SpatialVID
收藏arXiv2025-09-12 更新2025-11-24 收录
下载链接:
https://hf-mirror.com/datasets/SpatialVID/SpatialVID
下载链接
链接失效反馈官方服务:
资源简介:
SpatialVID是一个大规模视频数据集,包含显式空间注释,如相机姿态、深度图、结构化标题和序列化运动指令。该数据集由7089小时的动态场景组成,通过从超过21000小时的原始视频中提取和处理而来。数据集通过一个层次化的过滤流程,去除了质量缺陷、尺寸不正确或标题不相关的视频内容,然后通过美学指标、亮度、光学字符识别和运动值的分层评分策略进行排序。高评分的视频片段经过双重注释流程,捕捉空间结构和语义信息,最终形成了SpatialVID数据集。该数据集旨在连接原始像素与物理世界,为视频和3D视觉研究提供关键资产。
SpatialVID is a large-scale video dataset equipped with explicit spatial annotations, including camera poses, depth maps, structured captions, and sequential motion instructions. It consists of 7089 hours of dynamic scenes, extracted and processed from over 21,000 hours of raw video footage. The dataset first undergoes a hierarchical filtering pipeline to remove video content with quality defects, incorrect dimensions, or irrelevant captions, and then is ranked using a hierarchical scoring strategy covering aesthetic metrics, brightness, optical character recognition (OCR), and motion values. High-scoring video clips go through a dual-annotation workflow to capture spatial structure and semantic information, ultimately forming the final SpatialVID dataset. This dataset aims to bridge raw pixels and the physical world, serving as a critical asset for video and 3D vision research.
提供机构:
南京大学 中国科学院自动化研究所
创建时间:
2025-09-12
搜集汇总
数据集介绍
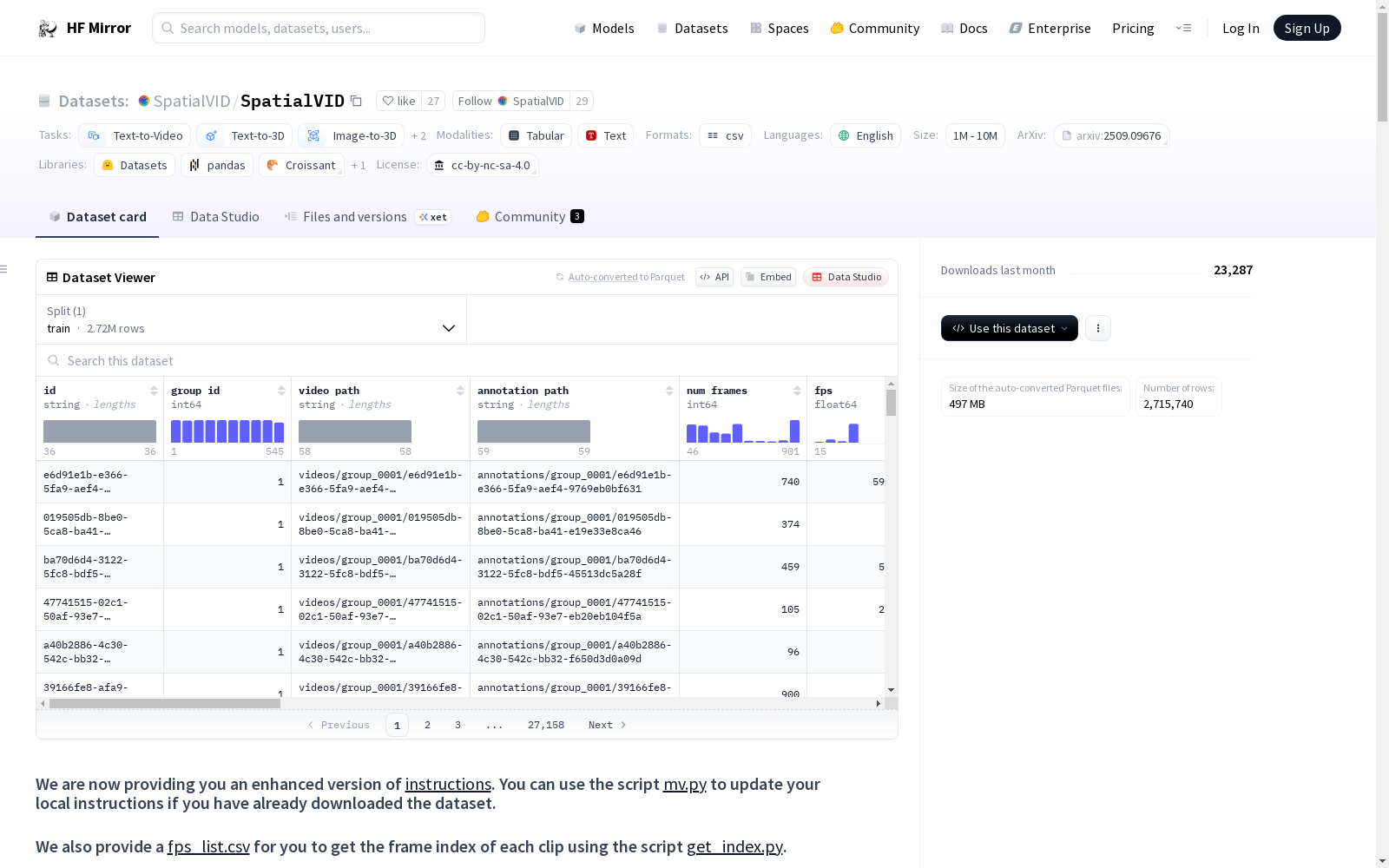
构建方式
在三维视觉研究领域,构建具备真实世界动态场景的大规模数据集对推动空间智能发展至关重要。SpatialVID通过从互联网采集超过21,000小时的原始视频,经过严格人工筛选保留具有丰富相机运动的片段,并采用分层过滤流程对视频质量进行多维度评估,包括美学评分、亮度范围、文字干扰比例和运动强度,最终从700万初始片段中提炼出2.71百万个高质量视频片段,总时长达到7,089小时。该流程通过标准化编码格式和场景分割技术,确保数据在分辨率和动态内容上的一致性,为三维重建任务提供稳定可靠的视觉基础。
特点
作为当前最大规模的动态视频空间标注数据集,SpatialVID的核心优势体现在其多模态标注体系的完备性。该数据集不仅提供逐帧相机位姿和深度图等几何标注,还创新性地引入结构化描述文本与序列化运动指令。其动态掩码标注通过结合运动概率图与分割模型,精准识别视频中的运动物体区域。特别值得注意的是,数据集通过融合视觉语言模型与几何先验,生成包含场景语义、相机运动趋势和层级属性标签的增强描述,有效解决了传统视频描述缺乏空间一致性的问题。这种几何与语义的深度融合,使数据集能同时支持三维重建与可控视频生成等交叉领域研究。
使用方法
该数据集的设计支持多层次的研究应用。在几何理解任务中,研究者可直接利用相机位姿和深度图训练空间感知模型,如通过运动指令序列实现相机轨迹的精确控制。对于视频生成任务,结构化描述文本为语义控制提供丰富条件信号,而动态掩码则支持运动物体的分离与编辑。数据集的层级结构允许用户根据需求选择不同质量子集,其中SpatialVID-HQ子集经过运动特征和类别分布的平衡采样,特别适用于模型稳健性评估。此外,数据集提供的运动趋势标签和场景属性标注,为跨模态对齐研究提供了细粒度的监督信号。
背景与挑战
背景概述
SpatialVID作为2025年发布的视频空间理解数据集,由南京大学与中国科学院自动化研究所联合研发,旨在解决三维视觉与视频生成领域的数据稀缺问题。该数据集基于超过2.1万小时的原始网络视频,通过层次化筛选流程提炼出7089小时高质量动态片段,涵盖城市街景、自然景观等多样化场景。其核心贡献在于首次实现了大规模真实动态视频与密集空间标注的深度融合,为三维重建和世界模拟任务提供了关键数据支撑。
当前挑战
在领域问题层面,现有视频数据集普遍缺乏显式几何标注,导致模型难以学习物理一致的时空动态。SpatialVID通过提供逐帧相机位姿、深度图与运动指令,直接应对动态场景三维重建的几何一致性挑战。构建过程中面临三大难题:原始视频存在剧烈抖动、动态物体干扰等质量问题,需设计多维度过滤策略;相机轨迹估计在复杂运动场景中易失效,需融合MegaSaM与SAM2模型提升鲁棒性;语义标注与空间信息的对齐困难,需构建视觉语言模型与几何先验协同的标注流水线。
常用场景
经典使用场景
在三维视觉与视频生成领域,SpatialVID凭借其大规模动态场景与密集空间标注的特性,成为训练空间感知模型的核心资源。该数据集通过提供逐帧相机位姿、深度图及运动指令,为神经辐射场重建、动态场景合成等任务提供了真实世界的几何先验。其涵盖的多样化相机运动轨迹与复杂环境交互,显著提升了模型在未知场景中的泛化能力与物理一致性。
衍生相关工作
SpatialVID已催生多项前沿研究,如基于相机轨迹控制的MotionCtrl框架、融合点云的空间感知生成模型ViewCrafter等。其标注体系为Hunyuan-GameCraft等交互式视频生成系统提供了运动语义监督,同时推动了DUSt3R系列模型在动态场景重建中的扩展应用。这些工作共同体现了数据集在连接三维重建与时空模拟领域的桥梁作用。
数据集最近研究
最新研究方向
在三维视觉与动态场景建模领域,SpatialVID数据集凭借其大规模真实世界视频与密集空间标注的特性,正推动前沿研究向数据驱动的世界模拟器方向发展。该数据集通过融合相机位姿、深度图及结构化运动指令,为可控视频生成与动态场景重建提供了关键支撑,相关研究聚焦于将几何先验嵌入生成式模型,以提升虚拟环境交互的真实性与物理一致性。其标注体系直接关联自动驾驶仿真、沉浸式内容创作等热点应用,通过统一语义与几何表征,显著增强了模型在复杂动态环境中的泛化能力与空间推理精度。
相关研究论文
- 1通过南京大学 中国科学院自动化研究所 · 2025年
以上内容由遇见数据集搜集并总结生成


