WikiRAG-TR
收藏Hugging Face2024-08-06 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/Metin/WikiRAG-TR
下载链接
链接失效反馈官方服务:
资源简介:
WikiRAG-TR是一个包含5999个问题和答案对的数据集,这些对是从土耳其语维基百科文章的引言部分合成生成的。数据集主要用于土耳其语的检索增强生成(RAG)任务。数据集的创建分为两个阶段:第一阶段收集子类别,第二阶段生成数据集。数据集包含多个列,如ID、问题、答案、上下文等。数据集的答案通常简短,可能存在维基百科文章中的偏见和不准确性。
创建时间:
2024-08-05
原始信息汇总
数据集概述
WikiRAG-TR 是一个包含 6K(5999 对)问题和答案的数据集,这些数据是从土耳其维基百科文章的介绍部分合成创建的。该数据集旨在用于土耳其检索增强生成(RAG)任务。
数据集信息
- 实例数量: 5999(5725 对合成生成的问题-答案对,274 个增强的负样本)
- 数据集大小: 20.5 MB
- 语言: 土耳其语
- 数据集许可证: apache-2.0
- 数据集类别: 文本生成
- 数据集领域: 自然科学和社会科学
数据集创建流程
数据集的创建分为两个主要阶段:
第一阶段:子类别收集
- 确定了一个精选的种子类别列表,包括科学、技术、工程、数学、物理、化学、生物、地质、气象学、历史、社会科学等。
- 使用这些种子类别,从维基百科递归收集子类别。
- 递归深度设置为 3,每个深度层的子类别数量限制为 100。
- 在每个步骤中,过滤掉以下类型的子类别:
- 包含NSFW 词汇的子类别。
- 仅包含项目列表的子类别。
- 用作模板的子类别。
- 从最终的子类别列表中获取文章。
第二阶段:数据集生成
- 从第一阶段收集的文章中提取介绍部分。
- 如果介绍部分太短或太长(少于 50 或超过 2500 个字符),则丢弃该文章。
- 如果介绍部分包含NSFW 词汇,则丢弃该文章。
- 如果介绍部分包含方程式,则丢弃该文章。
- 如果介绍部分为空,则丢弃该文章。
- 将过滤后的介绍部分输入大型语言模型
(Gemma-2-27B-it)生成合成的问题和答案对。 - 对于数据集中的每一行(包含介绍、问题和答案),执行以下操作:
- 从其他行收集不相关的上下文,以添加错误的正向检索到上下文中。
- 将这些不相关的上下文附加到一个列表中。
- 将相关上下文添加到此列表中。(在某些情况下,省略相关上下文以创建负样本,其中答案表示模型由于信息不足而无法回答问题。这些负样本是单独创建的,确保所有原始问题都有相应的答案。)
- 打乱列表以随机化相关上下文的位置。
- 使用 字符连接列表元素。
使用数据集的注意事项
生成的答案通常简短且简洁,这可能导致在此数据集上训练的模型生成简短的答案。由于数据集是使用维基百科文章创建的,因此维基百科文章中存在的任何偏见和不准确性也可能存在于此数据集中。
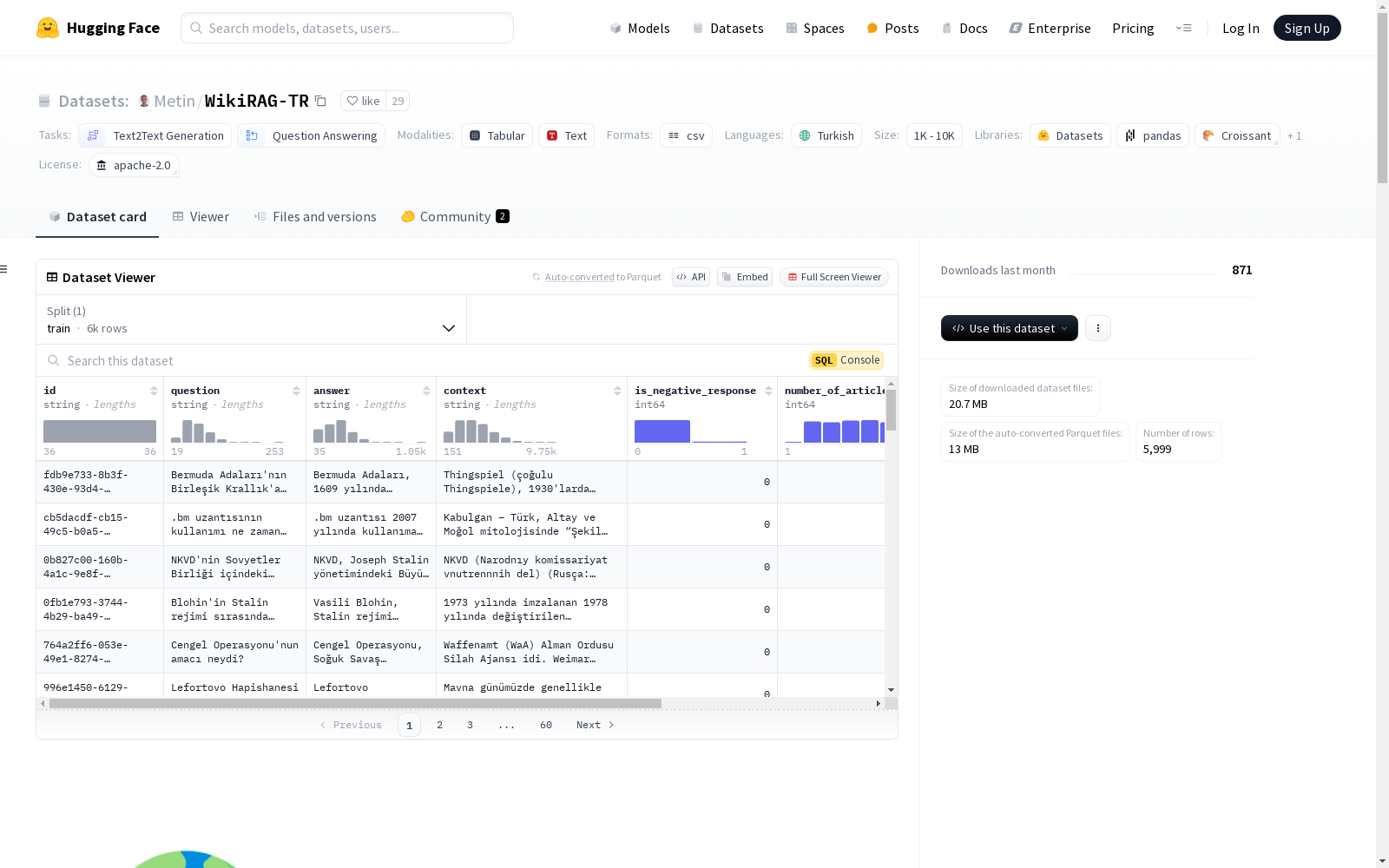
数据集列
id: 每行的唯一标识符。question: 模型生成的问题。answer: 模型生成的答案。context: 包含相关和不相关信息的增强上下文。is_negative_response: 指示答案是否为负响应(0: 否,1: 是)。number_of_articles: 用于创建上下文的文章介绍数量。
搜集汇总
数据集介绍
构建方式
WikiRAG-TR数据集的构建过程分为两个主要阶段。首先,通过递归方式从土耳其语维基百科的种子类别中收集子类别,并过滤掉包含不适当内容、仅包含列表或模板的子类别。随后,从这些子类别中提取文章的介绍部分,并进一步筛选掉过短、过长、包含不适当内容或公式的介绍。接着,使用大型语言模型(Gemma-2-27B-it)生成合成的问题-答案对,并通过添加无关上下文和随机化相关上下文的位置来增强数据集的复杂性。最后,生成的数据集包含5999个问题-答案对,其中包含5725个合成生成的正样本和274个增强的负样本。
特点
WikiRAG-TR数据集包含5999个土耳其语的问题-答案对,涵盖了科学、技术、工程、数学、物理、化学、生物、地质、气象、历史和社会科学等多个领域。数据集的特点在于其问题-答案对是通过大型语言模型从维基百科文章的介绍部分生成的,且每个问题都伴随着一个包含相关和无关信息的上下文。此外,数据集还包含负样本,用于模拟模型在信息不足时无法回答问题的情况。这些特点使得WikiRAG-TR特别适用于土耳其语检索增强生成(RAG)任务的研究和开发。
使用方法
WikiRAG-TR数据集可用于训练和评估土耳其语检索增强生成(RAG)模型。使用时,研究人员可以通过`context`列中的上下文信息来训练模型如何从混合的相关和无关信息中提取正确答案。`is_negative_response`列可用于评估模型在信息不足时的表现。此外,`ctx_split_points`和`correct_intro_idx`列可用于进一步分析模型在处理复杂上下文时的性能。由于数据集中的答案通常简洁明了,研究人员应注意模型可能倾向于生成简短的回答。
背景与挑战
背景概述
WikiRAG-TR数据集是一个包含5999个问答对的土耳其语数据集,专门为土耳其语检索增强生成(RAG)任务设计。该数据集基于土耳其语维基百科文章的介绍部分,通过合成方式生成。数据集的主要研究人员或机构未明确提及,但其创建时间可推测为近期,基于其使用的先进语言模型Gemma-2-27B-it。该数据集的核心研究问题在于如何有效利用维基百科内容进行问答生成,特别是在STEM和社会科学领域。WikiRAG-TR的发布为土耳其语自然语言处理领域提供了重要的资源,推动了该领域的研究和应用发展。
当前挑战
WikiRAG-TR数据集在构建过程中面临多重挑战。首先,数据集的生成依赖于维基百科文章,因此不可避免地继承了维基百科中可能存在的偏见和不准确性。其次,合成问答对的生成过程需要确保问题的多样性和答案的准确性,这对语言模型的能力提出了较高要求。此外,数据集中包含的负样本(即无法回答的问题)的生成也需要精心设计,以确保模型能够正确处理信息不足的情况。最后,数据集的上下文信息需要包含相关和不相关内容,以模拟真实场景中的检索过程,这对数据集的构建和后续模型的训练都提出了挑战。
常用场景
经典使用场景
WikiRAG-TR数据集主要用于土耳其语的检索增强生成(RAG)任务。该数据集通过从土耳其语维基百科文章的引言部分生成合成的问题-答案对,为研究人员提供了一个标准化的测试平台,用于评估和改进土耳其语自然语言处理模型在问答任务中的表现。特别是在处理多文档检索和生成任务时,WikiRAG-TR能够帮助模型更好地理解上下文并生成准确的答案。
衍生相关工作
基于WikiRAG-TR数据集,研究人员已经开展了一系列相关研究。例如,一些工作专注于改进土耳其语RAG模型的上下文理解能力,通过引入更复杂的负样本生成策略和上下文随机化技术。此外,该数据集还被用于探索跨语言迁移学习,特别是在低资源语言环境中,如何利用高资源语言的数据集提升土耳其语模型的性能。这些研究不仅推动了土耳其语自然语言处理技术的发展,也为其他低资源语言的研究提供了宝贵的经验。
数据集最近研究
最新研究方向
近年来,随着自然语言处理技术的飞速发展,基于检索增强生成(Retrieval-Augmented Generation, RAG)的任务逐渐成为研究热点。WikiRAG-TR数据集作为土耳其语领域的首个RAG任务专用数据集,填补了该语言在问答系统与文本生成任务中的空白。该数据集通过从土耳其语维基百科文章中提取引言部分,并利用大语言模型生成合成问答对,为土耳其语RAG模型的训练与评估提供了重要资源。当前研究主要集中在如何利用该数据集优化多语言RAG模型的性能,特别是在跨语言迁移学习与低资源语言处理中的应用。此外,研究者们还关注如何通过引入负样本增强模型的鲁棒性,以应对信息不完整或无关上下文带来的挑战。WikiRAG-TR的发布不仅推动了土耳其语自然语言处理技术的发展,也为其他低资源语言的RAG任务研究提供了宝贵的参考。
以上内容由遇见数据集搜集并总结生成


