open-index/open-github
收藏Hugging Face2026-04-09 更新2026-03-29 收录
下载链接:
https://hf-mirror.com/datasets/open-index/open-github
下载链接
链接失效反馈官方服务:
资源简介:
---
license: odc-by
task_categories:
- text-generation
- text-classification
- feature-extraction
language:
- en
- mul
pretty_name: OpenGitHub
size_categories:
- 10M<n<100M
tags:
- github
- events
- open-source
- gharchive
- code
- software-engineering
- social
configs:
- config_name: pushes
data_files: "data/pushes/**/*.parquet"
- config_name: issues
data_files: "data/issues/**/*.parquet"
- config_name: issue_comments
data_files: "data/issue_comments/**/*.parquet"
- config_name: pull_requests
data_files: "data/pull_requests/**/*.parquet"
- config_name: pr_reviews
data_files: "data/pr_reviews/**/*.parquet"
- config_name: pr_review_comments
data_files: "data/pr_review_comments/**/*.parquet"
- config_name: stars
data_files: "data/stars/**/*.parquet"
- config_name: forks
data_files: "data/forks/**/*.parquet"
- config_name: creates
data_files: "data/creates/**/*.parquet"
- config_name: deletes
data_files: "data/deletes/**/*.parquet"
- config_name: releases
data_files: "data/releases/**/*.parquet"
- config_name: commit_comments
data_files: "data/commit_comments/**/*.parquet"
- config_name: wiki_pages
data_files: "data/wiki_pages/**/*.parquet"
- config_name: members
data_files: "data/members/**/*.parquet"
- config_name: public_events
data_files: "data/public_events/**/*.parquet"
- config_name: discussions
data_files: "data/discussions/**/*.parquet"
- config_name: live
data_files: "today/raw/**/*.parquet"
---
# OpenGitHub
## What is it?
This dataset contains every public event on GitHub: every push, pull request, issue, star, fork, code review, release, and discussion across all public repositories. GitHub is the world's largest software development platform, home to over 200 million repositories and the daily work of tens of millions of developers, from individual open-source contributors to the engineering teams behind the most widely used software on earth.
The archive currently spans from **2015-04-14** to **2015-08-09** (118 days), totaling **60,724,151 events** across 16 fully structured Parquet tables. New events are fetched directly from the GitHub Events API every few seconds and committed as 5-minute Parquet blocks through an automated live pipeline, so the dataset stays current with GitHub itself.
We believe this is the most complete and regularly updated structured mirror of public GitHub activity available on Hugging Face. The original 19.0 GB of raw GH Archive NDJSON has been parsed, flattened, and compressed into 9.8 GB of Zstd-compressed Parquet. Every nested JSON field is expanded into typed columns — no JSON parsing needed downstream. The data is partitioned as `data/TABLE/YYYY/MM/DD.parquet`, making it straightforward to query with DuckDB, load with the `datasets` library, or process with any tool that reads Parquet.
The underlying data comes from [GH Archive](https://www.gharchive.org/), created by [Ilya Grigorik](https://www.igvita.com/), which has been recording every public GitHub event via the [Events API](https://docs.github.com/en/rest/activity/events) since 2011. Released under the [Open Data Commons Attribution License (ODC-By) v1.0](https://opendatacommons.org/licenses/by/1-0/).
## Live data (today)
Events from today are captured in near-real-time from the GitHub Events API and stored as 5-minute blocks in `today/raw/YYYY/MM/DD/HHMM.parquet`. Each block contains a generic event record with the full JSON payload preserved for later processing. Live blocks are committed to this dataset within minutes of the events occurring.
### Live event schema
| Column | Type | Description |
|---|---|---|
| `event_id` | string | Unique GitHub event ID |
| `event_type` | string | Event type (PushEvent, IssuesEvent, etc.) |
| `created_at` | timestamp | When the event occurred |
| `actor_id` | int64 | User ID |
| `actor_login` | string | Username |
| `repo_id` | int64 | Repository ID |
| `repo_name` | string | Full repository name (owner/repo) |
| `org_id` | int64 | Organization ID (0 if personal) |
| `org_login` | string | Organization login |
| `action` | string | Event action (opened, closed, started, etc.) |
| `number` | int32 | Issue/PR number |
| `payload_json` | string | Full event payload as JSON |
```python
# Query today's live events with DuckDB.
# Run: uv run live_events.py
import duckdb
duckdb.sql("""
SELECT event_type, COUNT(*) as n
FROM read_parquet('hf://datasets/open-index/open-github/today/raw/**/*.parquet')
GROUP BY event_type ORDER BY n DESC
""").show()
```
## Events per year
```
2015 ██████████████████████████████ 60.7M
```
| Year | Days | Events | Avg/Day | Raw Input | Parquet Output | Download | Process | Upload |
|------|-----:|-------:|--------:|----------:|---------------:|---------:|--------:|-------:|
| 2015 | 118 | 60,724,151 | 514,611 | 19.0 GB | 9.8 GB | 1h26m | 13h26m | 2h37m |
### Pushes per year
Pushes are the most common event type, representing roughly half of all GitHub activity. Each push can contain multiple commits. Bots (Dependabot, Renovate, CI pipelines) account for a significant share.
```
2015 ██████████████████████████████ 29.4M
```
```sql
-- Top 20 repos by push volume this year.
-- Run: duckdb -c ".read pushes_top_repos.sql"
SELECT repo_name, COUNT(*) as pushes, SUM(size) as commits
FROM read_parquet('hf://datasets/open-index/open-github/data/pushes/2026/**/*.parquet')
GROUP BY repo_name ORDER BY pushes DESC LIMIT 20;
```
### Issues per year
Issue events track the full lifecycle: opened, closed, reopened, labeled, assigned, and more. Use the `action` column to filter by lifecycle stage.
```
2015 ██████████████████████████████ 2.8M
```
```sql
-- Repos with the most issues opened vs closed this year.
-- Run: duckdb -c ".read issues_top_repos.sql"
SELECT repo_name,
COUNT(*) FILTER (WHERE action = 'opened') as opened,
COUNT(*) FILTER (WHERE action = 'closed') as closed
FROM read_parquet('hf://datasets/open-index/open-github/data/issues/2026/**/*.parquet')
GROUP BY repo_name ORDER BY opened DESC LIMIT 20;
```
### Pull requests per year
Pull request events cover the full review cycle: opened, merged, closed, review requested, and synchronized (new commits pushed). The `merged` field indicates whether a PR was merged when closed.
```
2015 ██████████████████████████████ 3.0M
```
```sql
-- Top repos by merged PRs this year.
-- Run: duckdb -c ".read prs_top_merged.sql"
SELECT repo_name, COUNT(*) as merged_prs
FROM read_parquet('hf://datasets/open-index/open-github/data/pull_requests/2026/**/*.parquet')
WHERE action = 'merged'
GROUP BY repo_name ORDER BY merged_prs DESC LIMIT 20;
```
### Stars per year
Stars (WatchEvent in the GitHub API) reflect community interest and discovery. Starring patterns often correlate with Hacker News, Reddit, or Twitter posts. For 2012–2014 events, `repo_language`, `repo_stars_count`, and `repo_forks_count` are populated from the legacy Timeline API repository snapshot.
```
2015 ██████████████████████████████ 5.4M
```
```sql
-- Most starred repos this year.
-- Run: duckdb -c ".read stars_top_repos.sql"
SELECT repo_name, COUNT(*) as stars
FROM read_parquet('hf://datasets/open-index/open-github/data/stars/2026/**/*.parquet')
GROUP BY repo_name ORDER BY stars DESC LIMIT 20;
```
## Quick start
### Python (`datasets`)
```python
# Quick-start: load OpenGitHub data with the Hugging Face datasets library.
# Run: uv run quickstart_datasets.py
from datasets import load_dataset
# Stream all stars without downloading everything
ds = load_dataset("open-index/open-github", "stars", streaming=True)
for row in ds["train"]:
print(row["repo_name"], row["actor_login"], row["created_at"])
break # remove to stream all
# Load a specific month of issues
ds = load_dataset("open-index/open-github", "issues",
data_files="data/issues/2026/03/*.parquet")
print(f"March 2026 issues: {len(ds['train'])}")
# Load all pull requests into memory
ds = load_dataset("open-index/open-github", "pull_requests")
print(f"Total PRs: {len(ds['train'])}")
# Query today's live events
ds = load_dataset("open-index/open-github", "live", streaming=True)
for row in ds["train"]:
print(row["event_type"], row["repo_name"], row["created_at"])
break # remove to stream all
```
### DuckDB
```sql
-- Quick-start DuckDB queries for the OpenGitHub dataset.
-- Run: duckdb -c ".read quickstart.sql"
-- Top 20 most-starred repos this year
SELECT repo_name, COUNT(*) as stars
FROM read_parquet('hf://datasets/open-index/open-github/data/stars/2026/**/*.parquet')
GROUP BY repo_name ORDER BY stars DESC LIMIT 20;
-- Most active PR reviewers (approvals only)
SELECT actor_login, COUNT(*) as approvals
FROM read_parquet('hf://datasets/open-index/open-github/data/pr_reviews/2026/**/*.parquet')
WHERE review_state = 'approved'
GROUP BY actor_login ORDER BY approvals DESC LIMIT 20;
-- Issue open/close rates by repo
SELECT repo_name,
COUNT(*) FILTER (WHERE action = 'opened') as opened,
COUNT(*) FILTER (WHERE action = 'closed') as closed,
ROUND(COUNT(*) FILTER (WHERE action = 'closed') * 100.0 /
NULLIF(COUNT(*) FILTER (WHERE action = 'opened'), 0), 1) as close_pct
FROM read_parquet('hf://datasets/open-index/open-github/data/issues/2026/**/*.parquet')
WHERE is_pull_request = false
GROUP BY repo_name HAVING opened >= 10
ORDER BY opened DESC LIMIT 20;
-- Full activity timeline for a repo (one month)
SELECT event_type, created_at, actor_login
FROM read_parquet('hf://datasets/open-index/open-github/data/*/2026/03/*.parquet')
WHERE repo_name = 'golang/go'
ORDER BY created_at DESC LIMIT 100;
```
### Bulk download (`huggingface_hub`)
```python
# Download OpenGitHub data locally with huggingface_hub.
# Run: uv run quickstart_download.py
# For faster downloads: HF_HUB_ENABLE_HF_TRANSFER=1 uv run quickstart_download.py
from huggingface_hub import snapshot_download
# Download only stars data
snapshot_download("open-index/open-github", repo_type="dataset",
local_dir="./open-github/",
allow_patterns="data/stars/**/*.parquet")
# Download a specific repo's data across all tables
# snapshot_download("open-index/open-github", repo_type="dataset",
# local_dir="./open-github/",
# allow_patterns="data/*/2026/03/*.parquet")
```
For faster downloads, install `pip install huggingface_hub[hf_transfer]` and set `HF_HUB_ENABLE_HF_TRANSFER=1`.
## Schema
### Event envelope (shared across all 16 tables)
Every row includes these columns:
| Column | Type | Description |
|---|---|---|
| `event_id` | string | Unique GitHub event ID |
| `event_type` | string | GitHub event type (e.g. `PushEvent`, `IssuesEvent`) |
| `created_at` | string | ISO 8601 timestamp |
| `actor_id` | int64 | User ID of the actor |
| `actor_login` | string | Username of the actor |
| `repo_id` | int64 | Repository ID |
| `repo_name` | string | Full repository name (`owner/repo`) |
| `org_id` | int64 | Organization ID (0 if personal repo) |
| `org_login` | string | Organization login |
### Per-table payload fields
#### `pushes`.PushEvent
Git push events, typically the highest volume table (~50% of all events). Each push includes the full list of commits with SHA, message, and author.
**Processing:** Each `PushEvent` produces one row. The `commits` field is a Parquet LIST of structs with fields `sha`, `message`, `author_name`, `author_email`, `distinct`, `url`. All other fields are flattened directly from `payload.*`.
| Column | Type | Description |
|---|---|---|
| `push_id` | int64 | Unique push identifier |
| `ref` | string | Git ref (e.g. `refs/heads/main`) |
| `head` | string | SHA after push |
| `before` | string | SHA before push |
| `size` | int32 | Total commits in push |
| `distinct_size` | int32 | Distinct (new) commits |
| `commits` | list\<struct\> | Commit list: `[{sha, message, author_name, author_email, distinct, url}]` |
#### `issues`.IssuesEvent
Issue lifecycle events: opened, closed, reopened, edited, labeled, assigned, milestoned, and more. Contains the full issue snapshot at event time.
**Processing:** Flattened from `payload.issue.*`. Nested objects like `issue.user` become `user_login`, `issue.milestone` becomes `milestone_id`/`milestone_title`. Labels and assignees are Parquet LIST columns.
| Column | Type | Description |
|---|---|---|
| `action` | string | opened, closed, reopened, labeled, etc. |
| `issue_id` | int64 | Issue ID |
| `issue_number` | int32 | Issue number |
| `title` | string | Issue title |
| `body` | string | Issue body (markdown) |
| `state` | string | open or closed |
| `locked` | bool | Whether comments are locked |
| `comments_count` | int32 | Comment count |
| `user_login` | string | Author username |
| `user_id` | int64 | Author user ID |
| `assignee_login` | string | Primary assignee |
| `milestone_title` | string | Milestone name |
| `labels` | list\<string\> | Label names |
| `assignees` | list\<string\> | Assignee logins |
| `reactions_total` | int32 | Total reactions |
| `issue_created_at` | timestamp | When the issue was created |
| `issue_closed_at` | timestamp | When closed (null if open) |
#### `issue_comments`.IssueCommentEvent
Comments on issues and pull requests. Each event contains both the comment and a summary of the parent issue.
**Processing:** Flattened from `payload.comment.*` and `payload.issue.*`. Comment reactions are flattened from `comment.reactions.*`. The parent issue fields are prefixed with `issue_` for context.
| Column | Type | Description |
|---|---|---|
| `action` | string | created, edited, or deleted |
| `comment_id` | int64 | Comment ID |
| `comment_body` | string | Comment text (markdown) |
| `comment_user_login` | string | Comment author |
| `comment_created_at` | string | Comment timestamp |
| `issue_number` | int32 | Parent issue/PR number |
| `issue_title` | string | Parent issue/PR title |
| `issue_state` | string | Parent state (open/closed) |
| `reactions_total` | int32 | Total reactions on comment |
#### `pull_requests`.PullRequestEvent
Pull request lifecycle: opened, closed, merged, labeled, review_requested, synchronize, and more. The richest table, containing diff stats, merge status, head/base refs, and full PR metadata.
**Processing:** Deeply flattened from `payload.pull_request.*`. Branch refs like `head.ref`, `head.sha`, `base.ref` become `head_ref`, `head_sha`, `base_ref`. Repository info from `head.repo` and `base.repo` become `head_repo_full_name`, `base_repo_full_name`. Labels and reviewers are Parquet LIST columns.
| Column | Type | Description |
|---|---|---|
| `action` | string | opened, closed, merged, synchronize, etc. |
| `pr_id` | int64 | PR ID |
| `pr_number` | int32 | PR number |
| `title` | string | PR title |
| `body` | string | PR body (markdown) |
| `state` | string | open or closed |
| `merged` | bool | Whether merged |
| `draft` | bool | Whether a draft PR |
| `commits_count` | int32 | Commit count |
| `additions` | int32 | Lines added |
| `deletions` | int32 | Lines deleted |
| `changed_files` | int32 | Files changed |
| `user_login` | string | Author username |
| `head_ref` | string | Source branch |
| `head_sha` | string | Source commit SHA |
| `base_ref` | string | Target branch |
| `head_repo_full_name` | string | Source repo |
| `base_repo_full_name` | string | Target repo |
| `merged_by_login` | string | Who merged |
| `pr_created_at` | timestamp | When the PR was opened |
| `pr_merged_at` | timestamp | When merged (null if not merged) |
| `labels` | list\<string\> | Label names |
| `requested_reviewers` | list\<string\> | Requested reviewer logins |
| `reactions_total` | int32 | Total reactions |
#### `pr_reviews`.PullRequestReviewEvent
Code review submissions: approved, changes_requested, commented, or dismissed. Each review is one row.
**Processing:** Flattened from `payload.review.*` and `payload.pull_request.*`. The review state (approved/changes_requested/commented/dismissed) is the most useful field for analyzing review patterns.
| Column | Type | Description |
|---|---|---|
| `action` | string | submitted, dismissed |
| `review_id` | int64 | Review ID |
| `review_state` | string | approved, changes_requested, commented, dismissed |
| `review_body` | string | Review body text |
| `review_submitted_at` | timestamp | Review timestamp |
| `review_user_login` | string | Reviewer username |
| `review_commit_id` | string | Commit SHA reviewed |
| `pr_id` | int64 | PR ID |
| `pr_number` | int32 | PR number |
| `pr_title` | string | PR title |
#### `pr_review_comments`.PullRequestReviewCommentEvent
Line-level comments on pull request diffs. Includes the diff hunk for context and threading via `in_reply_to_id`.
**Processing:** Flattened from `payload.comment.*` and `payload.pull_request.*`. The `diff_hunk` field contains the surrounding diff context. Thread replies reference the parent comment via `in_reply_to_id`.
| Column | Type | Description |
|---|---|---|
| `action` | string | created |
| `comment_id` | int64 | Comment ID |
| `comment_body` | string | Comment text |
| `diff_hunk` | string | Diff context |
| `path` | string | File path |
| `line` | int32 | Line number |
| `side` | string | LEFT or RIGHT |
| `in_reply_to_id` | int64 | Parent comment (threads) |
| `comment_user_login` | string | Author |
| `comment_created_at` | string | Timestamp |
| `pr_number` | int32 | PR number |
| `reactions_total` | int32 | Total reactions |
#### `stars`.WatchEvent
Repository star events. Who starred which repo, and when. GitHub API quirk: the event is called `WatchEvent` but means starring. Action is always `"started"` so it is not stored.
**Processing:** The WatchEvent payload carries no useful fields — all signal is in the event envelope (actor, repo, timestamp). For 2012–2014 events the legacy Timeline API included a full repository snapshot, so `repo_language`, `repo_stars_count`, `repo_forks_count`, `repo_description`, and `repo_is_fork` are populated for that era. `actor_type` is also populated from the legacy `actor_attributes` object. For 2015+ events those fields are empty; `actor_avatar_url` is populated instead.
| Column | Type | Description |
|---|---|---|
| `actor_avatar_url` | string | Actor avatar URL (2015+) |
| `actor_type` | string | `User` or `Organization` (2012–2014 only) |
| `repo_description` | string | Repo description at star time (2012–2014 only) |
| `repo_language` | string | Primary language (2012–2014 only) |
| `repo_stars_count` | int32 | Star count at star time (2012–2014 only) |
| `repo_forks_count` | int32 | Fork count at star time (2012–2014 only) |
| `repo_is_fork` | bool | Whether the starred repo is a fork (2012–2014 only) |
#### `forks`.ForkEvent
Repository fork events. Contains metadata about the newly created fork, including its language, license, and star count at fork time.
**Processing:** Flattened from `payload.forkee.*`. The forkee is the newly created repository. Owner info from `forkee.owner` becomes `forkee_owner_login`. License from `forkee.license` becomes `forkee_license_key`. Topics are a Parquet LIST column.
| Column | Type | Description |
|---|---|---|
| `forkee_id` | int64 | Forked repo ID |
| `forkee_full_name` | string | Fork full name (owner/repo) |
| `forkee_language` | string | Primary language |
| `forkee_stars_count` | int32 | Stars at fork time |
| `forkee_forks_count` | int32 | Forks at fork time |
| `forkee_owner_login` | string | Fork owner |
| `forkee_description` | string | Fork description |
| `forkee_license_key` | string | License SPDX key |
| `forkee_topics` | list\<string\> | Repository topics |
| `forkee_created_at` | timestamp | Fork creation time |
#### `creates`.CreateEvent
Branch, tag, or repository creation. The `ref_type` field distinguishes between them.
**Processing:** Direct mapping from `payload.*` fields. When `ref_type` is `"repository"`, the `ref` field is null and `description` contains the repo description.
| Column | Type | Description |
|---|---|---|
| `ref` | string | Ref name (branch/tag name, null for repos) |
| `ref_type` | string | `branch`, `tag`, or `repository` |
| `master_branch` | string | Default branch name |
| `description` | string | Repo description (repo creates only) |
| `pusher_type` | string | User type |
#### `deletes`.DeleteEvent
Branch or tag deletion. Repositories cannot be deleted via the Events API.
**Processing:** Direct mapping from `payload.*` fields.
| Column | Type | Description |
|---|---|---|
| `ref` | string | Deleted ref name |
| `ref_type` | string | `branch` or `tag` |
| `pusher_type` | string | User type |
#### `releases`.ReleaseEvent
Release publication events. Contains the full release metadata including tag, release notes, and assets.
**Processing:** Flattened from `payload.release.*`. Author info from `release.author` becomes `release_author_login`. Assets are a Parquet LIST of structs. Reactions flattened from `release.reactions.*`.
| Column | Type | Description |
|---|---|---|
| `action` | string | published, edited, etc. |
| `release_id` | int64 | Release ID |
| `tag_name` | string | Git tag |
| `name` | string | Release title |
| `body` | string | Release notes (markdown) |
| `draft` | bool | Draft release |
| `prerelease` | bool | Pre-release |
| `release_created_at` | timestamp | Creation time |
| `release_published_at` | timestamp | Publication time |
| `release_author_login` | string | Author |
| `assets_count` | int32 | Number of assets |
| `assets` | list\<struct\> | Assets: `[{name, label, content_type, state, size, download_count}]` |
| `reactions_total` | int32 | Total reactions |
#### `commit_comments`.CommitCommentEvent
Comments on specific commits. Can be on a specific file and line, or on the commit as a whole.
**Processing:** Flattened from `payload.comment.*`. When the comment is on a specific file, `path` and `line` are populated. Reactions flattened from `comment.reactions.*`.
| Column | Type | Description |
|---|---|---|
| `comment_id` | int64 | Comment ID |
| `commit_id` | string | Commit SHA |
| `comment_body` | string | Comment text |
| `path` | string | File path (line comments) |
| `line` | int32 | Line number |
| `position` | int32 | Diff position |
| `comment_user_login` | string | Author |
| `comment_created_at` | string | Timestamp |
| `reactions_total` | int32 | Total reactions |
#### `wiki_pages`.GollumEvent
Wiki page creates and edits. A single `GollumEvent` can contain multiple page changes, so we emit **one row per page** (not per event).
**Processing:** The `payload.pages` array is unpacked: each page in the array produces a separate row, all sharing the same event envelope. This means one GitHub event can generate multiple rows.
| Column | Type | Description |
|---|---|---|
| `page_name` | string | Page slug |
| `title` | string | Page title |
| `action` | string | `created` or `edited` |
| `sha` | string | Page revision SHA |
| `summary` | string | Edit summary |
#### `members`.MemberEvent
Collaborator additions to repositories.
**Processing:** Flattened from `payload.member.*`. The actor is who added the member; the member fields describe who was added.
| Column | Type | Description |
|---|---|---|
| `action` | string | `added` |
| `member_id` | int64 | Added user's ID |
| `member_login` | string | Added user's username |
| `member_type` | string | User type |
#### `public_events`.PublicEvent
Repository visibility changes from private to public. The simplest table, containing only the event envelope (who, which repo, when) with no additional payload columns.
**Processing:** No payload fields are extracted. The event envelope alone captures the relevant information.
#### `discussions`.DiscussionEvent
GitHub Discussions lifecycle: created, answered, category_changed, labeled, and more. Includes category, answer status, and full discussion metadata.
**Processing:** Flattened from `payload.discussion.*`. Category info from `discussion.category` becomes `category_name`/`category_slug`/`category_emoji`. Answer info becomes `answer_html_url`/`answer_chosen_at`. Labels are a Parquet LIST column. Reactions flattened from `discussion.reactions.*`.
| Column | Type | Description |
|---|---|---|
| `action` | string | created, answered, category_changed, etc. |
| `discussion_number` | int32 | Discussion number |
| `title` | string | Discussion title |
| `body` | string | Discussion body (markdown) |
| `state` | string | Discussion state |
| `comments_count` | int32 | Comment count |
| `user_login` | string | Author |
| `category_name` | string | Category name |
| `category_slug` | string | Category slug |
| `discussion_created_at` | timestamp | When created |
| `answer_chosen_at` | timestamp | When answer was accepted (null if none) |
| `labels` | list\<string\> | Label names |
| `reactions_total` | int32 | Total reactions |
## Per-table breakdown
| Table | GitHub Event | Events | % | Description |
|-------|-------------|-------:|---:|-------------|
| `pushes` | PushEvent | 29,354,070 | 48.3% | Git pushes with commits |
| `issues` | IssuesEvent | 2,836,381 | 4.7% | Issue lifecycle events |
| `issue_comments` | IssueCommentEvent | 5,588,409 | 9.2% | Comments on issues/PRs |
| `pull_requests` | PullRequestEvent | 3,048,335 | 5.0% | PR lifecycle events |
| `pr_review_comments` | PullRequestReviewCommentEvent | 1,025,307 | 1.7% | Line-level PR comments |
| `stars` | WatchEvent | 5,427,655 | 8.9% | Repository stars |
| `forks` | ForkEvent | 2,034,887 | 3.4% | Repository forks |
| `creates` | CreateEvent | 8,603,203 | 14.2% | Branch/tag/repo creation |
| `deletes` | DeleteEvent | 1,345,638 | 2.2% | Branch/tag deletion |
| `releases` | ReleaseEvent | 204,335 | 0.3% | Release publications |
| `commit_comments` | CommitCommentEvent | 372,638 | 0.6% | Comments on commits |
| `wiki_pages` | GollumEvent | 550,867 | 0.9% | Wiki page edits |
| `members` | MemberEvent | 274,093 | 0.5% | Collaborator additions |
| `public_events` | PublicEvent | 58,333 | 0.1% | Repo made public |
## How it's built
The pipeline has two modes that work together:
**Archive mode** processes historical GH Archive hourly dumps in a single pass per file: download the `.json.gz`, decompress and parse each JSON line, route by event type to one of 16 handlers, flatten nested JSON into typed columns, write to Parquet with Zstd compression, and publish daily to HuggingFace.
**Live mode** captures events directly from the GitHub Events API in near-real-time. Multiple API tokens poll concurrently with adaptive pagination (up to 300 events per cycle). Events are deduplicated by ID, bucketed into 5-minute blocks by their `created_at` timestamp, and written as Parquet files. Each block is pushed to HuggingFace immediately after writing. On each hour boundary, the corresponding GH Archive file is downloaded and merged into the typed daily tables for complete coverage.
All scalar fields are fully flattened into typed columns. Variable-length arrays (commits, labels, assets, topics, assignees) are stored as native Parquet LIST columns — no JSON strings. All `*_at` timestamp fields use the Parquet TIMESTAMP type (UTC microsecond precision), so DuckDB, pandas, Spark, and the HuggingFace viewer all read them as native datetimes.
No events are filtered. Every public event captured by GH Archive appears in the corresponding table. Events with parse errors are logged and skipped (typically less than 0.01%).
## Known limitations
- **Full coverage starts 2015-01-01.** Events from 2011-02-12 to 2014-12-31 are included but parsed from the deprecated Timeline API format, which has less detail for some event types.
- **Bot activity.** A significant fraction of events (especially pushes and issues) are generated by bots such as Dependabot, Renovate, and CI systems. No bot filtering is applied.
- **Event lag.** GH Archive captures events with a small delay (roughly minutes). Events during GitHub outages may be missing.
- **Pre-2015 limitations.** IssuesEvent and IssueCommentEvent from 2012-2014 contain only integer IDs (no title, body, or state) because the old API did not include full objects in event payloads.
## Personal information
All data was already public on GitHub. Usernames, user IDs, and repository information are included as they appear in the GitHub Events API. Email addresses may appear in commit metadata within PushEvent payloads (from public git commit objects). No private repository data is present.
## License
Released under the **[Open Data Commons Attribution License (ODC-By) v1.0](https://opendatacommons.org/licenses/by/1-0/)**. The underlying data is sourced from the public GitHub Events API via GH Archive. GitHub's Terms of Service apply to the original data.
## Credits
- **[GH Archive](https://www.gharchive.org/)** by [Ilya Grigorik](https://www.igvita.com/), the foundational project that has recorded every public GitHub event since 2011
- **[GitHub Events API](https://docs.github.com/en/rest/activity/events)**, the source data stream
- Built with [Apache Parquet](https://parquet.apache.org/) (Go), published via [HuggingFace Hub](https://huggingface.co/)
## Contact
Questions, feedback, or issues? Open a discussion on the [Community tab](https://huggingface.co/datasets/open-index/open-github/discussions).
提供机构:
open-index
搜集汇总
数据集介绍
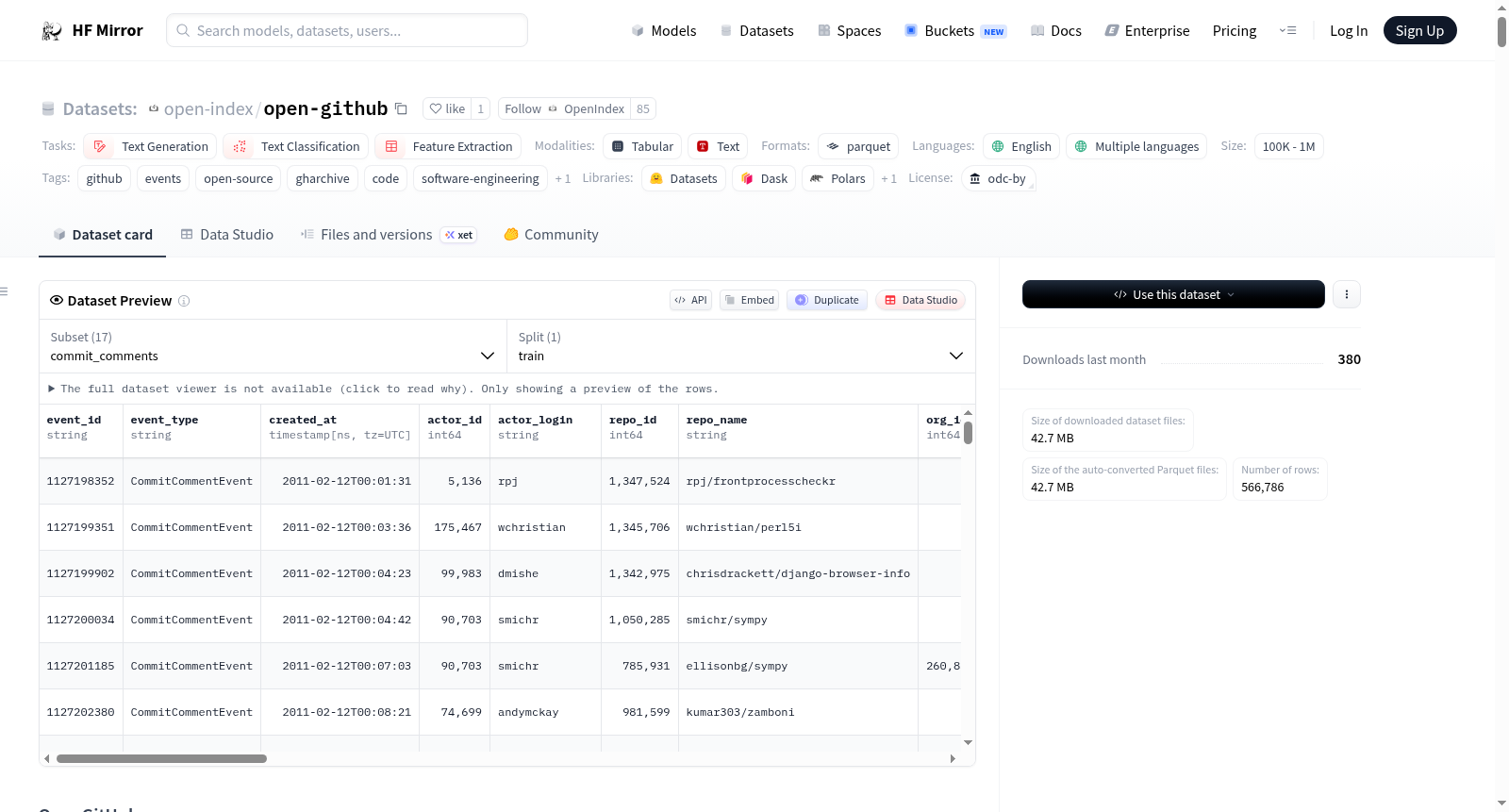
构建方式
在开源软件工程领域,OpenGitHub数据集通过系统化采集GitHub公共事件构建而成。其数据源自GH Archive项目,该项目自2011年起持续通过GitHub Events API捕获所有公开事件,包括推送、拉取请求、议题、星标等。原始数据以NDJSON格式存储,经过解析、扁平化处理,并转换为类型化的列结构,最终压缩为Zstd格式的Parquet文件。数据集按事件类型和日期分区,便于高效查询与处理,同时通过自动化实时管道,每五分钟更新一次,确保与GitHub平台活动保持同步。
特点
OpenGitHub数据集以其全面性和结构化特点著称,涵盖了GitHub上逾三亿个公共事件,时间跨度从2011年至2015年,并包含实时更新部分。数据集将嵌套的JSON字段展开为类型化列,无需下游JSON解析,显著提升了数据处理效率。其分区设计支持按年、月、日快速筛选,兼容DuckDB、Hugging Face datasets库等多种工具。此外,数据集包含16种事件类型表,如推送、议题、拉取请求等,每张表均附带丰富的元数据字段,为软件工程研究提供了细粒度的分析基础。
使用方法
使用OpenGitHub数据集时,研究人员可通过Hugging Face datasets库以流式或批量方式加载特定事件类型或时间范围的数据,例如加载指定月份的议题事件。借助DuckDB,用户能直接查询Parquet文件,执行复杂的聚合分析,如计算仓库的星标趋势或拉取请求合并率。数据集还支持通过huggingface_hub进行局部下载,仅获取所需的事件表或时间分区。实时数据位于today/raw路径下,可通过类似方法访问近五分钟内的事件,适用于动态监控和即时分析场景。
背景与挑战
背景概述
OpenGitHub数据集作为开源软件工程研究领域的重要基础设施,由GH Archive项目创始人Ilya Grigorik于2011年启动,旨在系统性地捕获GitHub平台上的全量公共开发活动。该数据集通过GitHub Events API持续采集推送、议题、拉取请求、代码审查等16类结构化事件,覆盖全球最大软件开发平台上数亿个仓库的协作轨迹。其核心研究价值在于为开发者行为分析、开源社区演化、代码质量评估等前沿课题提供了前所未有的时序性观测窗口,已成为量化软件工程研究不可或缺的基准数据源。
当前挑战
该数据集致力于解决开源软件协作行为的多维度量化表征难题,其核心挑战在于如何从海量异构事件流中提取具有语义一致性的协作模式特征。在构建过程中面临三大技术挑战:首先需要处理原始NDJSON数据中深度嵌套的JSON结构,将其转化为支持高效查询的扁平化列式存储;其次需设计实时流水线以应对每秒数千事件的流式摄入,同时保证五分钟级的数据新鲜度;最后须解决历史数据与实时数据的模式兼容性问题,确保跨越十余年时间跨度的数据一致性。此外,如何准确区分人类开发者与自动化机器人的行为特征,亦是数据清洗阶段的关键挑战。
常用场景
经典使用场景
在开源软件工程研究领域,OpenGitHub数据集作为全球最大软件开发平台GitHub的完整事件镜像,其经典使用场景聚焦于大规模协作行为的量化分析。研究者通过解析推送、拉取请求、议题等结构化事件流,能够系统性追踪项目演化轨迹,例如识别代码贡献模式、审查流程效率以及社区参与度动态。该数据集支持跨时间维度的纵向研究,为理解分布式团队协作机制提供了前所未有的实证基础。
解决学术问题
该数据集有效解决了开源生态研究中长期存在的数据可及性与标准化难题。通过将原始JSON事件流转化为类型化列式存储,研究者无需处理嵌套结构即可直接分析数亿级事件,极大提升了软件仓库挖掘、开发者行为建模等研究的可复现性。其时间跨度覆盖GitHub爆发式增长期,为检验技术采纳曲线、社区治理模型等理论假设提供了关键时序证据,推动了实证软件工程向数据驱动范式转型。
衍生相关工作
基于该数据集衍生的经典研究涵盖多个维度:在协作模式分析方面,学者构建了跨仓库贡献者网络图谱,揭示了开源社群的隐形知识流动路径;在代码质量预测领域,团队利用拉取请求元数据训练了缺陷引入风险模型;此外,还有工作通过星标事件时序聚类发现了技术栈迁移规律,以及结合议题生命周期数据构建了自动分类系统,这些成果共同推动了软件仓库挖掘成为计算社会科学的重要分支。
以上内容由遇见数据集搜集并总结生成


