GT23D-Bench
收藏arXiv2024-12-13 更新2024-12-17 收录
下载链接:
https://gt23d-bench.github.io/
下载链接
链接失效反馈官方服务:
资源简介:
GT23D-Bench是由中国电子科技大学创建的一个全面的通用文本到3D生成基准数据集。该数据集包含40万条高质量、多模态标注的3D数据,涵盖64个视图的深度图、法线图、渲染图像和粗细粒度描述。数据集通过系统的标注、组织和过滤流程,解决了Objaverse数据集的标注缺失、组织混乱和低质量问题。GT23D-Bench主要应用于文本到3D生成任务,旨在通过多模态标注和全面的3D感知评估指标,推动该领域的系统性评估和方法进步。
GT23D-Bench is a comprehensive general-purpose text-to-3D generation benchmark dataset developed by the University of Electronic Science and Technology of China. This dataset contains 400,000 high-quality, multi-modal annotated 3D samples, covering depth maps, normal maps, rendered images and coarse-to-fine granularity descriptions across 64 views. Through systematic annotation, organization and filtering pipelines, it addresses the issues of missing annotations, disorganized structure and low data quality in the Objaverse dataset. Primarily applied to text-to-3D generation tasks, GT23D-Bench aims to promote systematic evaluation and methodological advancement in this field via multi-modal annotations and comprehensive 3D perception evaluation metrics.
提供机构:
中国电子科技大学(UESTC)
创建时间:
2024-12-13
原始信息汇总
GT23D-Bench 数据集概述
数据集简介
GT23D-Bench 是一个综合的 General Text-to-3D (GT23D) 生成基准,旨在解决现有 3D 数据集和评估指标的不足。该基准包括一个高质量、组织良好的 3D 数据集和一个全面的 3D 感知评估指标体系。
数据集特点
- 多模态标注:每个 3D 对象都标注了 64 视图的深度图、法线图、渲染图像以及从粗到细的描述。
- 全面的评估维度:
- 文本-3D 对齐:评估文本与多粒度视觉 3D 表示的对齐情况。
- 3D 视觉质量:考虑纹理保真度、多视图一致性和几何正确性。
- 有价值的见解:对当前 GT23D 基线在不同评估维度上的表现进行了深入分析。
数据集详情
- 数据集规模:包含 400k 个高保真、组织良好的 3D 对象。
- 标注方式:从粗到细的描述,与其他现有数据集相比,提供了更全面的标注。
- 数据过滤:通过系统化的标注-组织过滤管道,解决了 Objaverse 数据集中的标注缺失、组织混乱和低质量问题。
评估指标
- 多维度评估:包含 10 个明确的评估指标,涵盖了 GT23D 的多维度特性。
- 实验结果:通过广泛的实验,验证了标注和指标与人类偏好的对齐性。
数据集展示
- RGB 展示:展示了多个 3D 对象的 RGB 图像。
- 深度展示:展示了多个 3D 对象的深度图像。
相关资源
搜集汇总
数据集介绍
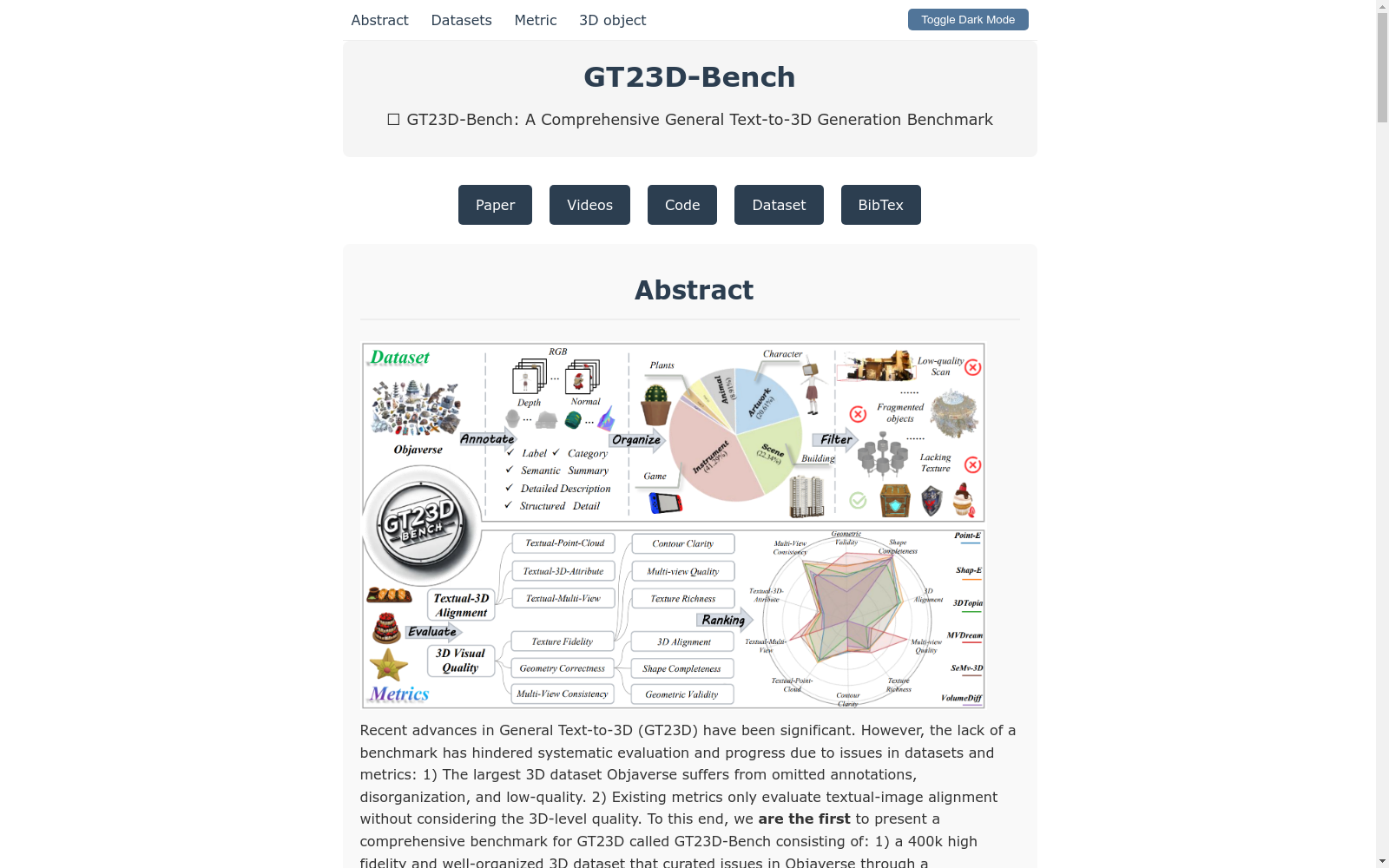
构建方式
GT23D-Bench数据集通过系统化的标注、组织和过滤流程构建,旨在解决现有3D数据集(如Objaverse)中存在的标注缺失、组织混乱和低质量问题。首先,通过多模态标注阶段,为每个3D对象添加了64视图的深度图、法线图、渲染图像以及粗细结合的描述性标注。其次,在标签组织阶段,通过纠正标签错位和语义重叠问题,将3D对象分类为七个主要类别,并进一步细分为子类别。最后,在质量过滤阶段,通过检测碎片化形状、无意义3D模型和渲染失败等问题,确保数据集的高质量。
特点
GT23D-Bench数据集具有三大显著特点:首先,多模态标注,每个3D对象都附带了丰富的视觉和文本信息,包括深度图、法线图、渲染图像和多层次的描述性标注;其次,全面的评估维度,涵盖了文本与3D模型的对齐度以及3D模型的视觉质量,具体包括纹理保真度、几何正确性和多视图一致性;最后,提供了对当前文本到3D生成方法的深入分析,帮助研究者更好地理解模型的性能。
使用方法
GT23D-Bench数据集可用于训练和评估文本到3D生成模型。研究者可以使用该数据集进行模型的训练,利用其丰富的多模态标注和高质量的3D对象来提升模型的生成能力。此外,数据集还提供了全面的3D感知评估指标,研究者可以通过这些指标对模型的生成结果进行多维度的评估,包括文本与3D模型的对齐度、纹理质量、几何正确性等,从而更好地优化和改进模型。
背景与挑战
背景概述
GT23D-Bench是由电子科技大学(UESTC)和同济大学联合开发的一个综合性的通用文本到3D生成基准数据集。该数据集的创建旨在解决当前文本到3D生成领域中缺乏系统评估工具的问题。GT23D-Bench包含两个主要部分:一个经过多模态注释、标签组织和严格筛选的40万高质量3D数据集,以及一套全面的3D感知评估指标。该数据集通过系统化的注释、组织和过滤流程,解决了现有数据集(如Objaverse)中存在的注释缺失、标签混乱和低质量3D模型等问题。GT23D-Bench的推出标志着文本到3D生成领域的一个重要里程碑,为该领域的研究提供了标准化的评估工具和高质量的数据支持。
当前挑战
GT23D-Bench的构建面临多个挑战。首先,现有的3D数据集(如Objaverse)存在注释缺失、标签混乱和低质量模型等问题,这使得数据集的组织和筛选变得复杂。其次,现有的评估指标主要集中在2D层面的语义对齐,而忽略了3D模型的几何正确性和多视角一致性等关键问题。GT23D-Bench通过引入多模态注释和3D感知评估指标,解决了这些挑战。然而,如何确保注释的准确性和一致性,以及如何设计有效的3D感知评估指标,仍然是该领域面临的重大挑战。此外,随着文本到3D生成技术的快速发展,如何持续更新和扩展数据集以适应新的研究需求也是一个重要的课题。
常用场景
经典使用场景
GT23D-Bench 数据集的经典使用场景主要集中在文本到三维(Text-to-3D)生成任务的评估与优化。该数据集通过提供高质量的多模态标注数据和全面的评估指标,帮助研究者系统地评估和改进文本生成三维模型的性能。其核心应用包括对现有文本到三维生成模型的基准测试、模型训练中的数据增强,以及探索不同文本描述与三维模型之间的对齐关系。
实际应用
GT23D-Bench 数据集在实际应用中具有广泛的应用前景,特别是在虚拟现实、游戏开发和产品设计等领域。例如,在虚拟现实中,该数据集可以帮助生成符合用户描述的三维场景或物体,提升用户体验;在游戏开发中,开发者可以利用该数据集快速生成符合文本描述的游戏角色或道具;在产品设计中,设计师可以通过文本描述生成三维模型,加速设计流程并减少成本。
衍生相关工作
GT23D-Bench 数据集的发布催生了一系列相关研究工作。首先,基于该数据集的评估指标,研究者们提出了多种改进的文本到三维生成模型,如 MVDream 和 Shap-E,这些模型在生成质量和多视图一致性上取得了显著进展。其次,该数据集的多模态标注方法启发了其他研究者在三维数据集标注领域的创新,推动了三维数据集质量的提升。此外,GT23D-Bench 的评估框架也被广泛应用于其他生成任务的评估,如文本到视频生成,进一步扩展了其影响力。
以上内容由遇见数据集搜集并总结生成


