ScholarCopilot-Data-v1
收藏Hugging Face2024-12-08 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/TIGER-Lab/ScholarCopilot-Data-v1
下载链接
链接失效反馈官方服务:
资源简介:
ScholarCopilot-Data-v1数据集包含了Scholar Copilot的语料数据和嵌入向量。Scholar Copilot通过无缝集成自动文本完成和智能引用建议,改进了学术写作过程。它提供高质量的文本生成和精确的引用推荐,通过迭代和上下文感知的检索增强生成(RAG)技术。当前版本的Scholar Copilot利用了一个最先进的70亿参数语言模型(LLM),该模型在完整的Arxiv全论文语料库上训练。该模型擅长在引用、生成内容和参考论文的基础上做出上下文敏感的决策。主要功能包括:预测下三句的建议、按需提供精确的引用建议、以及全节自动完成。当前版本主要关注学术论文的引言和相关工作部分,未来版本将支持全文写作。
ScholarCopilot-Data-v1 dataset contains the corpus data and embedding vectors of Scholar Copilot. Scholar Copilot improves the academic writing workflow by seamlessly integrating automatic text completion and intelligent citation recommendation. It delivers high-quality text generation and precise citation recommendations via iterative, context-aware retrieval-augmented generation (RAG) techniques. The current version of Scholar Copilot leverages a state-of-the-art 7-billion-parameter large language model (LLM) trained on the complete full-text corpus of arXiv. This model excels at making context-aware decisions grounded in citations, generated content, and reference papers. Its core features include: suggesting the next three sentences, providing precise citation recommendations on demand, and automatic full-section completion. The current version primarily focuses on the introduction and related work sections of academic papers, while future versions will support full-text academic writing.
提供机构:
TIGER-Lab
创建时间:
2024-12-08
搜集汇总
数据集介绍
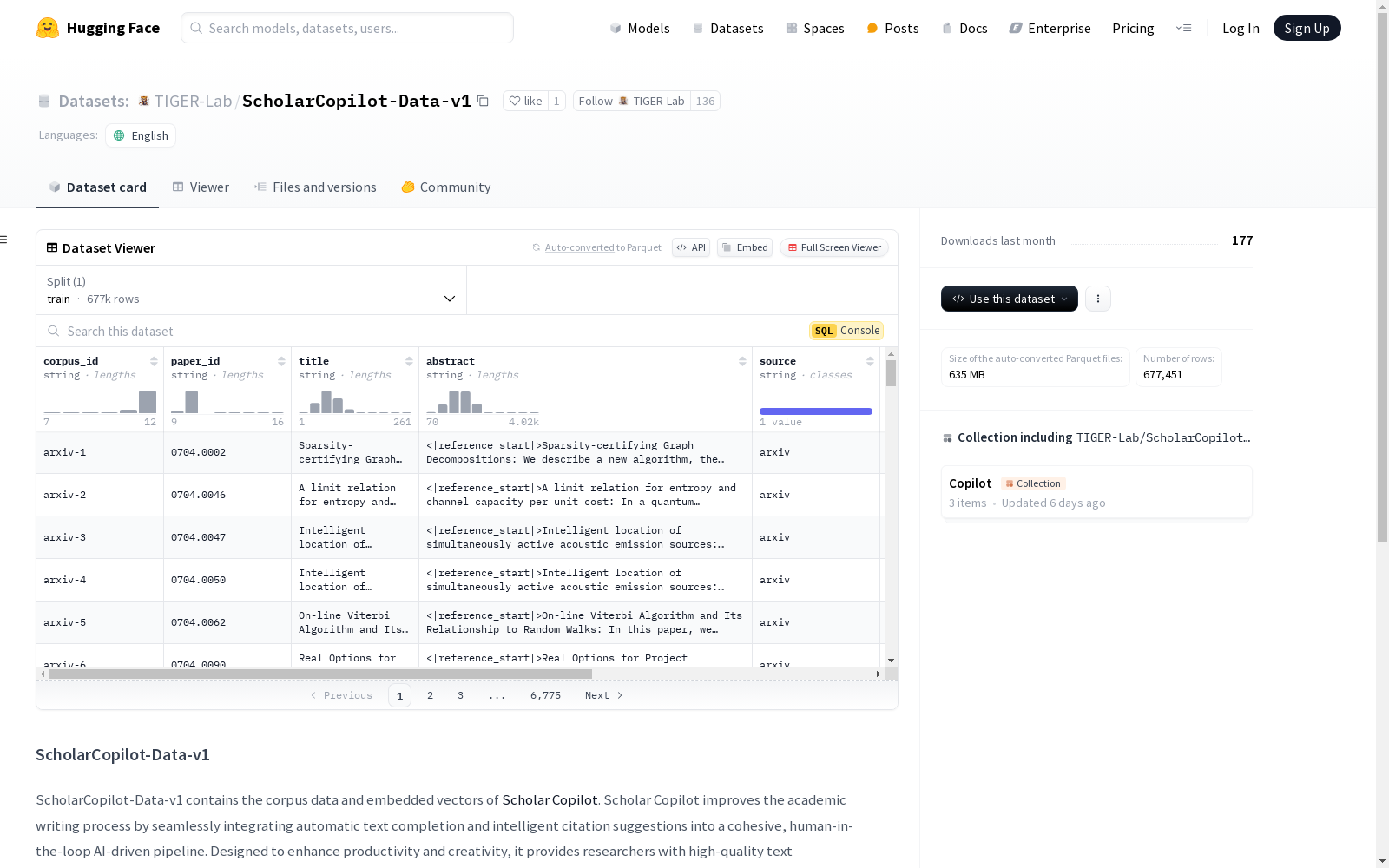
构建方式
ScholarCopilot-Data-v1数据集的构建基于Scholar Copilot项目的核心技术,该技术通过整合自动文本补全和智能引用建议,旨在提升学术写作的效率与质量。数据集包含了Arxiv全论文语料库的嵌入向量,并利用一个70亿参数的先进语言模型进行训练,该模型在检索增强生成(RAG)框架下,能够根据上下文进行敏感决策,从而实现高质量的文本生成和精确的引用推荐。
特点
ScholarCopilot-Data-v1数据集的显著特点在于其提供了三种核心功能:首先,通过预测下三句话并自动检索相关参考文献,极大地简化了写作过程;其次,在需要时提供精确且上下文相关的引用建议,增强了学术论文的严谨性;最后,支持全文段落的自动补全,帮助研究者在构思和起草阶段快速构建论文内容和结构。当前版本主要聚焦于学术论文的引言和相关工作部分,未来版本将扩展至全文的写作支持。
使用方法
ScholarCopilot-Data-v1数据集主要用于支持Scholar Copilot的学术写作辅助功能。用户可以通过该数据集获取自动化的文本补全和引用建议,特别适用于学术论文的引言和相关工作部分的撰写。数据集的嵌入向量和语言模型能够根据用户输入的上下文,动态生成连贯的文本内容,并推荐合适的参考文献,从而显著提升写作效率和内容质量。
背景与挑战
背景概述
ScholarCopilot-Data-v1数据集由TIGER-AI-Lab开发,旨在通过集成自动文本补全和智能引用建议,提升学术写作的效率与质量。该数据集基于Scholar Copilot项目,利用70亿参数的语言模型,训练于完整的Arxiv论文语料库,旨在通过迭代和上下文感知的检索增强生成(RAG)技术,提供高质量的文本生成和精确的引用推荐。其核心研究问题在于如何通过AI技术优化学术写作流程,特别是在自动生成内容和引用推荐方面。该数据集的推出对学术写作领域具有重要影响,为研究人员提供了一种高效、智能的写作工具。
当前挑战
ScholarCopilot-Data-v1数据集面临的挑战主要集中在两个方面。首先,如何确保生成的文本和引用建议在学术上准确且符合上下文,这是一个复杂的任务,涉及到对大量文献的深度理解和精准检索。其次,数据集的构建过程中,如何处理和整合庞大的Arxiv论文语料库,确保模型能够有效学习并生成高质量的学术内容,也是一个技术上的难题。此外,随着未来扩展到全篇论文写作,如何保持生成内容的连贯性和学术性,将是另一个重要的挑战。
常用场景
经典使用场景
ScholarCopilot-Data-v1数据集的经典使用场景主要集中在学术写作的辅助工具中。该数据集通过提供自动文本补全和智能引用建议,帮助研究人员在撰写学术论文时提高效率和创造力。具体而言,它能够预测接下来的三句话,并自动检索和引用相关参考文献,同时还能根据上下文提供精确的引用建议,从而在撰写论文的引言和相关工作部分时提供有力支持。
实际应用
在实际应用中,ScholarCopilot-Data-v1数据集被广泛应用于学术研究领域,特别是在撰写学术论文的过程中。研究人员可以利用该数据集提供的自动补全和引用建议功能,快速生成高质量的论文内容,尤其是在引言和相关工作部分。此外,该数据集还可用于学术写作的教学和培训,帮助学生和新手研究人员掌握学术写作的技巧和规范。
衍生相关工作
ScholarCopilot-Data-v1数据集的推出催生了一系列相关的经典工作。首先,基于该数据集的自动文本补全和引用建议功能,研究者们开发了多种学术写作辅助工具,进一步提升了学术写作的效率和质量。其次,该数据集的上下文感知生成模型为学术文本生成领域的研究提供了新的思路和方法。此外,ScholarCopilot-Data-v1的成功应用还激发了更多关于人工智能在学术写作中应用的研究,推动了该领域的技术进步。
以上内容由遇见数据集搜集并总结生成


