Dolci-RLZero-Math-7B
收藏Hugging Face2025-11-20 更新2025-11-21 收录
下载链接:
https://huggingface.co/datasets/allenai/Dolci-RLZero-Math-7B
下载链接
链接失效反馈官方服务:
资源简介:
Dolci RL-Zero Math是一个包含13.3k个数学问题和答案的数据集,用于强化学习训练,特别是用于Olmo 3 RL-Zero Math 7B模型的训练。这个数据集是从DAPO Math和Klear Reasoner Math数据集中收集的子集。
提供机构:
Allen Institute for AI
创建时间:
2025-11-18
原始信息汇总
Dolci RL-Zero Math 数据集概述
基本信息
- 数据集名称: Dolci RL-Zero Math
- 发布机构: AllenAI
- 许可证: ODC-BY
- 语言: 英语
数据规模
- 训练集样本数量: 13,314
- 训练集大小: 8,526,688字节
- 下载大小: 4,292,825字节
数据特征
- 提示词: 字符串类型
- 正确答案: 字符串类型
- 消息列表: 包含内容和角色的字符串字段
- 数据集来源: 字符串类型
用途说明
- 主要用途: 用于Olmo 3 RL-Zero Math 7B模型的RLVR训练
- 任务类别: 强化学习
- 数据领域: 数学问答
数据来源
- DAPO Math数据集子集
- Klear Reasoner Math数据集子集
使用方式
可通过HuggingFace datasets库加载: python from datasets import load_dataset dataset = load_dataset("allenai/dolci-rlzero-math-7b", split="train")
许可信息
遵循ODC-BY许可证,仅限研究和教育用途,需遵守Ai2负责任使用指南。
搜集汇总
数据集介绍
构建方式
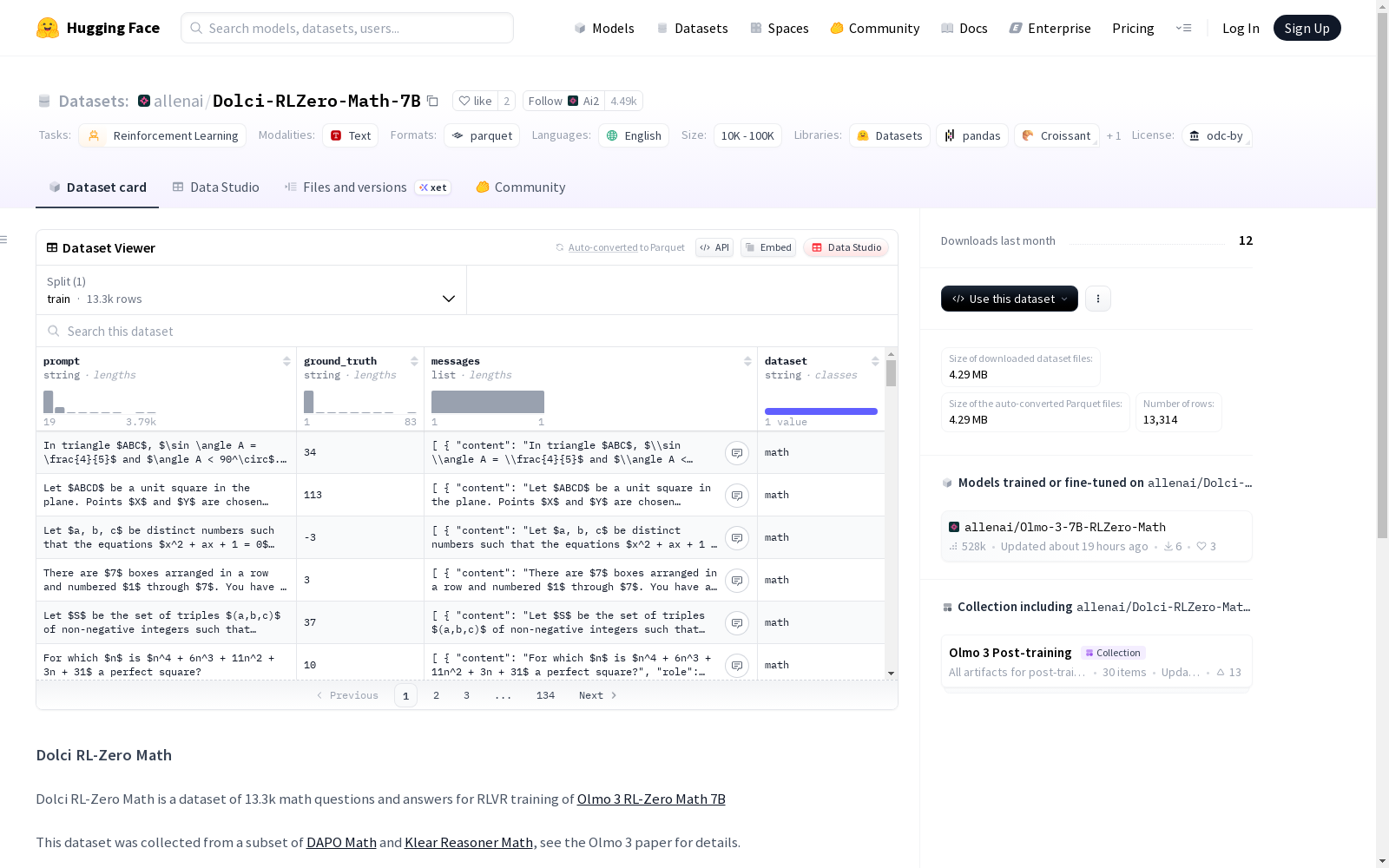
在数学推理数据集构建领域,Dolci-RLZero-Math-7B通过精心筛选与整合两大权威数学问题库形成其核心内容。该数据集从DAPO Math的17千条数学问题与Klear Reasoner Math的30千条数学子集中提取高质量样本,经过多轮数据清洗与标注流程,最终构建出包含1.3万条数学问答对的标准化语料库。这种构建方式既保证了数据来源的多样性,又通过严格的筛选机制确保了样本的准确性与代表性。
特点
该数据集展现出三个显著特征:其结构化设计包含提示文本、标准答案、对话序列及数据来源标识等多维度特征字段,支持复杂的强化学习训练场景。所有样本均采用英语表述,确保了语言的一致性,同时覆盖代数、几何等数学分支的多样化问题类型。数据规模经过优化平衡,既满足模型训练需求又保持高效加载性能,每条样本都经过专业验证以保证推理逻辑的严谨性。
使用方法
研究人员可通过HuggingFace生态系统便捷地调用该数据集,使用标准代码接口即可完成数据加载与预处理。在具体应用中,开发者可将数据集直接接入强化学习训练流程,通过解析提示文本与标准答案的对应关系构建奖励模型。该数据集遵循ODC-BY许可协议,允许在符合伦理准则的研究与教育场景中自由使用,为数学推理模型的迭代优化提供可靠的数据支撑。
背景与挑战
背景概述
随着人工智能在数学推理领域的发展,高质量训练数据的需求日益凸显。Dolci-RLZero-Math-7B数据集由AllenAI研究所于2024年构建,专为强化学习价值回归训练设计,旨在提升语言模型解决复杂数学问题的能力。该数据集整合了DAPO Math与Klear Reasoner Math的精选子集,通过13.3万条数学问答样本支撑Olmo-3-7B模型的优化,推动了教育智能与自动推理技术的交叉研究。
当前挑战
数学问题求解需应对符号运算与逻辑推导的双重复杂性,传统模型常因语义理解偏差导致推理链断裂。数据集构建过程中面临多源数据对齐的挑战,包括问题表述规范化、答案一致性校验以及跨领域知识融合。此外,保持数学术语的精确性与解题步骤的完整性,需克服标注噪声与语义鸿沟问题。
常用场景
经典使用场景
在数学推理领域,Dolci-RLZero-Math-7B数据集作为强化学习训练的核心资源,专门用于优化语言模型在复杂数学问题求解中的策略生成能力。其13.3千条高质量问答对覆盖了代数、几何与逻辑推理等多元主题,通过模拟人类逐步推导过程,为模型提供结构化的思维链训练范例,显著提升了数值计算与符号推理的准确性。
衍生相关工作
基于该数据集训练的Olmo-3-RLZero-Math模型催生了多项突破性研究,包括分层强化学习框架在数学推理中的迁移应用,以及多模态数学问题求解系统的开发。这些工作进一步拓展至物理建模与代码生成领域,形成了以数学逻辑为核心的跨学科技术生态,为认知计算提供了新的方法论支撑。
数据集最近研究
最新研究方向
在数学推理与强化学习融合的前沿领域,Dolci-RLZero-Math-7B数据集正推动无监督奖励建模范式的革新。该数据集通过整合DAPO Math与Klear Reasoner Math的优质数学问题,为Olmo-3系列模型的RLVR训练提供精准监督信号。当前研究聚焦于构建端到端的数学推理系统,探索语言模型在符号运算与逻辑推导中的零样本泛化能力,相关成果已在自动解题、教育智能助手等场景引发广泛关注。这种以纯数据驱动替代人工奖励设计的路径,不仅降低了强化学习对领域知识的依赖,更为构建可解释的数学认知模型奠定了实验基础。
以上内容由遇见数据集搜集并总结生成


