astro-llms-full-query-data
收藏Hugging Face2025-07-16 更新2025-07-17 收录
下载链接:
https://huggingface.co/datasets/jhu-clsp/astro-llms-full-query-data
下载链接
链接失效反馈官方服务:
资源简介:
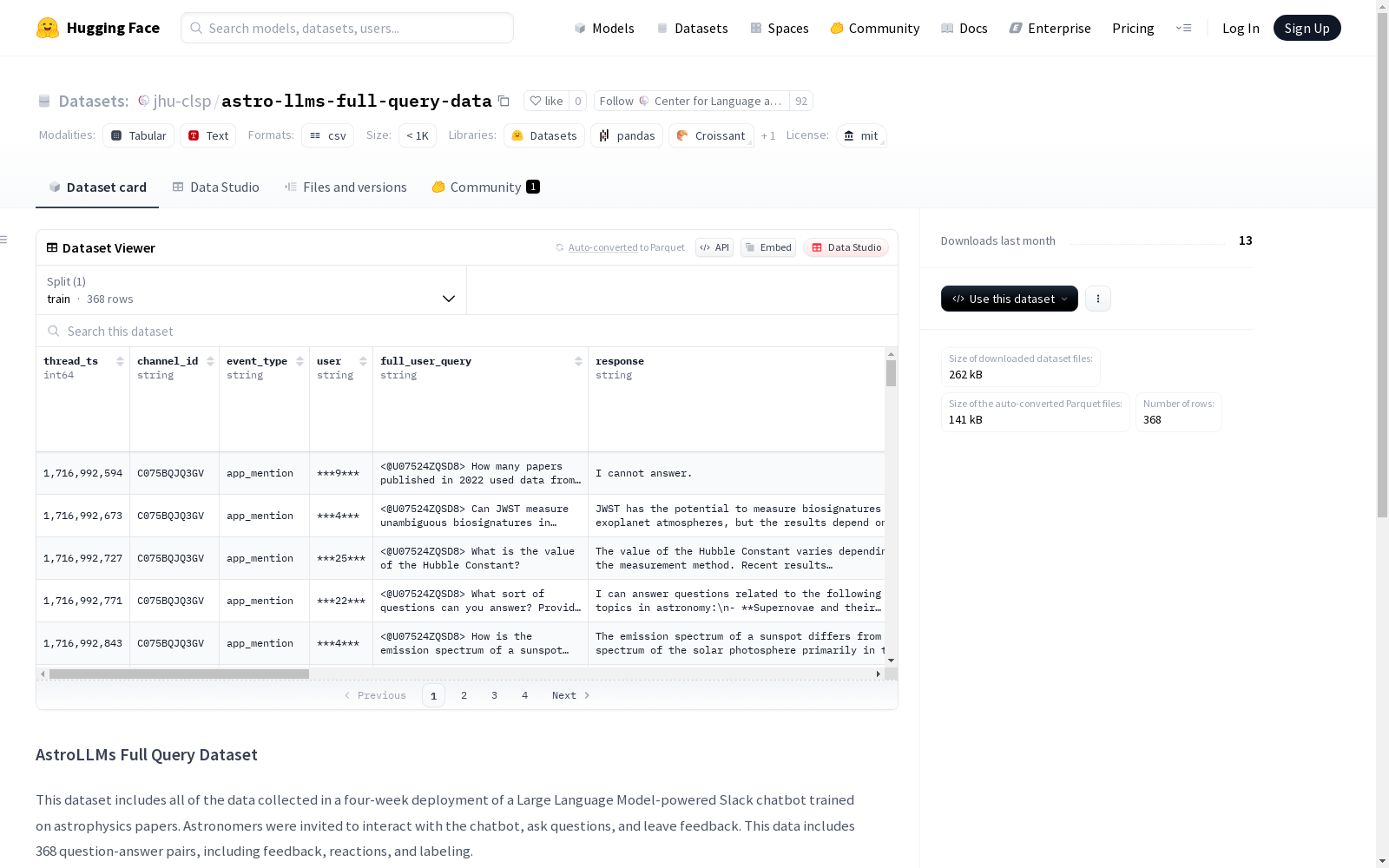
AstroLLMs完整查询数据集包含了一个在四周部署期间收集的、基于大型语言模型的天体物理论文训练的Slack聊天机器人的所有互动数据。数据集中包括368个问题-答案对,涵盖反馈、反应和研究人员创建的分类标签。
创建时间:
2025-07-16
原始信息汇总
AstroLLMs Full Query Dataset 概述
数据集基本信息
- 许可证: MIT
- 数据内容: 包含在一个为期四周的天体物理学论文训练的Slack聊天机器人部署中收集的所有数据
- 数据规模: 368个问答对
- 数据组成: 包括问题-答案对、反馈、反应和标签
数据集结构
- thread_ts: 查询的唯一时间戳
- channel_id: 表示查询是在私有还是公共频道中提出
- event_type: 查询提出方式(私有频道直接提问或群组空间消息)
- user: 提问者的匿名标识符
- full_user_query: 聊天机器人的响应
- answer_ts: 聊天机器人响应的唯一时间戳
- thumbs_up: 对聊天机器人响应的点赞反应数量
- thumbs_down: 对聊天机器人响应的点踩反应数量
- other_reactions: 对聊天机器人响应的其他表情反应
- feedback: 用户对聊天机器人响应的回复(通常包含反馈)
- open coding: 研究人员创建的查询类型标签
- re-asks previous: 二进制指示符(表示查询是否重新提出上一个查询)
- 其他列: 记录标注者将查询标记为每个开放编码类别的百分比
引用信息
- 论文标题: "From Queries to Criteria: Understanding How Astronomers Evaluate LLMs"
- 作者: Hyk, A., McCormick, K., Zhong, M., Ciucă, I., Sharma, S., Wu, J. F., Peek, J. E. G., Iyer, K. G., Xiao, Z., & Field, A.
- 会议: Conference on Language Modeling, 2025
搜集汇总
数据集介绍
构建方式
在当今人工智能与天文学交叉研究蓬勃发展的背景下,AstroLLMs Full Query Dataset通过为期四周的实地部署实验完成构建。研究团队设计了一个基于大型语言模型的Slack聊天机器人,该模型经过天体物理学论文的专业训练。通过邀请天文学家与机器人互动提问并收集反馈,最终形成368组包含问题-答案对、用户反馈、表情反应及人工标注的完整数据链。数据采集过程严格遵循匿名化原则,每个交互线程均通过时间戳和频道ID实现精准溯源。
特点
作为天文学领域首个基于真实交互场景构建的语言模型评估数据集,其核心价值体现在多维度的标注体系上。除基础的问题-响应配对外,数据集创新性地整合了用户表情反馈(点赞/点踩)、文字评价、问题重述标记等社交维度数据。特别值得注意的是,研究者采用开放式编码对问题类型进行系统分类,并通过多标注者一致性验证确保标签可靠性。这种融合技术交互与社交反馈的双重特性,为研究语言模型在专业领域的适用性提供了独特视角。
使用方法
该数据集为探索专业领域语言模型的性能评估提供了标准化研究框架。使用者可通过线程时间戳实现问题-响应的精确匹配,利用频道类型字段区分公私场景下的模型表现差异。开放式编码分类支持研究者从主题维度分析模型的知识盲区,而表情反馈与文字评价数据则为构建细粒度的质量评估指标奠定基础。对于天文学与AI交叉研究,建议结合论文中提出的评估标准体系,重点考察模型在专业术语理解、逻辑推理准确性等方面的表现。
背景与挑战
背景概述
AstroLLMs全查询数据集诞生于天体物理学与人工智能交叉研究的前沿领域,由Hyk等学者于2025年构建。该数据集源自为期四周的天体物理学专用大型语言模型Slack聊天机器人实测项目,收录了368组天文学家与AI系统的交互数据,包括问题-答案对、用户反馈及情感反应标注。作为天文领域首个公开的LLM人机对话语料库,其核心价值在于揭示了专业科研群体对AI助手的真实需求模式,为优化领域专用语言模型提供了关键的行为基准。数据集通过多维度标注体系,包括查询类型开放编码、重复提问标识及用户情感反馈,为后续研究建立了可量化的评估框架。
当前挑战
该数据集面临双重挑战:在领域问题层面,如何准确捕捉天文学家复杂的研究需求与专业术语表达,传统通用型语言模型难以理解高度专业化的天体物理概念层级结构;在构建过程中,需解决专业标注一致性难题,不同天文学家对查询意图的分类存在主观差异,且用户反馈存在稀疏性与模糊性。技术挑战还包括实时对话场景下的多模态数据处理,需同步整合时间戳、情感反应符号与文本反馈等多源异构数据,这对数据清洗与对齐提出较高要求。
常用场景
经典使用场景
在自然语言处理与天文学交叉领域的研究中,AstroLLMs Full Query Dataset为探索大型语言模型在天文学专业问答场景中的表现提供了宝贵资源。该数据集记录了天文学家与基于天体物理学论文训练的聊天机器人之间的真实交互,包含368组问答对及用户反馈,为研究者分析专业领域对话系统的理解能力、生成质量及用户满意度提供了实证基础。
实际应用
在实际应用中,该数据集支撑了天文教育辅助系统的开发优化。教育机构可基于真实天文学家的查询模式,训练具备专业领域知识的智能助教系统。科研团队则利用反馈数据改进对话系统的解释性生成能力,使其在望远镜观测方案咨询、文献概念解析等场景中提供更精准的专业支持。
衍生相关工作
该数据集已催生多项关于专业领域语言模型评估的重要研究。原始论文提出的多维度标注体系被扩展应用于高能物理、气候科学等垂直领域。后续工作基于其反馈机制开发了动态学习框架,部分研究则利用重问行为数据构建了对话连贯性评估指标,形成了领域专用对话系统评估的标准方法论。
以上内容由遇见数据集搜集并总结生成


