DIFFUSIONDB
收藏arXiv2023-07-06 更新2024-06-21 收录
下载链接:
https://poloclub.github.io/diffusiondb
下载链接
链接失效反馈官方服务:
资源简介:
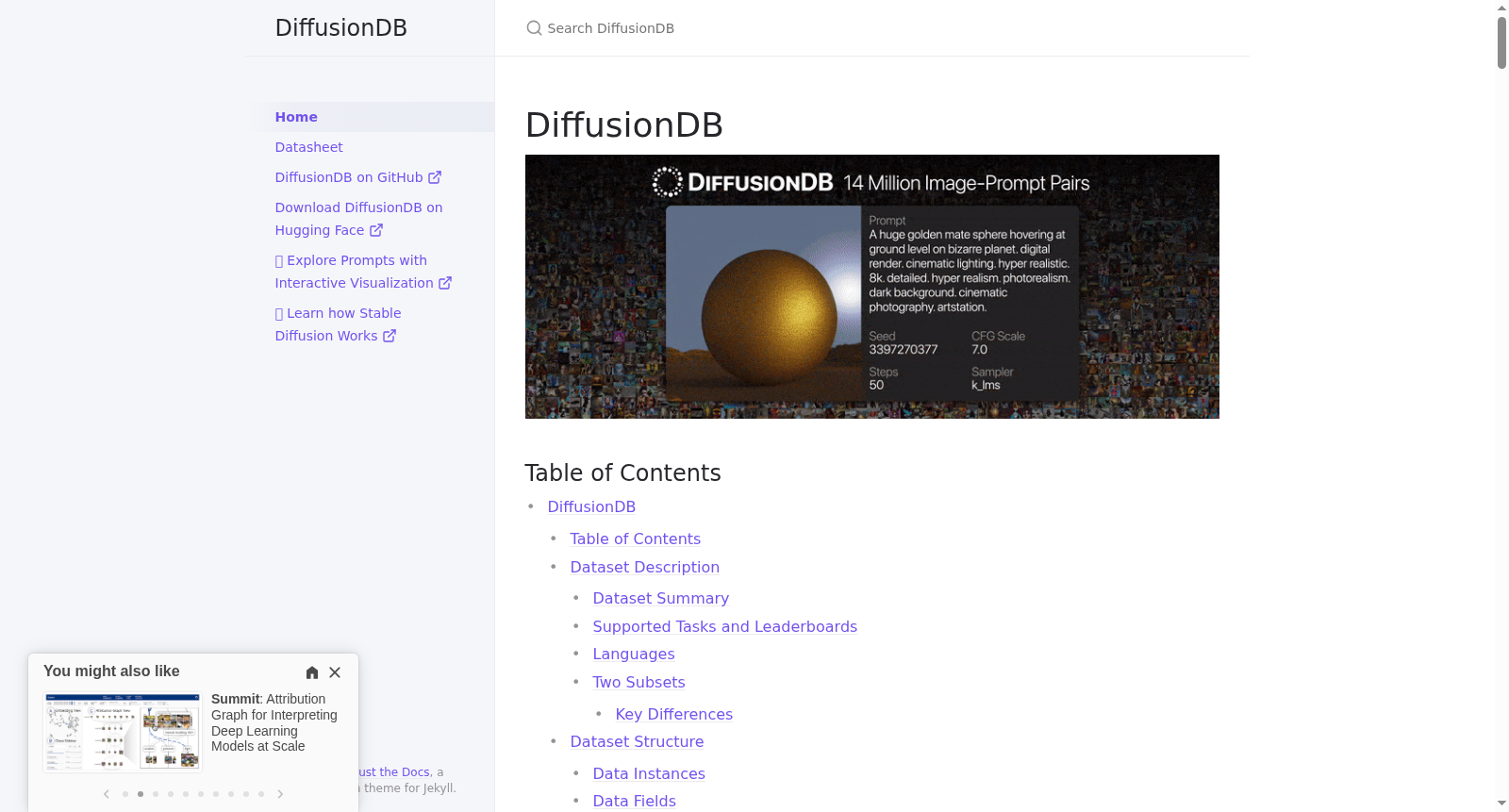
DIFFUSIONDB是由佐治亚理工学院创建的第一个大规模文本到图像提示数据集,总容量达6.5TB,包含1400万张由Stable Diffusion生成的图像和180万个独特提示,以及由真实用户指定的超参数。该数据集通过收集Stable Diffusion公共Discord服务器上的图像构建,旨在帮助研究人员理解提示与生成模型之间的交互,检测深度伪造,并设计人机交互工具以更轻松地使用这些模型。DIFFUSIONDB的应用领域包括提示工程、深度伪造检测和大型生成模型的理解。
DIFFUSIONDB is the first large-scale text-to-image prompt dataset developed by the Georgia Institute of Technology. With a total capacity of 6.5 TB, it contains 14 million images generated by Stable Diffusion, 1.8 million unique prompts, and hyperparameters specified by real users. This dataset is curated by collecting images from public Stable Diffusion Discord servers, and its core objectives are to help researchers comprehend the interaction between prompts and generative models, detect deepfakes, and develop human-computer interaction tools to facilitate easier utilization of these models. The application areas of DIFFUSIONDB cover prompt engineering, deepfake detection, and the understanding of large generative models.
提供机构:
佐治亚理工学院
创建时间:
2022-10-27
搜集汇总
数据集介绍
构建方式
在扩散模型迅速发展的背景下,DIFFUSIONDB的构建过程体现了对大规模、真实用户生成数据的系统性采集与整理。研究团队通过DiscordChatExporter工具从Stable Diffusion官方Discord服务器的指定频道中,采集了用户通过指令生成的图像及其对应的聊天记录。随后利用Beautiful Soup解析HTML文件,将每张生成图像与其提示词、超参数(如种子值、CFG尺度、采样器、步数等)、时间戳以及请求者的匿名化用户名哈希进行精确关联。对于以拼贴形式返回的图像,团队使用Pillow库将其分割为独立图像,并为每个图像分配唯一的文件名和元数据。为协助研究者过滤潜在不安全内容,数据集还集成了先进的NSFW分类器,为每对提示词和图像计算了安全评分,并以灵活的模块化文件结构和Apache Parquet格式进行组织,确保了数据的高效访问与使用。
使用方法
DIFFUSIONDB为多个前沿研究方向提供了基础数据支持。在提示词工程领域,研究者可利用其海量提示词-图像对,开发自动补全系统或研究有效提示词的构成模式,以辅助用户更高效地构思提示。对于生成模型的可解释性研究,数据集中大量仅存在细微差异的提示词及其对应图像,使得分析特定关键词对生成结果的影响成为可能。在深度伪造检测方面,该数据集包含的大规模模型生成图像及其元数据,可用于训练模型以识别合成图像的特征。此外,研究者还可基于数据构建语义-视觉索引,实现通过搜索已有图像而非重新生成来快速获取结果,或通过分析生成失败案例及用户偏好数据,为改进下一代生成模型及交互工具提供实证依据。
背景与挑战
背景概述
随着扩散模型技术的突破,文本到图像生成模型能够依据自然语言描述创作出高质量图像,引发了艺术创作、医学成像等领域的广泛应用。然而,生成符合预期细节的图像高度依赖于提示词的精准构造,这一过程往往缺乏系统性的指导原则。为应对这一核心挑战,佐治亚理工学院的研究团队于2022年发布了DIFFUSIONDB,这是首个大规模文本到图像提示词数据集,其规模达6.5TB,包含由Stable Diffusion生成的1400万张图像、180万条独特提示词及相关超参数。该数据集旨在为研究人员探究提示词与生成模型之间的交互机制、设计高效的人机交互工具提供关键资源,推动了提示工程、深度伪造检测等新兴研究方向的发展。
当前挑战
DIFFUSIONDB致力于解决文本到图像生成领域中的核心挑战,即如何系统理解与优化提示词以精确控制生成内容。具体而言,该领域面临模型对提示词语义响应机制不透明、有效提示词构造缺乏理论指导等难题。在数据集构建过程中,研究者需应对多重挑战:首先,从Discord平台海量对话中准确提取并关联图像、提示词及超参数,涉及复杂的数据解析与清洗流程;其次,尽管平台设有内容审核机制,数据集中仍不可避免地包含未被过滤的NSFW(不适宜工作场合)内容,需借助先进分类器进行识别与标注以降低潜在危害;此外,数据源集中于早期AI艺术爱好者群体,可能导致提示词风格分布存在偏差,影响数据集的普遍代表性。
常用场景
经典使用场景
在文本到图像生成模型的快速发展背景下,DIFFUSIONDB作为首个大规模提示词库数据集,其经典使用场景集中于提示工程研究。该数据集通过整合1400万张由真实用户生成的图像及其对应的180万条独特提示词,为研究者提供了分析提示词语法结构、语义特征与生成图像质量之间关联的宝贵资源。研究人员能够深入探索不同提示词风格对模型输出的影响,识别高效提示词的构成模式,从而系统性地构建提示词设计的最佳实践框架。
解决学术问题
该数据集有效解决了文本到图像生成领域若干关键学术问题,包括提示词与模型响应机制的量化分析、生成模型失败案例的归因研究以及多语言提示词的有效性评估。通过提供海量真实用户数据,DIFFUSIONDB使得研究者能够首次大规模验证提示工程理论假设,识别导致图像失真的超参数配置,并揭示模型在生成非英语内容时的局限性。这些研究成果为改进生成模型的鲁棒性、开发自适应提示系统奠定了实证基础。
实际应用
在实际应用层面,DIFFUSIONDB为人工智能辅助创作工具的开发提供了核心数据支持。基于该数据集训练的提示词自动补全系统能够帮助用户快速构建有效提示,显著降低使用门槛。同时,其构建的图像-提示词检索系统可直接应用于创意产业,设计师通过语义搜索即可获取特定风格的参考图像。在内容安全领域,该数据集包含的NSFW检测标签为开发深度伪造识别算法提供了关键训练数据。
数据集最近研究
最新研究方向
在文本到图像生成模型快速发展的背景下,DIFFUSIONDB作为首个大规模提示词-图像配对数据集,为前沿研究开辟了多维路径。其核心方向聚焦于提示词工程的系统化探索,通过分析海量真实用户数据,揭示特定提示词模式、超参数设置与生成结果之间的复杂关联,为优化模型交互提供实证基础。该数据集亦成为深度伪造检测的关键资源,助力开发更鲁棒的合成图像识别算法。同时,其蕴含的潜在有害内容为研究生成模型的伦理边界与社会影响提供了重要案例,推动建立更安全的模型使用规范。
相关研究论文
- 1DiffusionDB: A Large-scale Prompt Gallery Dataset for Text-to-Image Generative Models佐治亚理工学院 · 2023年
以上内容由遇见数据集搜集并总结生成


