explodinggradients/WikiEval
收藏Hugging Face2023-09-18 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/explodinggradients/WikiEval
下载链接
链接失效反馈官方服务:
资源简介:
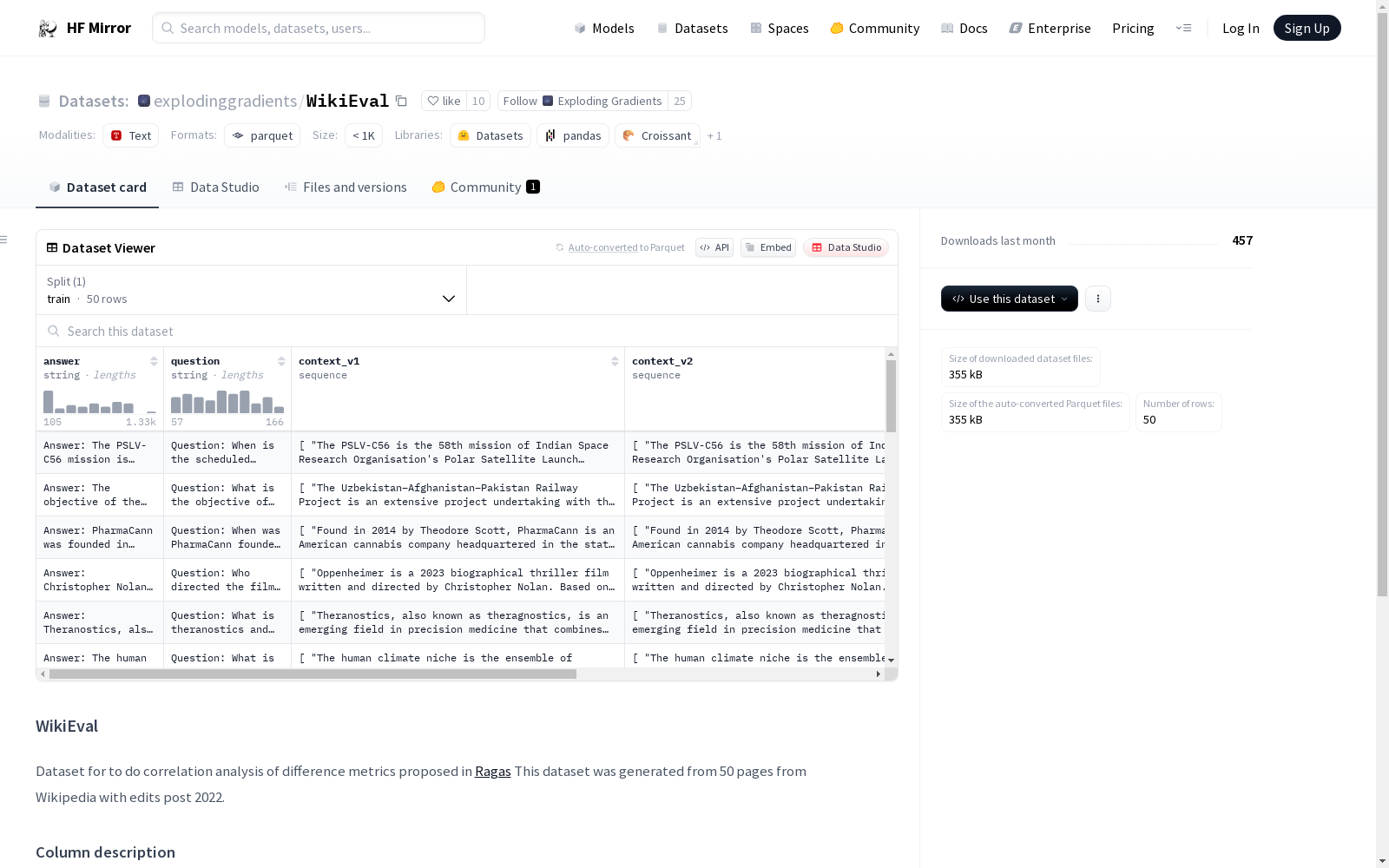
WikiEval数据集用于分析Ragas项目中提出的不同指标的相关性。该数据集包含50个来自2022年后编辑的维基百科页面的样本,每个样本包含问题、答案、上下文等信息。数据集的特征包括问题、答案、上下文的不同版本、未基于上下文的答案、来源以及质量较差的答案。
The WikiEval dataset is used for correlation analysis of different metrics, generated from 50 Wikipedia pages, including features such as question, source, grounded answer, ungrounded answer, and poor answer.
提供机构:
explodinggradients
原始信息汇总
WikiEval 数据集概述
数据集信息
- 特征列表:
answer: 字符串类型question: 字符串类型context_v1: 字符串序列context_v2: 字符串序列ungrounded_answer: 字符串类型source: 字符串类型poor_answer: 字符串类型
- 数据分割:
train: 包含 50 个样本,总字节数为 548755
- 下载大小: 354738 字节
- 数据集大小: 548755 字节
列描述
question: 可以从给定 Wikipedia 页面(source)回答的问题。source: 生成问题和上下文的 Wikipedia 页面来源。grounded_answer: 基于context_v1的答案。ungrounded_answer: 不基于context_v1生成的答案。poor_answer: 与grounded_answer和ungrounded_answer相比相关性较差的答案。context_v1: 回答给定问题的理想上下文。context_v2: 包含与context_v1相比冗余信息的上下文。
搜集汇总
数据集介绍
构建方式
explodinggradients/WikiEval数据集的构建,是基于对维基百科特定页面内容的深入挖掘与编辑。该数据集由50个维基百科页面的修订版本构成,旨在针对不同评价指标的相关性分析进行研究。
特点
该数据集的特点在于,它包含了针对给定问题从维基百科页面生成的多种类型的答案,包括基于上下文的答案、无上下文的答案以及低相关性的答案。此外,数据集还提供了理想答案上下文和包含冗余信息的上下文,以便进行详细的评价比较。
使用方法
使用explodinggradients/WikiEval数据集时,研究者可以加载train split中的数据,这些数据包含了问题、答案、上下文以及来源等字段。通过对这些字段的深入分析,可以评估和比较不同评价指标的性能,从而推进相关性分析的研究工作。
背景与挑战
背景概述
WikiEval数据集,诞生于2022年之后,由explodinggradients团队精心构建,旨在对Ragas论文中提出的多种度量标准进行相关性分析。该数据集精选了50篇维基百科页面,并围绕这些页面设计了问题及其答案,包括基于上下文的答案、无上下文的答案以及低相关性的答案。其研究成果对于理解不同答案质量度量方法在真实世界应用中的效果具有重要价值,为自然语言处理领域的信息检索与问答系统研究提供了新的视角。
当前挑战
在构建WikiEval数据集的过程中,研究人员面临着如何精确地定义和区分不同类型答案的挑战,包括确保答案的准确性、相关性以及上下文的适宜性。此外,数据集构建中还需克服如何从维基百科内容中自动提取高质量的问题和理想答案的难题。在研究领域内,如何利用该数据集有效评估和比较各种度量方法,以解决实际问题,同样是一项不容忽视的挑战。
常用场景
经典使用场景
在深度学习领域,评估模型对问题的理解和回答能力是至关重要的。WikiEval数据集为此提供了理想的研究平台,其经典使用场景在于对问答系统的相关性度量进行分析和比较。
实际应用
在实际应用中,WikiEval数据集可用于优化搜索引擎的问答功能,提升在线客服系统的响应质量,以及提高知识图谱问答组件的准确性。
衍生相关工作
基于WikiEval数据集,学术界已衍生出一系列相关工作,如对现有度量的改进、新型问答系统的开发,以及对不同语言和文化背景下的问答系统性能评估研究。
以上内容由遇见数据集搜集并总结生成


