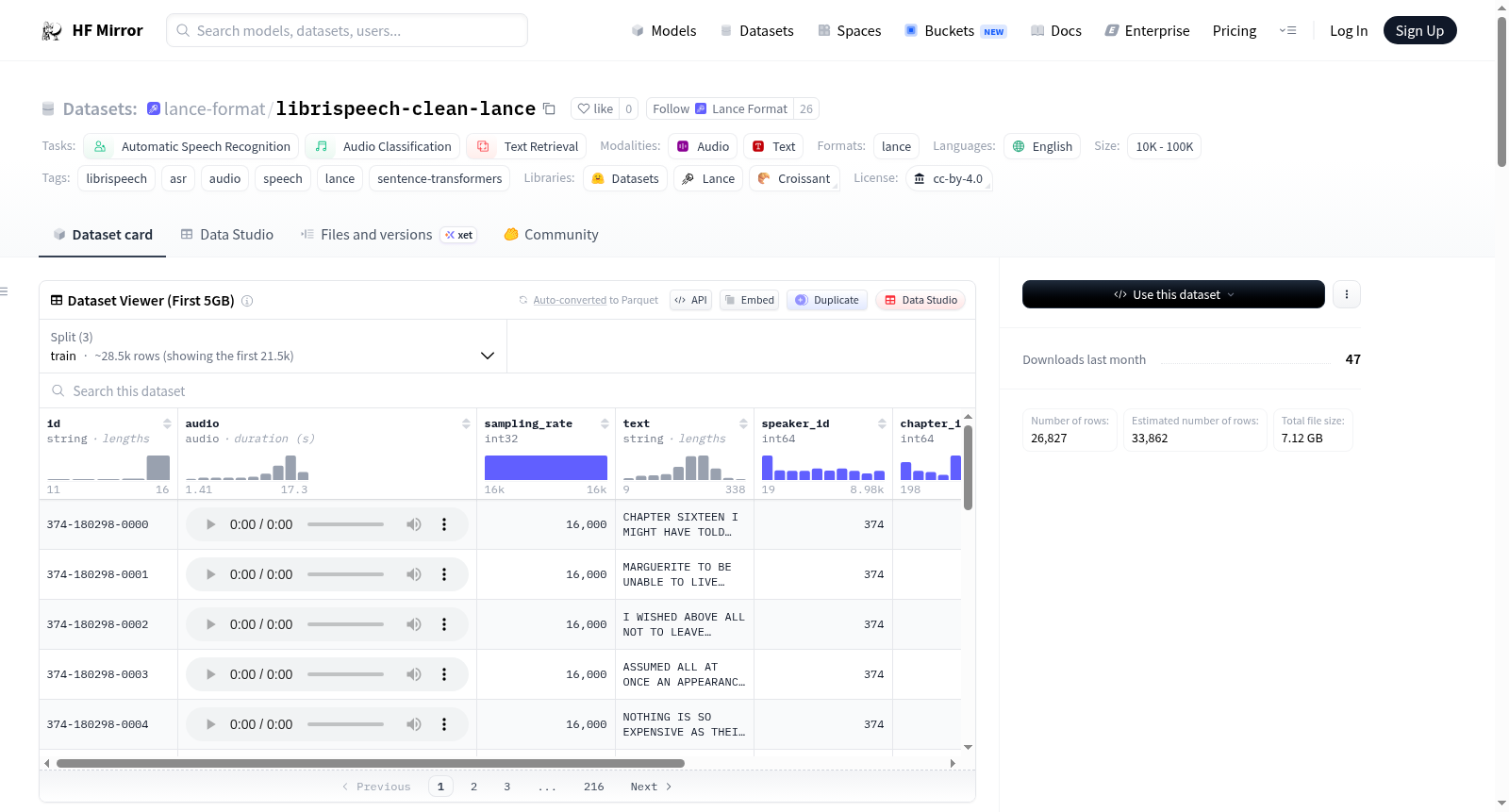
LibriSpeech clean(Lance格式)是LibriSpeech ASR clean配置的Lance格式版本。音频以内联FLAC字节形式存储(未重新编码);转录本经过句子嵌入处理,支持开箱即用的语义转录搜索。数据集包含标准ASR验证集、测试集和100小时的干净训练子集。数据模式包括音频、采样率、转录文本、说话者ID、章节ID、字符数和文本嵌入。数据集还预建了向量和全文索引,便于搜索。数据集源自openslr/librispeech_asr,基于公共领域的LibriVox有声读物语料库,遵循CC BY 4.0许可。
LibriSpeech clean (Lance Format) is a Lance-formatted version of the LibriSpeech ASR clean configuration. Audio is stored inline as FLAC bytes (no re-encoding); transcripts are sentence-embedded for out-of-the-box semantic transcript search. The dataset includes standard ASR validation and test sets, and a 100-hour clean training subset. The schema comprises audio, sampling rate, transcript text, speaker ID, chapter ID, character count, and text embedding. Pre-built vector and full-text indices enable efficient searching. The dataset is sourced from openslr/librispeech_asr, built from the public-domain LibriVox audiobook corpus, and released under CC BY 4.0 license.
提供机构:
lance-format
搜集汇总
数据集介绍
构建方式
LibriSpeech-clean-lance数据集源于经典的LibriSpeech ASR语料库,经格式迁移与功能增强后以Lance格式呈现。其构建过程保留了原始音频的FLAC编码,确保音频内容无损且采样率恒定于16kHz;同时,为每条语音转录文本预计算并存储了基于sentence-transformers的all-MiniLM-L6-v2模型的384维余弦归一化嵌入向量,并直接内联于数据集中。此外,该数据集在音频、文本与嵌入字段上预建了向量索引(IVF_PQ)、全文索引(FTS)以及B树索引,首次实现了语音数据、语义向量与检索索引的端到端融合存储,极大提升了搜索与过滤效率。
特点
该数据集最突出的特点在于其高度一体化的数据结构设计。它将音频字节流、转录文本、说话人元数据与语义嵌入向量同置一个Lance列存文件中,摒弃了传统ASR数据集需同时管理音频文件、标注JSON与向量库的繁琐模式。预计算的文本嵌入支持即时的语义级转录检索,无需外部编码流程;而内建的多种索引(如基于余弦相似度的IVF_PQ向量索引及全文索引)使得用户在本地或HuggingFace Hub上均可直接执行近似最近邻搜索与精确关键词匹配。此外,数据集保留LibriSpeech原始分区(dev_clean、test_clean、train_clean_100),并提供清晰的列式模式与元数据字段,便于听众按说话人或章节做细粒度过滤。
使用方法
使用方法极为简洁:用户通过Lance库的dataset接口直接加载存储于HuggingFace Hub上的.lance文件,即可读取音频字节流并用soundfile解码为波形数组以馈入模型。利用预计算的text_emb列和向量索引,只需一条scanner调用即可实现语义化的转录检索,返回最相关的若干语音片段及其元数据。同时,全文检索与字段过滤(如speaker_id)功能支持灵活的数据子集抽取。数据集还设计了良好的可扩展性,允许用户轻松添加新列(如模型预测结果或说话人嵌入)而无需重写整个数据,适用于ASR基准测试、语音分类与语义搜索等多种任务场景。
背景与挑战
背景概述
LibriSpeech数据集由Vassil Panayotov、Guoguo Chen、Daniel Povey和Sanjeev Khudanpur于2015年提出,源自LibriVox公共领域有声读物语料库,基于CC BY 4.0许可发布。该数据集专注于自动语音识别(ASR)任务,提供了高质量的英文朗读语音及其转录文本,成为ASR领域最经典的基准之一。其“clean”子集包含100小时经过精心筛选的低噪声语音,广泛应用于模型训练与评估,极大推动了端到端语音识别系统的发展。librispeech-clean-lance版本在此基础上采用Lance格式存储,将音频、转录文本及语义嵌入整合为单一高效数据格式,并内置向量与全文索引,便于快速检索与灵活扩展。
当前挑战
该数据集所解决的领域挑战在于:ASR模型需从复杂声学信号中准确解码自然语言,而传统数据集常面临音频与文本分离、检索效率低下的问题;librispeech-clean-lance通过Lance格式实现数据、嵌入与索引的一体化存储,大幅提升了大规模语音数据的访问与搜索性能。构建过程中遇到的挑战包括:保持原始FLAC音频的完整性而不重新编码,确保转录文本的语义嵌入(基于all-MiniLM-L6-v2)与向量索引兼容,并设计高效的数据模式以支持多字段索引(如全文搜索、向量相似度搜索及元数据过滤),同时兼顾存储与计算效率。
常用场景
经典使用场景
LibriSpeech-clean-lance数据集作为自动语音识别(ASR)领域的经典基准,其最经典的使用场景在于训练和评估端到端语音识别模型。该数据集提供了100小时干净英语语音数据,每个音频片段均以FLAC格式无损存储,并配有精准的文本转录,为学术界和工业界构建鲁棒的语音识别系统提供了标准化测试平台。借助其预构建的向量索引,研究人员可以快速执行语义化的语音检索任务,例如通过自然语言描述匹配相关语音片段,极大地扩展了传统ASR任务的应用维度。
衍生相关工作
围绕该数据集衍生了一系列经典工作,包括但不限于基于LibriSpeech的Wave2Vec 2.0自监督预训练模型、Conformer端到端语音识别架构以及Whisper多语言语音系统。后续研究者还利用其语义向量索引推动了CNA-T(基于常识的语音翻译)和语音文本跨模态检索任务的发展。此外,该数据集的高效Lance格式催生了诸如“语音数据湖”等概念,使得研究人员能够在单一存储格式下完成音频存储、检索与模型输入,对语音领域的数据工程范式产生了深远影响。
数据集最近研究
最新研究方向
在语音识别与语义检索交叉融合的前沿浪潮中,librispeech-clean-lance数据集通过将音频、文本与预计算语义嵌入(all-MiniLM-L6-v2)整合于Lance列式存储格式,开创了多模态联合检索与高效推理的新范式。该版本尤以语义转录检索和向量索引(IVF_PQ)为亮点,使得研究者可在无需额外编码器的情况下直接进行基于语义相似度的语音文本匹配,极大降低了语音检索系统的部署门槛。结合嵌入式全文索引与说话人筛选机制,该数据集为面向大规模语音语料库的细粒度语义理解与知识挖掘提供了坚实底座,同时规避了传统FLAC音频与元数据分离存储所带来的I/O瓶颈,是当前面向多模态检索增强生成(RAG)与上下文感知语音AI系统研发中的重要基础设施。
以上内容由遇见数据集搜集并总结生成


