parrot
收藏数据集卡片 PARROT
数据集描述
PARROT(Performance Assessment of Reasoning and Responses on Trivia)是一个用于评估大型语言模型(LLM)性能的基准数据集。该数据集利用游戏节目数据,通过开放式和封闭式问题格式,提供了对LLM的更真实评估。数据集由Redblock精心策划,源自流行的游戏节目《危险边缘》(Jeopardy)和《谁想成为百万富翁》(Who Wants to Be a Millionaire)。
数据集组成
- PARROT-Jeopardy:包含《危险边缘》游戏节目中的问题,特点是问题简短,用于测试推理和歧义处理能力。
- PARROT-Millionaire:包含《谁想成为百万富翁》游戏节目中的问题,以其直接性和广泛的话题范围而闻名,用于评估LLM的知识。
数据集信息
- 创建者: Redblock
- 共享者: Redblock
- 许可证: cc-by-4.0
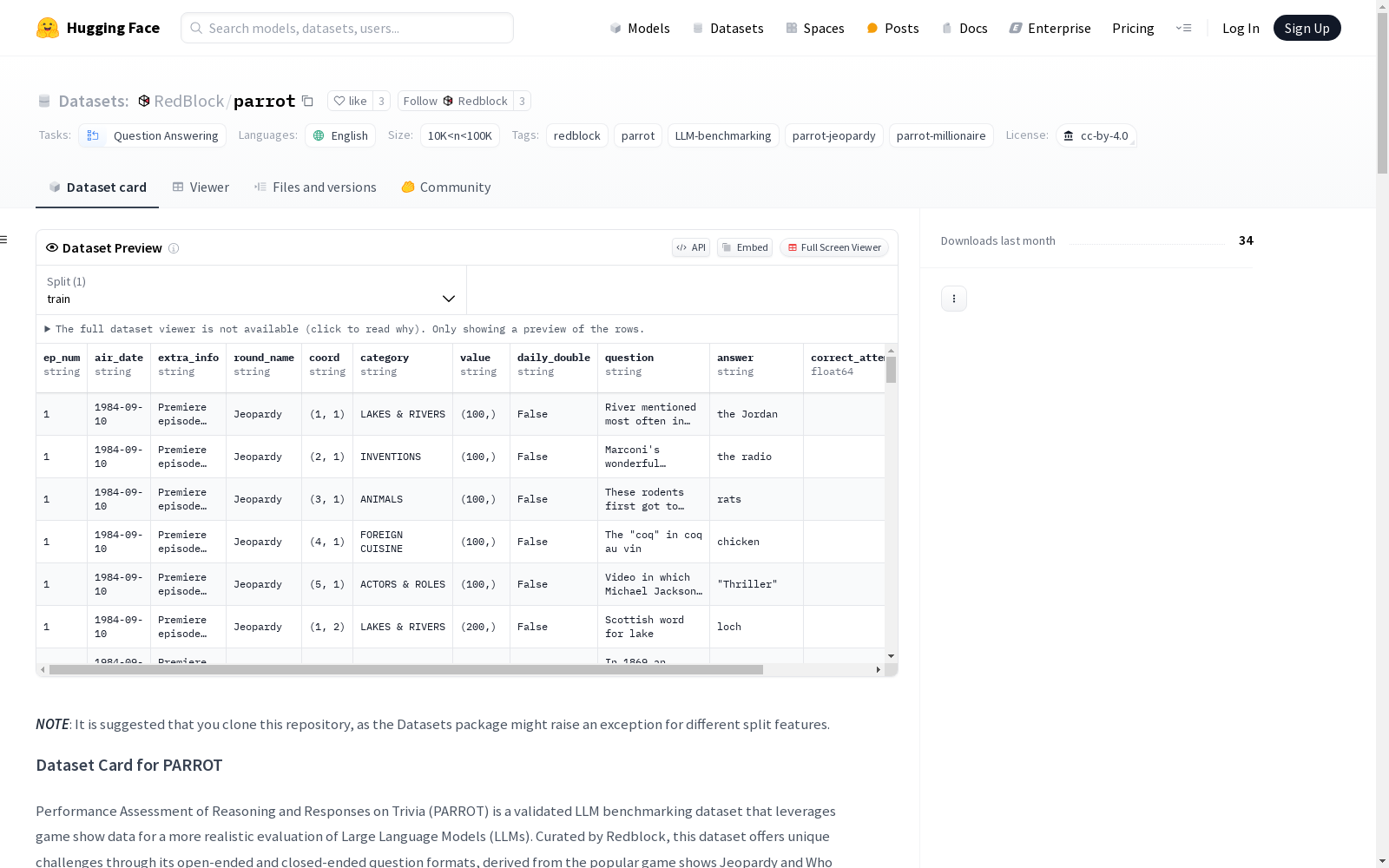
数据集结构
PARROT-Jeopardy
- ep_num:季的集数。
- air_date:节目播出日期。
- extra_info:包括主持人的名字等额外信息。
- round_name:进行的轮次(例如,Jeopardy、Double Jeopardy、Final Jeopardy)。
- coord:线索在游戏板上的坐标。
- category:线索类别。
- value:线索的货币价值。
- daily_double:布尔值,指示线索是否属于每日双倍轮。
- question:线索本身。
- answer:标记的答案或猜测。
- correct_attempts:正确回答的参赛者数量。
- wrong_attempts:错误回答的参赛者数量。
PARROT-Millionaire
- question_info:描述价格值和当前问题编号。
- question:文本形式的问题。
- options:与问题对应的四个预定义选项。
- correct_answer:标记的正确答案。
- price:从问题信息中提取的特征,表示问题的美元价值。
- normalized_options:对选项进行文本规范化的特征。
- normalized_correct_opt:对正确答案进行文本规范化的特征。
数据集创建
创建理由
PARROT的创建是为了满足对LLM更真实和更具挑战性的基准测试数据集的需求。通过使用游戏节目数据,该数据集捕捉了广泛的问题类型和难度,提供了一个全面的评估工具。
源数据
数据收集和处理
- PARROT-Jeopardy:从《危险边缘》游戏节目的七个关键季中精心策划,确保了节目时间线上的代表性样本。数据从J!Archive(一个包含超过500,000个线索的粉丝创建的档案)中抓取。
- PARROT-Millionaire:从Millionaire Fandom网站抓取数据,并进行组织和处理以确保一致性和可靠性。
源数据生产者
PARROT-Jeopardy的原始数据来自《危险边缘》游戏节目的粉丝创建的档案,而PARROT-Millionaire的数据来自Millionaire Fandom网站。
个人和敏感信息
该数据集不包含个人、敏感或私人信息。
引用
BibTeX: bibtex @dataset{parrot2024, author = {Redblock AI Team}, title = {PARROT: Performance Assessment of Reasoning and Responses on Trivia}, year = 2024, publisher = {Redblock}, url = {https://huggingface.co/datasets/redblock/parrot}, license = {CC BY 4.0} }
APA: Redblock AI Team. (2024). PARROT: Performance Assessment of Reasoning and Responses on Trivia. Redblock. Available at https://huggingface.co/datasets/redblock-ai/parrot.
免责声明
重要通知: 该基准数据集包括从《谁想成为百万富翁?Fandom》和《J! Archive》粉丝创建的网站中提取的内容。这些数据集仅用于研究、教育目的和非商业用途。Redblock不拥有这些内容的所有权,也不与《谁想成为百万富翁?》和《J! Archive》的创作者或版权持有者有任何关联。
《谁想成为百万富翁?Fandom》和《J! Archive》是其各自所有者的注册商标。Redblock对这些材料的使用受美国版权法中定义的合理使用原则保护,该原则允许出于批评、评论、新闻报道、教学、奖学金和研究等目的使用受版权保护的材料。
Redblock已根据美国法律修改了这些数据集,以确保内容保持在合理使用的界限内。从这些数据集中创建的任何修改或衍生作品也应遵守合理使用的原则,并尊重原始内容创作者的知识产权。
该基准由Redblock“按原样”提供,不保证其准确性或适用于特定目的。该基准的用户应鼓励尊重版权法和原始内容创作者的知识产权。未经权利持有人适当授权,不得将这些数据集用于商业目的。