gonglinyuan/safim
收藏Hugging Face2024-04-06 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/gonglinyuan/safim
下载链接
链接失效反馈官方服务:
资源简介:
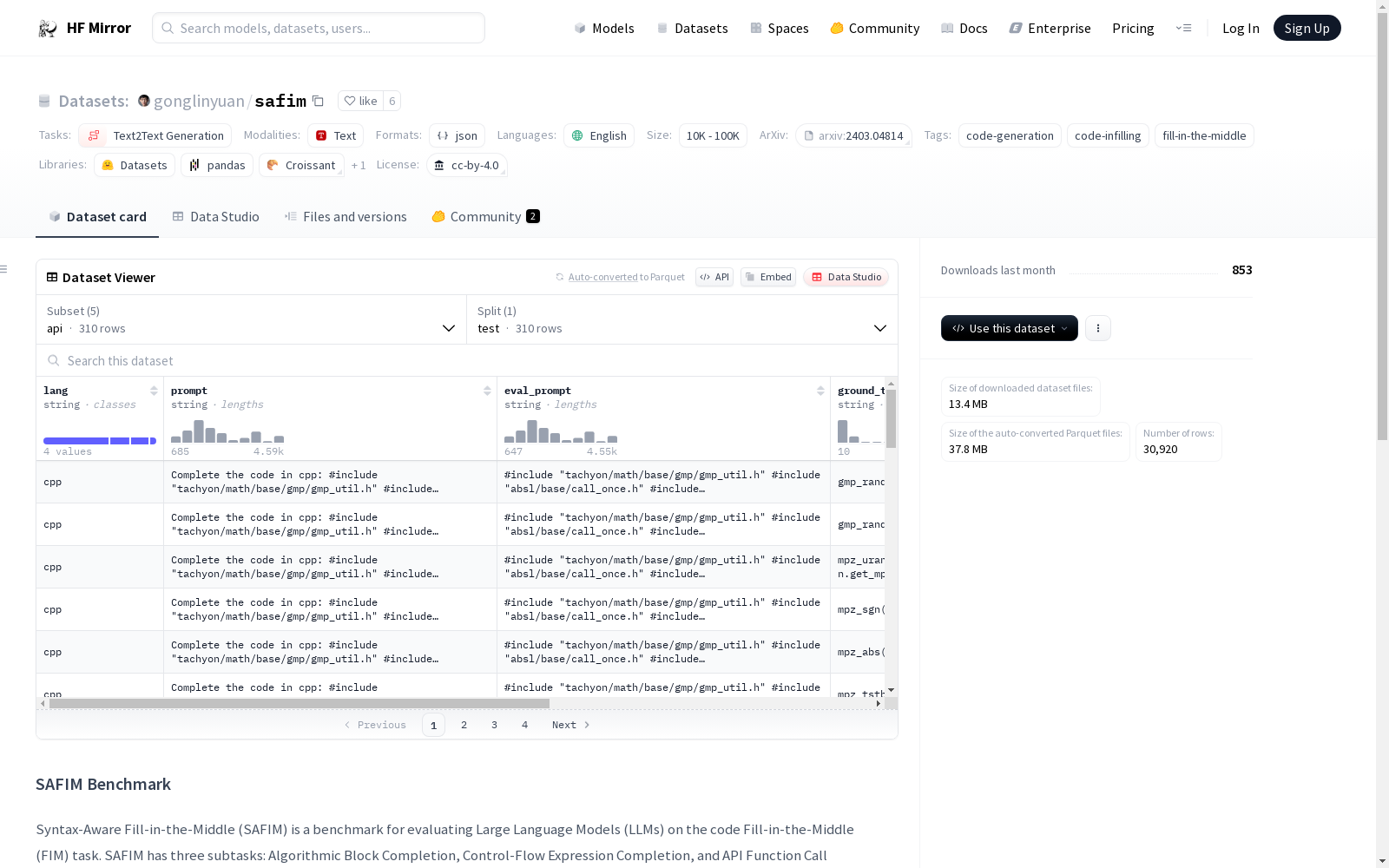
SAFIM(语法感知中间填充)是一个用于评估大型语言模型(LLMs)在代码中间填充(FIM)任务中的基准测试。SAFIM包含三个子任务:算法块补全、控制流表达式补全和API函数调用补全。该数据集来源于2022年4月至2023年1月提交的代码,以最小化数据污染对评估结果的影响。
SAFIM(语法感知中间填充)是一个用于评估大型语言模型(LLMs)在代码中间填充(FIM)任务中的基准测试。SAFIM包含三个子任务:算法块补全、控制流表达式补全和API函数调用补全。该数据集来源于2022年4月至2023年1月提交的代码,以最小化数据污染对评估结果的影响。
提供机构:
gonglinyuan
原始信息汇总
SAFIM Benchmark
概述
SAFIM(Syntax-Aware Fill-in-the-Middle)是一个用于评估大型语言模型(LLMs)在代码填空(Fill-in-the-Middle,FIM)任务上的基准测试。SAFIM包含三个子任务:算法块完成(Algorithmic Block Completion)、控制流表达式完成(Control-Flow Expression Completion)和API函数调用完成(API Function Call Completion)。数据来源为2022年4月至2023年1月提交的代码,以减少数据污染对评估结果的影响。
数据集信息
- 许可证:cc-by-4.0
- 任务类别:text2text-generation
- 语言:en
- 标签:code-generation, code-infilling, fill-in-the-middle
- 数据集名称:SAFIM
- 数据量:10K<n<100K
配置信息
-
config_name: block
- 数据文件:
- split: test
- path: block_completion.jsonl.gz
- 数据文件:
-
config_name: control
- 数据文件:
- split: test
- path: control_completion.jsonl.gz
- 数据文件:
-
config_name: api
- 数据文件:
- split: test
- path: api_completion.jsonl.gz
- 数据文件:
-
config_name: block_v2
- 数据文件:
- split: test
- path: block_completion_v2.jsonl.gz
- 数据文件:
搜集汇总
数据集介绍
构建方式
SAFIM数据集的构建,采取了对2022年4月至2023年1月期间提交至Codeforces的代码进行采样,以此确保评估结果的公正性与准确性。该数据集涵盖算法块完成、控制流表达式完成以及API函数调用完成三个子任务,旨在对大型语言模型在代码填充任务中的性能进行评估。
特点
SAFIM数据集的特点在于,其专注于语法感知的代码填充任务,提供了对大型语言模型在代码理解和生成方面的综合考量。数据集的多样性及复杂性,使其成为评估代码生成模型性能的重要基准。此外,数据集遵循cc-by-4.0协议,保证了数据的开放性与共享性。
使用方法
使用SAFIM数据集,用户可通过HuggingFace提供的接口方便地加载不同配置的数据文件,如block、control、api等。用户可以依据自己的研究需求,选择合适的子任务进行模型训练和评估,并通过 leaderboard 进行性能比较。数据集的详细使用指南和提交说明,可在官方GitHub仓库中找到。
背景与挑战
背景概述
SAFIM(Syntax-Aware Fill-in-the-Middle)是一项针对大型语言模型(LLMs)在代码填充任务中的评估基准。该数据集由来自2022年4月至2023年1月期间提交的代码构成,以降低数据污染对评估结果的影响。其主要研究人员包括Linyuan Gong、Sida Wang、Mostafa Elhoushi和Alvin Cheung,研究成果已发布于arXiv。SAFIM数据集针对代码的算法块完成、控制流表达式完成以及API函数调用完成三个子任务,旨在为相关领域的研究提供标准和参考。
当前挑战
在领域问题上,SAFIM数据集面临的挑战包括如何精确地评估LLMs在理解代码结构和逻辑方面的能力。在构建过程中,数据集的挑战主要体现在如何从大量代码中提取具有代表性的片段,并确保这些片段对于模型训练和评估的有效性和公正性。此外,由于数据源自Codeforces,还需在数据使用和引用上遵守相应的版权规定。
常用场景
经典使用场景
在大型语言模型评估领域,SAFIM数据集以其独特的 Fill-in-the-Middle 任务,成为检验模型算法块完成、控制流表达式完成以及API函数调用完成能力的重要基准。该数据集通过提供半自动生成的代码片段,为模型训练和评估提供了标准化环境。
解决学术问题
SAFIM数据集针对大型语言模型在代码理解与生成方面的局限性,提供了专门的评测任务,有助于学术界识别和解决模型在处理代码逻辑填充、算法实现细节上的不足,推动了对模型生成能力深层次的理解与提升。
衍生相关工作
基于SAFIM数据集,研究者们已经开展了一系列相关工作,包括但不限于对现有模型的改进、新型代码生成模型的探索,以及针对特定编程语言或领域的定制化评测任务,这些工作进一步扩展了SAFIM的应用范围和影响力。
以上内容由遇见数据集搜集并总结生成


