SCED
收藏Synthetic Contextual Enrichment Dataset (SCED)
数据集描述
概述
合成上下文增强数据集(SCED)是一个专门设计用于通过结合网络搜索和检索增强生成(RAG)来微调大型语言模型(LLMs)的数据集。SCED精心制作,提供丰富、上下文相关的数据,以增强LLMs在各种自然语言处理任务中的性能。
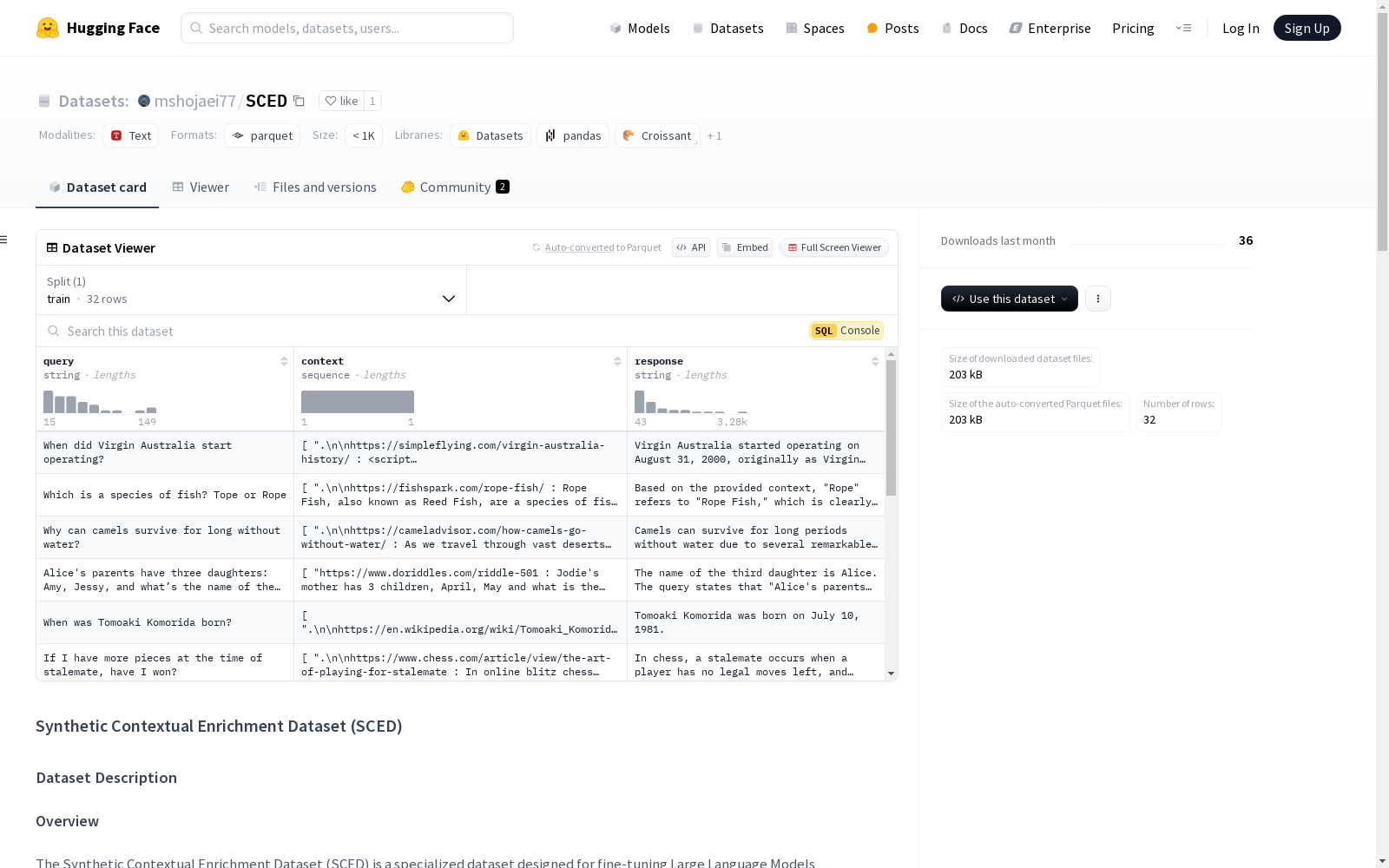
数据集内容
SCED包含一系列多样化的查询,每个查询都与其相应的上下文和响应配对。该数据集的结构旨在促进LLMs在问答、对话系统和内容生成等任务中的训练和评估。
数据集结构
数据集分为三个主要列:
- Query:输入的问题或陈述。
- Context:从网络上检索的相关文本信息,为查询提供丰富的背景。
- Response:基于提供的上下文生成的答案或回复。
语言
该数据集主要包含英语内容,并计划未来扩展到其他语言。
数据集创建
源数据
SCED来自各种基于网络的材料,包括文章、文档和其他文本资源。数据通过自动网络搜索和文本提取技术收集。
标注
每个查询都标注有上下文和响应,通过网络爬虫、文本嵌入和AI驱动的响应合成生成。
个人和敏感信息
已采取措施排除数据集中的个人身份信息和敏感内容。然而,用户应审查数据并根据其特定用例应用额外过滤器。
使用数据集的考虑因素
数据集的社会影响
SCED旨在提高机器学习模型在需要语言细微理解的应用中的准确性和相关性。通过提供丰富的上下文数据,该数据集旨在提高自动化响应和交互的质量。
偏见的讨论
数据集可能反映源材料中存在的偏见。鼓励用户在模型训练过程中分析和解决这些偏见,以确保公平和公正的结果。
其他已知限制
- 数据集目前仅提供英语版本。
- 响应的质量可能因检索上下文的准确性和相关性而异。
- 用户应注意数据集中可能存在的过时或不正确信息。
许可信息
SCED在知识共享署名-非商业性使用-相同方式共享4.0国际许可协议(CC BY-NC-SA 4.0)下发布。用户可以自由分享和改编数据集用于非商业目的,前提是他们给予适当的信用,指出任何更改,并以相同的许可分发他们的贡献。
联系
如有查询、反馈或合作机会,请联系数据集维护者 shojaei.dev@gmail.com。
引用
使用SCED时,请引用以下内容:
@dataset{SCED, author = {Dataset Maintainers}, title = {Synthetic Contextual Enrichment Dataset (SCED)}, year = {2023}, publisher = {SCED Dataset Organization}, address = {Virtual}, version = {1.0}, license = {CC BY-NC-SA 4.0} }